Формальный анализ исторических явлений
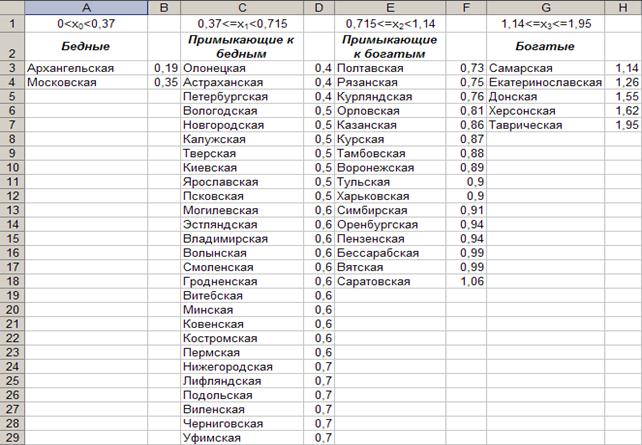
1. Цель проекта Установить, имело ли место в царской России на рубеже XIX-XX веков среди крестьянства серьёзное различие в материальном благосостояние и оказало ли оно влияние на ход революционных событий того времени, а также установить, была ли Россия капиталистическим или агарным государством на основе анализа ряда хозяйственно-экономических показателей того времени, представленных в Таблице 1. Таблица 1
Данная таблица обладает только тем свойством, что названия губерний представлены в алфавитном порядке, а данные по количеству десятин посевной земли на душу населения, количеству лошадей на десятину посева, урожайности зерновых и продуктивного скота на душу населения представлены в хаотическом виде. Из этих хаотически представленных данных невозможно установить их влияние на ход исторических процессов в Европейской части России, а также установить наличие или отсутствие взаимосвязи между ними. 2. Теоретическая часть. Известно, что историческая наука должна не только фиксировать во времени факты из жизни общества, но и устанавливать причинно – следственные связи, приводящие к тем или иным историческим явлениям. По этому поводу известный русский историк В.О. Ключевский писал так: «В ходе человеческого общежития сменялись народы и поколения, …. изменялись порядки общежития, но нить исторического развития не прерывалась, … цивилизации чередовались последовательно, как народы и поколения, рождаясь одна из другой и порождая третью, … этот сложный процесс становится главным предметом изучения во всеобщей истории, прагматически, в хронологическом порядке и последовательной связи причины и следствия …» [1]. В рамках естественного языка причинно-следственные связи представляют цепь логически не противоречивых умозаключений. Однако, если в качестве причины берутся искажённые факты реальной действительности, то результат логического умозаключения будет неверен. Очевидно, что в таких случаях исторический прогноз социальных явлений будет ошибочен. Такие ошибочные прогнозы имели место в русской истории. Так в [2] процитированы следующие мысли русского историка Роберта Виппера, высказанные в его книге «Кризис исторической науки» (1921). «Напомнив выражение Цицерона: «история – наставница жизни», Виппер пишет так: Бывают эпохи, когда хочется сказать как раз обратное: не история учит понимать и строить жизнь, а жизнь учит толковать историю. Такую историю мы сами переживаем … Наши суждения о прошлом, наши исторические мнения приходится всё время пересматривать, подвергать критике и сомнению, заменять одни положения другими, иногда обратными. История из наставницы стала ученицей жизни … Мы были участниками, частицами великого государственного дела, ныне более несуществующего. Мы притягивали историю для объяснения того, как выросло русское государство и чем оно держится. Теперь факт падения России, наукой весьма плохо предусмотренный, заставляет историков проверять свои суждения. Он властно требует объяснения: надо найти его предвестие, его глубокие причины, надо неизбежно изменить толкование исторической науки.» По поводу методов исследования исторических явлений в настоящее время там же в [2] сказано следующее. «Безусловно, методология истории не замыкается на диалектике. Методика исследований совершенствуется, привлекаются методы других наук, расширяется, например, применение количественных методов в изучении исторических явлений, сравнительного анализа и т.п.» Процесс анализа причинно – следственных связей должен основываться на количественных соотношениях, отражающих сущность исторических явлений. В таком случае указанный анализ будет беспристрастным, т.