Коллективный обменУчастниками коллективного обмена являются более двух процессов. Широковещательная рассылка int MPI_Bcast(void *buffer, int count, MPI_Datatype datatype, int root, MPI_Comm comm) MPI_BCAST(BUFFER, COUNT, DATATYPE, ROOT, COMM, IERR) Параметры этой процедуры одновременно являются входными и выходными: · buffer - адрес буфера; · count - количество элементов данных в сообщении; · datatype - тип данных MPI; · root - ранг главного процесса, выполняющего широковещательную рассылку; · comm - коммуникатор. Схема распределения данных представлена на рис. 3.4.
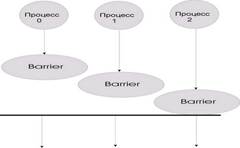
Синхронизация с помощью "барьера" (рис. 3.5) int MPI_Barrier(MPI_Comm comm) MPI_BARRIER(COMM, IERR)
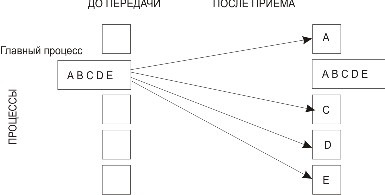
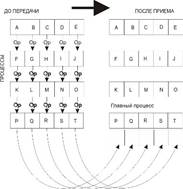
При синхронизации с барьером выполнение каждого процесса из данного коммуникатора приостанавливается до тех пор, пока все процессы не выполнят вызов процедуры синхронизации MPI_Barrier. Распределение данных int MPI_Scatter(void *sendbuf, int sendcount, MPI_Datatype sendtype, void *rcvbuf, int rcvcount, MPI_Datatype rcvtype, int root, MPI_Comm comm) MPI_SCATTER(SENDBUF,SENDCOUNT, SENDTYPE, RCVBUF, RCVCOUNT, RCVTYPE, ROOT, COMM, IERR) Входные параметры: · sendbuf - адрес буфера передачи; · sendcount - количество элементов, пересылаемых каждому процессу (но не суммарное количество пересылаемых элементов); · sendtype - тип передаваемых данных; · rcvcount - количество элементов в буфере приема; · rcvtype - тип принимаемых данных; · root - ранг передающего процесса; · comm - коммуникатор. Выходной параметр: · rcvbuf - адрес буфера приема. Процесс с рангом root распределяет содержимое буфера передачи sendbuf среди всех процессов (рис. 3.6). Содержимое буфера передачи разбивается на несколько фрагментов, каждый из которых содержит sendcount элементов. Первый фрагмент передается процессу 0, второй процессу 1 и т. д. Аргументы send имеют значение только на стороне процесса root.
Сбор сообщений от остальных процессов в буфер главной задачи int MPI_Gather(void *sendbuf, int sendcount, MPI_Datatype sendtype, void *rcvbuf, int rcvcount, MPI_Datatype rcvtype, int root, MPI_Comm comm)
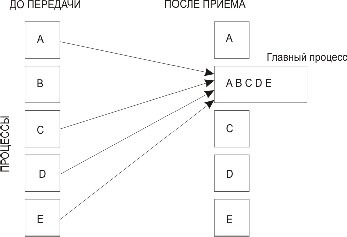
MPI_GATHER(SENDBUF, SENDCOUNT, SENDTYPE, RCVBUF, RCVCOUNT, RCVTYPE, ROOT, COMM, IERR) Каждый процесс в коммуникаторе comm пересылает содержимое буфера передачи sendbuf процессу с рангом root. Процесс root"склеивает" полученные данные в буфере приема (рис. 3.7). Порядок склейки определяется рангами процессов, то есть в результирующем наборе после данных от процесса 0 следуют данные от процесса 1, затем данные от процесса 2 и т. д. Аргументыrcvbuf, rcvcount и rcvtype играют роль только на стороне главного процесса. Аргумент rcvcount указывает количество элементов данных, полученных от каждого процесса (но не суммарное их количество). При вызове подпрограмм MPI_Scatter иMPI_Gather из разных процессов следует использовать общий главный процесс.
