
WORD-FORMATION
10.1. The morphological structure of English words. 10.2. Definition of word-formation. Synchronic and diachronic approaches to word formation. 10.3. Main units of word-formation. Derivational analysis. 10.4. Ways of word-formation. 10.5. Functional approach to word-formation. 10.6. The communicative aspect of word-formation.
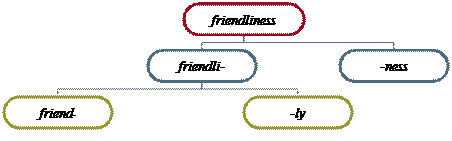
10.1. Structurally, words are divisible into smaller units which are called morphemes. Morphemes are the smallest indivisible two-facet (significant) units. A morpheme exists only as a constituent part of the word. One morpheme may have different phonemic shapes, i.e. it is represented by allomorphs (its variants), e.g. in please, pleasure, pleasant [pli: z], [ple3-], [plez-] are allomorphs of one morpheme. Semantically, all morphemes are classified into roots and affixes. The root is the lexical centre of the word, its basic part; it has an individual lexical meaning, e.g. in help, helper, helpful, helpless, helping, unhelpful - help- is the root. Affixes are used to build stems; they are classified into prefixes and suffixes; there are also infixes. A prefix precedes the root, a suffix follows it; an infix is inserted in the body of the word, e.g. prefixes: re -think, mis -take, dis -cover, over -eat, ex -wife; suffixes: danger- ous, familiar- ize, kind- ness, swea- ty etc. Structurally, morphemes fall into: free morphemes, bound morphemes, semi-bound (semi-free) morphemes. A free morpheme is one that coincides with a stem or a word-form. A great many root-morphemes are free, e.g. in friendship the root -friend - is free as it coincides with a word-form of the noun friend. A bound morpheme occurs only as a part of a word. All affixes are bound morphemes because they always make part of a word, e.g. in friendship the suffix -ship is a bound morpheme. Some root morphemes are also bound as they always occur in combination with other roots and/or affixes, e.g. in conceive, receive, perceive - ceive - is a bound root. To this group belong so-called combining forms, root morphemes of Greek and Latin origin, e.g. tele -, mega, - logy, micro -, - phone: telephone, microphone, telegraph, etc. Semi-bound morphemes are those that can function both as a free root morpheme and as an affix (sometimes with a change of sound form and/or meaning), e.g. proof, a. " giving or having protection against smth harmful or unwanted" (a free root morpheme): proof against weather; -proof (in adjectives) " treated or made so as not to be harmed by or so as to give protection against" (a semi-bound morpheme): bulletproof, ovenproof, dustproof, etc. Morphemic analysis aims at determining the morphemic (morphological) structure of a word, i.e. the aim is to split the word into morphemes and state their number, types and the pattern of arrangement. The basic unit of morphemic analysis is the morpheme. In segmenting words into morphemes, we use the method of Immediate and Unltimate Constituents. At each stage of the analysis, a word is broken down into two meaningful parts (ICs, i.e. Immediate Constituents). At the next stage, each IC is broken down into two smaller meaningful elements. The analysis is completed when we get indivisible constituents, i.e. Ultimate Constituents, or morphs, which represent morphemes in concrete words,
e.g.
Friend-, -ly, -ness are indivisible into smaller meaningful units, so they are Ultimate Constituents (morphs) and the word friendliness consists of 3 morphemes: friend-+-li+-ness. There are two structural types of words at the morphemic level of analysis: monomorphic (non-segmentable, indivisible) and polymorphic words (segmentable, divisible). The former consist only of a root morpheme, e.g. cat, give, soon, blue, oh, three. The latter consist of two or more morphemes, e.g. disagreeableness is a polymorphic word which consists of four morphemes, one root and three affixes: dis- + -agree- + -able + -ness. The morphemic structure is Pr + R + Sf1 + Sf2. 10.2. Word-Formation (W-F) is building words from available linguistic material after certain structural and semantic patterns. It is also a branch of lexicology that studies the process of building words as well as the derivative structure of words, the patterns on which they are built and derivational relations between words. Synchronically, linguists study the system of W-F at a given time; diachronically, they are concerned with the history of W-F, and the history of building concrete words. The results of the synchronic and the diachronic analysis may not always coincide, e.g. historically, to beg was derived from beggar, but synchronically the noun beggar is considered derived from the verb after the pattern v + -er/-ar → N, as the noun is structurally and semantically more complex. Cf. also: peddle- ← -pedlar/peddler, lie ← liar.