е. исключающем субъективизм того или иного исследователя. Переход к беспристрастному анализу исторических фактов связан с их формализацией, т.е. установлению количественной меры того или иного явления и последующим представлением характера явления в форме математического закона. Для иллюстрации принципа формализации исторических явлений рассмотрим ряд данных об аграрном и хозяйственном развитии 50 губерний Европейской России на рубеже XIX-XX веков (Табл. 1) Для того, чтобы установить степень и характер влияния представленных данных на ход исторических процессов в Европейской части России на рубеже XIX-XX веков, а также выявить их возможную взаимосвязь, проведём формальный анализ каждого из 4х критериев, представленных в таблице 1 по следующему алгоритму, реализацию которого продемонстрируем на критерии «посев на душу населения». Обозначим через x «посев на душу населения» и эту величину примем в качестве количественного признака губерний. Если сгруппировать губернии из таблицы 1 по числовым значениям этого признака, то после выявления общих исторических событий внутри сгруппированных указанным образом губерний можно установить влияние признака x, как причины тех или иных исторических событий. Для дальнейшего анализа необходимо весь диапазон числовых значений x разделить на определённое число интервалов и с помощью данных таблицы 1 определить количество губерний, попадающих в каждый из интервалов. В данном случае число интервалов можно выбрать равным десяти, а ширину интервала d будем определять по формуле (1), расчёт по которой в программе Excel определил d = 0, 176.
Нижние и верхние границы указанных интервалов будем вычислять так:
Причём
Введём понятие статистического числа xi как числа эквивалентного всем числам, попадающим в данный интервал, и его определим как середину выбранного интервала по следующей формуле
i = 1, 2 … 10
Вычисление частот pi попадания губерний в i -ый интервал осуществляется по формуле:
Величины xi и pi представляют ряд распределения статистической величины xi, т.е. таблицу значений этой величины и частоты pi их появления. Указанный ряд распределения характеризуется математическим ожиданием:
и средним квадратическим отклонением равным:
В случае нормального закона распределения статистической величины x Величина же Описанный выше анализ можно произвести с использованием программы MS Excel. Для этого напишем программу на языке макрокоманд. Так как любая программа требует отладки, будем проводить её посредствам сравнения получающихся в процессе написания программы результатов с образцами, представленными в виде рисунков.
1. Включение компьютера и вход в систему. Параметры: - системный блок; - монитор. Результат выполнения представлен на рисунке 1. Рис. 1.
2. Запуск программы Microsoft Excel. Параметры: - рабочий стол. Результат выполнения представлен на рисунке 2.
Параметры: - лист: «Лист1». Результат выполнения представлен на рисунке 3. Рис. 3.
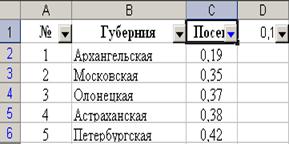
Параметры: - ячейка: A1; - данные: «№». Результат выполнения представлен на рисунке 4. Рис. 4.
Параметры: - ячейка: B1; - данные: «Губерния». Результат выполнения представлен на рисунке 5. Рис. 5.
Параметры: - ячейка: C1; - данные: «Посев». Результат выполнения представлен на рисунке 6. Рис. 6.
Параметры: - ячейка 1: «A1»; - ячейка 2: «A2»; - конечная ячейка: «A51»; - данные 1: «1»; - данные 2: «2»; Результат выполнения представлен на рисунке 7. Рис. 7.
Параметры: - ячейка: B2÷ B51; - данные: «Таблица1.Столбец2». Результат выполнения представлен на рисунке 8. Рис. 8. 9. Занесение десятичных дробей в диапазон ячеек.
- данные: « Таблица1.Столбец3 ». Результат выполнения представлен на рисунке 9. Рис. 9.