Векторная подпрограмма распределения данных int MPI_Scatterv(void *sendbuf, int *sendcounts, int *displs, MPI_Datatype sendtype, void *rcvbuf, int rcvcount, MPI_Datatype rcvtype, int root, MPI_Comm comm)
MPI_SCATTERV(SENDBUF, SENDCOUNTS, DISPLS, SENDTYPE, RCVBUF, RCVCOUNT, RCVTYPE, ROOT, COMM, IERR) Входные параметры: · sendbuf - адрес буфера передачи; · sendcounts - целочисленный одномерный массив, содержащий количество элементов, передаваемых каждому процессу (индекс равен рангу адресата). Его длина равна количеству процессов в коммуникаторе; · displs - целочисленный массив, длина которого равна количеству процессов в коммуникаторе. Элемент с индексом i задает смещение относительно начала буфера передачи. Ранг адресата равен значению индекса i; · sendtype - тип данных в буфере передачи; · rcvcount - количество элементов в буфере приема; · rcvtype - тип данных в буфере приема; · root - ранг передающего процесса; · comm - коммуникатор. Выходной параметр: · rcvbuf - адрес буфера приема. Сбор данных от всех процессов в заданном коммуникаторе и запись их в буфер приема с указанным смещением int MPI_Gatherv(void *sendbuf, int sendcount, MPI_Datatype sendtype, void *recvbuf, int *recvcounts, int *displs, MPI_Datatype recvtype, int root, MPI_Comm comm)
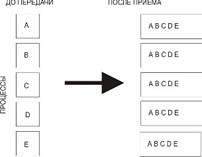
MPI_GATHERV(SENDBUF, SENDCOUNT, SENDTYPE, RECVBUF, RECVCOUNTS, DISPLS, RECVTYPE, ROOT, COMM, IERR) Список параметров у этой подпрограммы похож на список параметров подпрограммы MPI_Scatterv. В обменах, выполняемых подпрограммами MPI_Allgather и MPI_Alltoall, нет главного процесса. Детали отправки и приема важны для всех процессов, участвующих в обмене. Сбор данных от всех процессов и распределение их всем процессам int MPI_Allgather(void *sendbuf, int sendcount, MPI_Datatype sendtype, void *rcvbuf, int rcvcount, MPI_Datatype rcvtype, MPI_Comm comm)
MPI_ALLGATHER(SENDBUF, SENDCOUNT, SENDTYPE, RCVBUF, RCVCOUNT, RCVTYPE, COMM, IERR) Входные параметры: · sendbuf - начальный адрес буфера передачи; · sendcount - количество элементов в буфере передачи; · sendtype - тип передаваемых данных; · rcvcount - количество элементов, полученных от каждого процесса; · rcvtype - тип данных в буфере приема; · comm - коммуникатор. Выходной параметр: · rcvbuf - адрес буфера приема. Блок данных, переданный от j-го процесса, принимается каждым процессом и размещается в j-м блоке буфера приема recvbuf (рис. 3.8).
Операция приведения, результат которой передается одному процессу int MPI_Reduce(void *buf, void *result, int count, MPI_Datatype datatype, MPI_Op op, int root, MPI_Comm comm)
MPI_REDUCE(BUF, RESULT, COUNT, DATATYPE, OP, ROOT, COMM, IERR) Входные параметры: · buf - адрес буфера передачи; · count - количество элементов в буфере передачи; · datatype - тип данных в буфере передачи; · op - операция приведения; · root - ранг главного процесса; · comm - коммуникатор. MPI_Reduce применяет операцию приведения к операндам из buf, а результат каждой операции помещается в буфер результатаresult (рис. 3.9). MPI_Reduce должна вызываться всеми процессами в коммуникаторе comm, а аргументы count, datatype иop в этих вызовах должны совпадать.
OpenMP - стандарт программного интерфейса приложений для параллельных систем с общей памятью. Поддерживает языки C, C++, Фортран. Модель параллельной программы в OpenMP можно сформулировать следующим образом: · Программа состоит из последовательных и параллельных секций (рис. 2.1). · В начальный момент времени создается главная нить, выполняющая последовательные секции программы. · При входе в параллельную секцию выполняется операция fork,порождающая семейство нитей. Каждая нить имеет свой уникальный числовой идентификатор (главной нити соответствует 0). При распараллеливании циклов все параллельные нити исполняют один код. В общем случае нити могут исполнять различные фрагменты кода. · При выходе из параллельной секции выполняется операция join. Завершается выполнение всех нитей, кроме главной. OpenMP составляют следующие компоненты: · Директивы компилятора - используются для создания потоков, распределения работы между потоками и их синхронизации. Директивы включаются в исходный текст программы. · Подпрограммы библиотеки времени выполнения - используются для установки и определения атрибутов потоков. Вызовы этих подпрограмм включаются в исходный текст программы. · Переменные окружения - используются для управления поведением параллельной программы. Переменные окружения задаются для среды выполнения параллельной программы соответствующими командами (например, командами оболочки в операционных системахUNIX). Использование директив компилятора и подпрограмм библиотеки времени выполнения подчиняется правилам, которые различаются для разных языков программирования. Совокупность таких правил называется привязкой к языку. Распараллеливаемый участка кода следует поместить в параллельный блок: # pragma omp parallel [список опций] { // код } Внутри параллельного блока могут использоваться следующие специальные директивы: #pragma omp for #pragma omp sections #pragma omp single #pragma omp master #pragma omp barrier
f(условие) — параллельный блок выполняется, если заданное условие истинно; num_threads(num) — явное задание количества потоков; default(shared|none) — задает класс переменных по умолчанию (none означает, что всем переменным класс должен быть задан явно); private(список) — в каждом потоке создаются локальные копии переменных из списка (начальные значения не определены); firstprivate(список) — локальные копии, инициализируются по значению в мастер-потоке; shared(список) — общие для всех потоков переменные; reduction(оператор:список) — оператор редукции (свертки); переменные инициализируются 0 для аддитивных операций и 1 для мультипликативных.
#include <stdio.h> int main(int argc, char *argv[]) { printf("Последовательная область 1\n"); #pragma omp parallel { printf("Параллельная область\n"); } printf("Последовательная область 2\n"); } Программа напечатает строчку "Параллельная область" столько раз, сколько потоков было запущено в параллельном блоке.
|