10.3. The aim of derivational analysis is to determine the derivational structure of a word, i.e. to state the derivational pattern after which it is built and the derivational base (the source of derivation). Traditionally, the basic units of derivational analysis are: the derived word (the derivative), the derivational base, the derivational pattern, the derivational affix. The derivational base is the source of a derived word, i.e. a stem, a word-form, a word-group (sometimes even a sentence) which motivates the derivative semantically and on which the latter is based structurally, e.g. in dutifully the base is dutiful-, which is a stem; in unsmiling it is the word-form smiling (participle I); in blue-eyed it is the word-group blue eye. In affixation, derivational affixes are added to derivational bases to build new words, i.e. derivatives. They repattern the bases, changing them structurally and semantically. They also mark derivational relations between words, e.g. in encouragement en- and -ment are derivational affixes: a prefix and a suffix; they are used to build the word encouragement: (en- + courage) + -ment. They also mark the derivational relations between courage and encourage, encourage and encouragement. A derivational pattern is a scheme (a formula) describing the structure of derived words already existing in the language and after which new words may be built, e.g. the pattern of friendliness is a+ -ness- → N, i.e. an adjective stem + the noun-forming suffix -ness. Derivationally, all words fall into two classes: simple (non-derived) words and derivatives. Simple words are those that are non-motivated semantically and independent of other linguistic units structurally, e.g. boy, run, quiet, receive, etc. Derived words are motivated structurally and semantically by other linguistic units, e.g. to spam, spamming, spammer, anti-spamming are motivated by spam. Each derived word is characterized by a certain derivational structure. In traditional linguistics, the derivational structure is viewed as a binary entity, reflecting the relationship between derivational bases and derivatives and consisting of a stem and a derivational affix,
e.g. the structure of nationalization is nationaliz- + -ation (described by the formula, or pattern v + -ation → N). But there is a different point of view. In modern W-F, the derivational structure of a word is defined as a finite set of derivational steps necessary to produce (build) the derived word, e.g. [(nation + -al) + - ize ] + -ation. To describe derivational structures and derivational relations, it is convenient to use the relator language and a system of oriented graphs. In this language, a word is generated by joining relators to the amorphous root O. Thus, R1O describes the structure of a simple verb (cut, permiate); R2O shows the structure of a simple noun (friend, nation); R3O is a simple adjective (small, gregarious) and R4O is a simple adverb (then, late). e.g. The derivational structure of nationalization is described by the R-formula R2R1R3R2O; the R-formula of unemployment is R2R2R1O (employ → employment → unemployment). In oriented graphs, a branch slanting left and down " /" correspond to R1; a vertical branch " I" corresponds to R2; a branch slanting right and down " \" to R3, and a horizontal right branch to R4.