10. Активизация диапазона ячеек. Параметры: - диапазон: B2÷ C51. Результат выполнения частично представлен на рисунке 5.
Рис. 10. 11. Сортировка данных. Параметры: - диапазон: B2÷ C51; - тип: «по возрастанию»; - сортировка: «Посев». Результат выполнения частично представлен в таблице на рисунке 6.
Рис. 11.
Параметры: - ячейка: D1; - данные: «=(C51-C2)/10». Результат выполнения представлен на рисунке 7. Рис. 12.
Параметры: - лист: «Лист2». Результат выполнения представлен на рисунке 8. Рис. 13.
14. Занесение заголовка в ячейку. Параметры: - ячейка: A1, B1, C1, D1, E1, F1, G1, H1; - данные: «i», «yi», «yi+1», «xi», «ni», «pi», «xi*pi», «pi(xi -
Рис. 14.
Параметры: - ячейка 1: «A2»; - ячейка 2: «A3»; - конечная ячейка: «A11»; - данные 1: «1»; - данные 2: «2»; Результат выполнения частично представлен в таблице на рисунке 15. Рис. 15.
Параметры: - ячейка: B2; - данные: «0, 19». Результат выполнения представлен на рисунке 16. Рис. 16.
Параметры: - ячейка: « B3 »; - данные: «=$B$2+(Лист1! $D$1*Лист2! A2)»; - конечная ячейка: «B11». Результат выполнения частично представлен в таблице на рисунке 17. Рис. 17.
Параметры: - ячейка: С2; - данные: «0, 366». Результат выполнения представлен на рисунке 18. Рис. 18.
Параметры: - ячейка: « С3 »; - данные: «=$C$2+(Лист1! $D$1*Лист2! A2)»; - конечная ячейка: «C11». Результат выполнения частично представлен в таблице на рисунке 19. Рис. 19.
20. Автозаполнение – формула.
21. Специальная вставка – транспонирование. Параметры: - диапазон: «С2÷ C11»; - ячейка: « C13 ».
Рис. 21.
Параметры: - лист: «Лист1». Результат выполнения представлен на рисунке 22. Рис. 22.
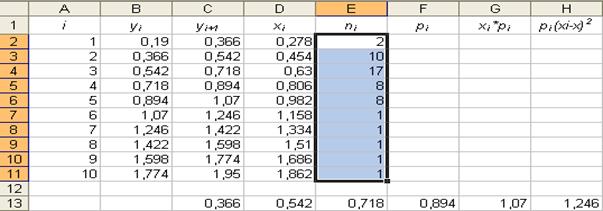
23. Автозаполнение – формула. Параметры: - ячейка: « E2 »; - данные: «=ЕСЛИ(Лист2! C$13> =Лист1! $C2; 1; 0)»; - конечная ячейка: «N51». Результат выполнения частично представлен в таблице на рисунке 23.
Рис. 23.
24. Автозаполнение – формула. Параметры: - ячейка: « E52 »; - данные: «=СУММ(E2: E51)»; - конечная ячейка: «N52». Результат выполнения частично представлен в таблице на рисунке 24.
Рис. 24.
25. Автозаполнение – формула. Параметры: - ячейка: « E53 »; - данные: «=E52-D52»; - конечная ячейка: «N53». Результат выполнения частично представлен в таблице на рисунке 25.
Рис. 25. 26. Специальная вставка – транспонирование. Параметры: - диапазон: «E53÷ N53»; - ячейка: « Лист2. E2 ». Результат выполнения представлен на рисунке 26.
Рис. 26.
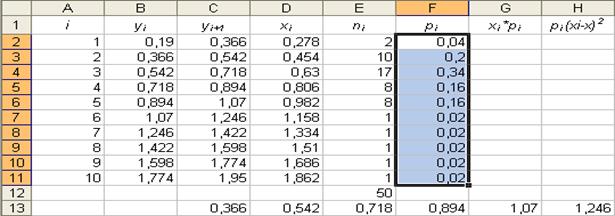
27. Занесение формул в ячейку. Параметры: - ячейка: E12; - данные: «=СУММ(E2: E11)».
28. Автозаполнение – формула. Параметры: - ячейка: « F2 »; - данные: «=E2/E$12»; - конечная ячейка: «F11». Результат выполнения частично представлен в таблице на рисунке 27.
Рис. 27.
29. Автозаполнение – формула. Параметры: - ячейка: « G2 »; - данные: «=D2*F2»; - конечная ячейка: «G11».
30. Занесение формул в ячейку. Параметры: - ячейка: G12; - данные: «=СУММ(G2: G11)». Результат выполнения частично представлен в таблице на рисунке 28.
Рис. 28.
31. Автозаполнение – формула. Параметры: - ячейка: « H2 »; - данные: «=F2*((D2-G$12)^2)»; - конечная ячейка: «H11».
32. Занесение формул в ячейку. Параметры: - ячейка: H12; - данные: «=КОРЕНЬ(СУММ(H2: H11))». Результат выполнения частично представлен в таблице на рисунке 29. Таблица 2
Рис. 29.
Из таблицы на рисунке 29 видно, что величина Столбцы D и Е (рис. 29) позволяют табличный ряд распределения статистической величины представить графически в виде так называемого многоугольника распределения. Для его построения продолжим написание программы на языке макрокоманд.
33. Построение диаграммы. Параметры: - диапазон данных: «E2: E11»; - диапазон подписей: «D2: D11»; - тип: « график »; - вид: « график с маркерами »; - название оси Х: « хi »; - название оси Y: « pi »; - название диаграммы: « Многоугольник распределения рассматриваемой случайной величины »; - размещение: «в отдельном листе » Результат выполнения представлен на рисунке 30.
Рис. 30. Многоугольник распределения рассматриваемой случайной величины.
Таким образом, получаем график (рис. 30), на котором по оси абсцисс отложена величина посева на душу в десятинах в губерниях Европейской части России, а по оси ординат – pi, относительная величина числа губерний, обладающих признаком x Величина σ представляет диапазон Чтобы продолжить анализ нам необходимо преобразовать получившиеся данные, таким образом, чтобы можно было построить график нормального ряда распределения случайной величины по Гауссу. Для этого выразим величину Pi = Pi(xi) через эквивалентную ей величину Pi = Pi(zi), где zi – суть числа натурального ряда, которые поставлены в соответствие числам xi. Таким образом, Pi = Pi(zi) – суть дискретная функция, построенная на элементах z = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10} дискретного множества. После данной перенумерации получим дискретный ряд Pi = Pi(zi), который имеет характерные свойства нормального ряда распределения случайной величины, т.е. числа Pi возрастают с ростом z до некоторого максимального значения, а потом убывают. Теперь вычислим математическое ожидание
Для сопоставления получившегося в результате преобразования ряд данных с теоретическим нормальным распределением Гаусса, вычислим для полученного рада данных критерий согласия распределений Пирсона -
где pi – частота полученного в результате преобразования ряда данных, pn – теоретическая частота каждого элемента z дискретного множества. После чего построим график, отражающий взаимосвязь распределения частот ряда данных, полученных в результате описанного выше преобразования и теоретических частот каждого элемента z дискретного множества. Для этого продолжим написание программы на языке макрокоманд и её отладки по посредствам сравнения получающихся в процессе написания программы результатов с образцами, представленными в виде рисунков.
34. Занесение заголовка в ячейку. Параметры: - ячейка: A15, B15, C15, D15, E15, F15, G15, H15, I15, J15; - данные: «zi», «xi», «pi», «xi», «pi», «zi*pi», «pi(zi -
Рис. 31.
Параметры: - ячейка 1: «A16»; - ячейка 2: «A17»; - конечная ячейка: «A25»; - данные 1: «1»; - данные 2: «2»; Результат выполнения частично представлен на рисунке 32. Рис. 32.