and dutifulness like this:
Words whose derivational structures can be described by one R-formula are called monostructural, e.g. dutifulness, encouragement; words whose derivational structures can be described by two (or more) R-formulas are polystructural, e.g. disagreement R2R2R1O / R2R1R1O (agree → disagree → disagreement R2R1R1O or agree → agreement → disagreement R2R2R1O) There are complex units of word-formation. They are derivational clusters and derivational sets. A derivational cluster is a group of words that have the same root and are derivationally related. The structure of a cluster can be shown with the help of a graph,
reread read misreadreaderreadable reading readership ∙ unreadable A derivational set is a group of words that are built after the same derivational pattern, e.g. n + -ish → A: mulish, dollish, apish, bookish, wolfish, etc, Table TWO TYPES OF STRUCTURAL ANALYSIS
10.4. Traditionally, the following ways of W-F are distinguished: affixation, compounding, conversion, shortening, blending, back-formation. Sound interchange, sound imitation, distinctive stress, lexicalization, coinage certainly do not belong to word-formation as no derivational patterns are used. Affixation is formation of words by adding derivational affixes to derivational bases. Affixation is devided into prefixation and suffixation, e.g. the following prefixes and suffixes are used to build words with negative or opposite meanings: un-, non-, a-, contra-, counter-, de-, dis-, in-, mis-, -less, e.g. non-toxic. Compounding is building words by combining two (or more) derivational bases (stems or word-forms), e.g. big -ticket (= expensive), fifty-fifty, laid-back, statesman. Among compounds, we distinguish derivational compounds, formed by adding a derivational affix (usu. a suffix) to a word group, e.g. heart-shaped (= shaped like a heart), stone-cutter (= one who cuts stone). Conversion consists in making a word from some existing word by transferring it into another part of speech. The new word acquires a new paradigm; the sound form and the morphimic composition remain unchanged. The most productive conversion patterns are n → V (i.e. formation of verbs from noun-stems), v → N (formation of nouns from verb stems), a → V (formation of verbs from adjective stems), e.g. a drink, a do, a go, a swim: Have another try. to face, to nose, to paper, to mother, to ape; to cool, to pale, to rough, to black, to yellow, etc. Nouns and verbs can be converted from other parts of speech, too, for example, adverbs: to down, to out, to up; ifs and buts. Shortening consists in substituting a part for a whole. Shortening may result in building new lexical items (i.e. lexical shortenings) and so-called graphic abbreviations, which are not words but signs representing words in written speech; in reading, they are substituted by the words they stand for, e.g. Dr = doctor, St = street, saint, Oct = 0ctober, etc. Lexical shortenings are produced in two ways: (1) clipping, i.e. a new word is made from a syllable (or two syllables) of the original word, e.g. back-clippings: pro ← professional, chimp ← chimpanzee, fore-clippings: copter ← helicopter, gator ← alligator, fore-and-aft clippings: duct ← deduction, tec ← detective, (2) abbreviation, i.e. a new word is made from the initial letters of the original word or word-group. Abbreviations are devided into letter-based initialisms (FBI ← the Federal Bureau of Investigation) and acronyms pronounced as root words (AIDS, NATO). Blending is building new words, called blends, fusions, telescopic words, or portmanteau words, by merging (usu.irregular) fragments of two existing words, e.g. biopic ← biography + picture, alcoholiday ← alcohol + holiday. Back-formation is derivation of new words by subtracting a real or supposed affix (usu. a suffix) from existing words (on analogy with existing derivational pairs), e.g. to enthuse ← enthusiasm, to intuit ← intuition. Sound interchange and distinctive stress are not ways of word-formation. They are ways of distinguishing words or word forms, e.g. food -feed, speech - speak, life - live; ' insult, n. - in ' sult, v., ' perfect, a. - per ' fect, v. Sound interchange may be combined with affixation and/or the shift of stress, e.g. strong - strength, wide - width. 10.5. Productivity and activity of derivational ways and means. Productivity and activity in W-F are close but not identical. By productivity of derivational ways/types/patterns/means we mean ability to derive new words, e.g. The suffix -er/ the pattern v + -er → N is highly productive. By activity we mean the number of words derived with the help of a certain derivational means or after a derivational pattern, e.g. - er is found in hundreds of words so it is active. Sometimes productivity and activity go together, but they may not always do.
In modern English, the most productive way of W-P is affixation (suffixation more so than prefixation), then comes compounding, shortening takes third place, with conversion coming fourth. Productivity may change historically. Some derivational means / patterns may be non-productive for centuries or decades, then become productive, then decline again, e.g. In the late 19th c. US -ine was a popular feminine suffix on the analogy of heroine, forming such words as actorine, doctorine, speakerine. It is not productive or active now.
|

 Thus we can show the derivational structure of unemployment like this:
Thus we can show the derivational structure of unemployment like this: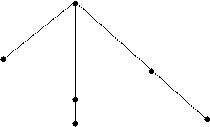 e.g. READ
e.g. READ