Параметры: - диапазон ячеек 1: D2: D11; - диапазон ячеек 2: F2: F11. Результат выполнения представлен в таблице на рисунке 33. Рис. 33.
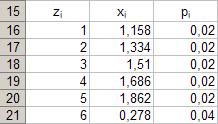
37. Специальная вставка – значение. Параметры: - ячейка: B16. Результат выполнения частично представлен на рисунке 30. Рис. 30.
Параметры: - диапазон: B16÷ C25; - тип: «по возрастанию»; - сортировка: «pi». Результат выполнения частично представлен рисунке 31. РРис. 31.
Параметры: - диапазон ячеек: B17÷ С17. Результат выполнения представлен в таблице на рисунке 32. Рис. 32. 40. Копирование в буфер обмена. Параметры: - ячейка-источник: «B17÷ С17»; - ячейка-цель: «В16».
Аналогичным образом выполним шаги 39 и 40 для нечётных диапазонов ячеек начиная с диапазона B24÷ C24 вплоть до диапазона B16÷ C16. Вставку из буфера обмена следует производить последовательно в ячейки с D21 по D25. Результат выполнения представлен в таблице на рисунке 33.
41. Автозаполнение – формула. Параметры: - ячейка: « F16 »; - данные: «=A16*E16»; - конечная ячейка: «F25».
42. Занесение формул в ячейку. Параметры: - ячейка: F26; - данные: «=СУММ(F16: F25)». Результат выполнения пунктов 41-42 частично представлен в таблице на рисунке 34. Рис. 34. 43. Автозаполнение – формула. Параметры: - ячейка: « G16 »; - данные: «=E16*(A16-$F$26)^2»; - конечная ячейка: «G25».
44. Занесение формул в ячейку.
Рис. 35. 45. Занесение формул в ячейку.
Параметры: - ячейка: K15, L15; - данные: «pn», «x2». Результат выполнения представлен на рисунке 37. Рис. 37. 47. Автозаполнение – формула. Параметры: - ячейка: « K16 »; - данные: «=НОРМРАСП(A16; F$26; G$26; 0)»; - конечная ячейка: «K25».
48. Автозаполнение – формула. Параметры: - ячейка: « L16 »; - данные: «=((E16-K16)^2)/K16»; - конечная ячейка: «L25».
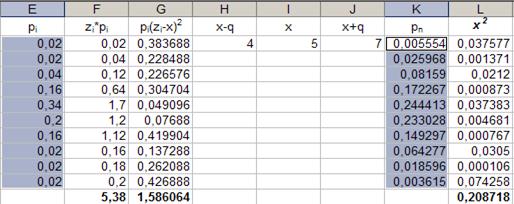
49. Занесение формул в ячейку. Параметры: - ячейка: L26; - данные: «=СУММ(L16: L25)». Результат выполнения шагов 47-49 представлен в таблице на рисунке 38. Таблица 3
Рис. 38.
50. Активизация несвязанного диапазона ячеек. Параметры: - диапазон ячеек 1: E16: E25; - диапазон ячеек 2: K16: K25. Результат выполнения представлен в таблице на рисунке 39.
Рис. 39.
51. Построение диаграммы. Параметры: - диапазон данных: « E16: E25; K16: K25 »; - тип: « график »; - вид: « график с маркерами »; - название оси Х: « zi »; - название оси Y: « pi »; - название диаграммы: « Многоугольник распределения рассматриваемой случайной величины Pi = Pi(zi)»; - размещение: «в отдельном листе » Результат выполнения представлен на рисунке 40.
Рис. 40. Многоугольник распределения случайной величины Pi = Pi(zi)
В результате проведенных вычислений получим ряд распределения Pi = Pi(zi), который, в данном случае, определён на дискретной числовой оси z, поэтому чтобы полученные числовые параметры данного ряда распределения откладывать на числовой оси zi их необходимо округлить, т.е. считать По данным таблицы 3 построим многоугольник распределения слечайной величины zi, а на числовой оси отложим числовые параметры Из многоугольника распределения случайной величины на рисунке 42 видно, что в указанный интервал попадают точки zi = 4, zi = 5, zi = 6 и zi = 7. Дискретная функция zi = zi(xi) определена в таблице 2. Из неё следует, что zi = 4 соответствует значению xi = 0, 982, которое, согласно таблице 2 определяет диапазон посева на душу населения от 0, 894 до 1, 07; zi = 5 соответствует значению xi = 0, 63, которое определяет диапазон посева на душу населения от 0, 542 до 0, 718; zi = 6 соответствует значению xi = 0, 454, определяет диапазон посева на душу населения от 0, 366 до 0, 542; zi = 7 соответствует значению xi = 0, 806, определяет диапазон посева на душу населения от 0, 718 до 0, 894. Аналогично определим значения xi, соответствующие точкам zi, не вошедшим в указанный выше интервал, а также соответствующие им диапазоны посева на душу населения. Программа Excel позволяет для указанных интервалов величины x из таблицы 1 выбрать названия губерний. Для этого в программе Microsoft Excel существует функция фильтрации с использованием автофильтра. Воспользуемся автофильтром для проведения фильтрации. В качестве первого и второго условий фильтрации будем принимать значения указанных выше интервалов. Для проведения фильтрации напишем соответствующую программу на языке макрокоманд.
Параметры: - лист: «Лист1». Результат выполнения представлен на рисунке 43. Рис. 41.
51. Активизация ячейки. Параметры: - ячейка: C1.
52. Активизация автофильтра. Результат выполнения представлен на рисунке 42.
Рис. 42.
53. Фильтрация с помощью автофильтра.
54. Копирование в буфер обмена Параметры: - ячейка-источник: «B÷ B»; - ячейка-цель: «Лист3.A2».
Параметры: - лист: «Лист1». Результат выполнения представлен на рисунке 44. Рис. 44.
Аналогично, повторим выполнение макрокоманд 54-55 для остальных указанных выше интервалов. Скопированные в буфер обмена данные будем вставлять из буфера обмена в ячейки B2, C2 и D2 соответственно на «Лист 3». Результат представлен в таблице на рисунке 45.
Рис. 45. 56. Сохранение файла в сетевую папку. Параметры: - сетевая папка: «//Public»; - имя файла: «Посев на душу населения.xls».
Для реализации целей проекта целесообразно разделить выполнение описанного выше алгоритма на отдельные этапы, которые будем называть блоками. В рамках каждого блока проекта будет проводиться анализ одного из перечисленных критериев, представленных в Таблице 1, причём, каждый блок будет выполняться независимо от других. Выполнение каждого блока будет проводиться автором, согласно Таблице 3. Каждый автор будет выполнять один блок проекта, после чего, полученные в результате выполнения каждым автором данные, могут быть объединены и использованы совместно, для формирования сводной таблицы отражающей результаты проекта в целом и реализацию его целей. Таблица 3
|
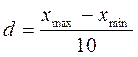 (1)
(1) , j = 0, 1, 2 … 9 (2)
, j = 0, 1, 2 … 9 (2)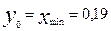 , а
, а 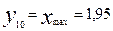
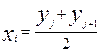 , j = 0, 1, 2 … 9; (3)
, j = 0, 1, 2 … 9; (3)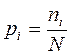 (4)
(4)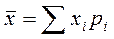 (5)
(5)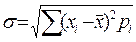 (6)
(6) величина
величина 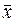 расположена посередине всего интервала изменения числовых значений x
расположена посередине всего интервала изменения числовых значений x  есть в тоже время и наиболее вероятная величина.
есть в тоже время и наиболее вероятная величина.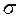 определяет меру рассеяния величин x
определяет меру рассеяния величин x 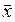 . Кривая нормального закона обладает таким свойством, что для нее мера рассеяния определяется двумя точками на числовой оси, определяемыми как
. Кривая нормального закона обладает таким свойством, что для нее мера рассеяния определяется двумя точками на числовой оси, определяемыми как  .
.
 3. Выбор активного листа.
3. Выбор активного листа.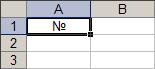 4. Занесение заголовка в ячейку.
4. Занесение заголовка в ячейку. 5. Занесение заголовка в ячейку.
5. Занесение заголовка в ячейку. 6. Занесение заголовка в ячейку.
6. Занесение заголовка в ячейку.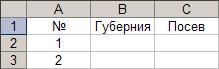 7. Автозаполнение - нумерация.
7. Автозаполнение - нумерация. 8. Занесение заголовка в ячейку.
8. Занесение заголовка в ячейку. Параметры: - диапазон ячеек: С2¸ С51;
Параметры: - диапазон ячеек: С2¸ С51;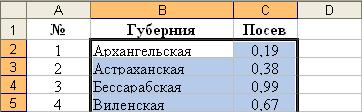
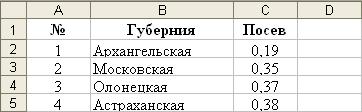
 12. Занесение формул в ячейку.
12. Занесение формул в ячейку. 13. Выбор активного листа.
13. Выбор активного листа.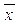 )2». Результат выполнения представлен на рисунке 9.
)2». Результат выполнения представлен на рисунке 9.
 15. Автозаполнение - нумерация.
15. Автозаполнение - нумерация. 16. Занесение десятичных дробей в ячейку.
16. Занесение десятичных дробей в ячейку.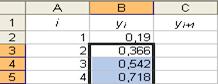 17. Автозаполнение – формула.
17. Автозаполнение – формула. 18. Занесение десятичных дробей в ячейку.
18. Занесение десятичных дробей в ячейку.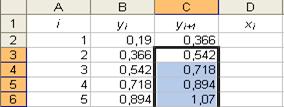 19. Автозаполнение – формула.
19. Автозаполнение – формула.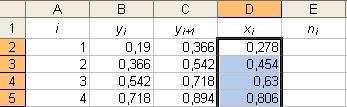 Параметры: - ячейка: « D2 »; - данные: «=(B2+C2)/2»; - конечная ячейка: «D11». Результат выполнения частично представлен в таблице на рисунке 20. Рис. 20.
Параметры: - ячейка: « D2 »; - данные: «=(B2+C2)/2»; - конечная ячейка: «D11». Результат выполнения частично представлен в таблице на рисунке 20. Рис. 20. Результат выполнения представлен на рисунке 21.
Результат выполнения представлен на рисунке 21. 22. Выбор активного листа.
22. Выбор активного листа.



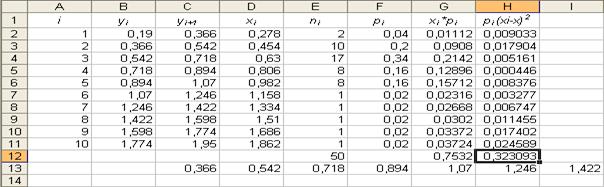
 оказалась равной 0, 7532 (ячейка G12), а
оказалась равной 0, 7532 (ячейка G12), а  - 0, 3230 (ячейка H12).
- 0, 3230 (ячейка H12).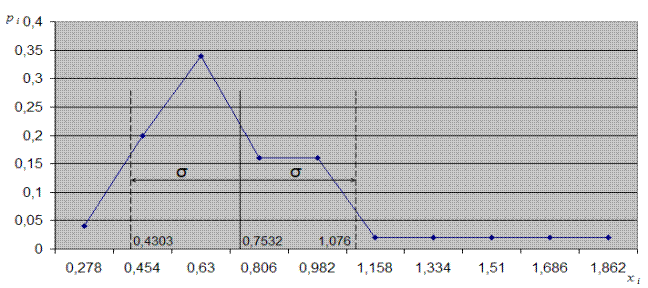
 , который определяет характер поведения частоты Pi в окрестности. Из многоугольника распределения статистической величины xi можно увидеть, что получившийся график не является примером нормального распределения статистической величины по Гауссу.
, который определяет характер поведения частоты Pi в окрестности. Из многоугольника распределения статистической величины xi можно увидеть, что получившийся график не является примером нормального распределения статистической величины по Гауссу. и среднее квадратичное отклонение σ 1 по следующим формулам
и среднее квадратичное отклонение σ 1 по следующим формулам (7)
(7)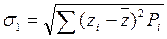 (8)
(8)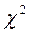 по формуле
по формуле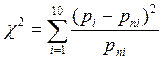 , (9)
, (9)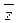 )2», «x-q», «x» «x+q». Результат выполнения представлен на рисунке 31.
)2», «x-q», «x» «x+q». Результат выполнения представлен на рисунке 31.
 35. Автозаполнение - нумерация.
35. Автозаполнение - нумерация.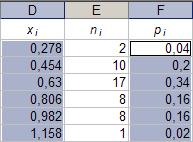 36. Активизация несвязанного диапазона ячеек.
36. Активизация несвязанного диапазона ячеек.
 38. Сортировка данных.
38. Сортировка данных.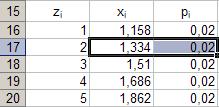 39. Активизация диапазона ячеек.
39. Активизация диапазона ячеек.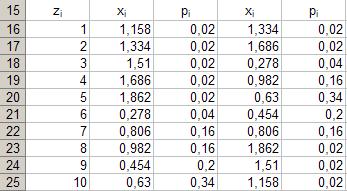 Последовательно повторим выполнение пунктов 39 и 40 для всех оставшихся чётных диапазонов ячеек вплоть до диапазона B25÷ C25. Вставку из буфера обмена следует производить последовательно в ячейки с D17 по D20. Рис. 33.
Последовательно повторим выполнение пунктов 39 и 40 для всех оставшихся чётных диапазонов ячеек вплоть до диапазона B25÷ C25. Вставку из буфера обмена следует производить последовательно в ячейки с D17 по D20. Рис. 33.
 Параметры: - ячейка: G26; - данные: «=КОРЕНЬ(СУММ(G16: G25))». Результат выполнения пунктов 56-58 частично представлен в таблице на рисунке 35.
Параметры: - ячейка: G26; - данные: «=КОРЕНЬ(СУММ(G16: G25))». Результат выполнения пунктов 56-58 частично представлен в таблице на рисунке 35. Параметры: - ячейка: H16; - данные: «=ОКРУГЛ(F26-G26; 0)»; - ячейка: I16; - данные: «=ОКРУГЛ(F26; 0)»; - ячейка: J16; - данные: «=ОКРУГЛ(F26+G26; 0)». Результат выполнения представлен на рисунке 36. Рис. 36.
Параметры: - ячейка: H16; - данные: «=ОКРУГЛ(F26-G26; 0)»; - ячейка: I16; - данные: «=ОКРУГЛ(F26; 0)»; - ячейка: J16; - данные: «=ОКРУГЛ(F26+G26; 0)». Результат выполнения представлен на рисунке 36. Рис. 36.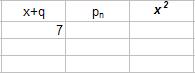 46. Занесение заголовков в ячейку.
46. Занесение заголовков в ячейку.

 = 5, σ 1 = 4, σ 2 = 7.
= 5, σ 1 = 4, σ 2 = 7.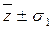 , который характеризует рассеяние случайной величины zi = zi(xi) от относительной максимальной частоты.
, который характеризует рассеяние случайной величины zi = zi(xi) от относительной максимальной частоты.
 Параметры: - столбец: C; - первое условие: «значение больше или равно»; - значение: 0, 894; - второе условие: «значение меньше»; - значение: 1, 07. Результат выполнения представлен в таблице на рисунке 45. Рис. 43.
Параметры: - столбец: C; - первое условие: «значение больше или равно»; - значение: 0, 894; - второе условие: «значение меньше»; - значение: 1, 07. Результат выполнения представлен в таблице на рисунке 45. Рис. 43. 55. Выбор активного листа.
55. Выбор активного листа.