Гайдамакин Н. А. 8 страницаSELECT... — выбрать данные из базы данных; INSERT... — добавить данные в базу данных; UPDATE... — обновить данные в базе данных; DELETE... — удалить данные; GRANT... — предоставить привилегии пользователю; REVOKE... — отменить привилегии пользователю; COMMIT... — зафиксировать текущую транзакцию; ROLLBACK... — прервать текущую транзакцию. Важное значение имеют разновидности инструкции SELECT—SELECT... INTO... (выбрать из одной или нескольких таблиц набор записей, из которого создать новую таблицу) и UNION SELECT, которая в дополнении с исходной инструкцией SELECT (SELECT... UNION SELECT...) реализует операцию объединения таблиц. Помимо предложения CONSTRAINT в SQL-инструкциях используются следующие предложения: FROM... — указывает таблицы или запросы, которые содержат поля, перечисленные в инструкции SELECT; WHERE... — определяет, какие записи из таблиц, перечисленных в предложении FROM, следует включить в результат выполнения инструкции SELECT, UPDAТЕ или DELETE; GROUP BY... — объединяет записи с одинаковыми значениями в указанном списке полей в одну запись; НАVING... — определяет, какие сгруппированные записи отображаются при использовании инструкции SELECT спредложением GROUP BY; IN... — определяет таблицы в любой внешней базе данных, с которой ядро СУБД может установить связь; ORDERBY... — сортирует записи, полученные в результате запроса, в порядке возрастания или убывания на основе значений указанного поля или полей. В качестве источника данных по предложению FROM, помимо таблиц и запросов, могут использоваться также результаты операций соединения таблиц в трех разновидностях— INNER JOIN... ON..., LEFT JOIN...ON... и RIGHT JOIN...ON... (внутреннее соединение, левое и правое внешнее соединение, соответственно*). * Особенности разновидностей операций соединения рассматриваются в п. 4.3.2.1.2.
Предикаты используются для задания способов и режимов использования записей, отбираемых на основе условий в инструкции SQL. Такими предикатами являются: ALL... — отбирает все записи, соответствующие условиям, заданным в инструкции SQL, используется по умолчанию; DISTINCT... — исключает записи, которые содержат повторяющиеся значения в выбранных полях; DISTINCTROW... — опускает данные, основанные на целиком повторяющихся записях, а не на отдельных повторяющихся полях; ТОРп... — возвращает п записей, находящихся в начале или в конце диапазона, описанного с помощью предложения ORDER BY; Выражениями в инструкциях SQL являются любые комбинации операторов, констант, значений текстовых констант, функций, имен полей, построенные по правилам математических выражений и результатом которых является конкретное, в том числе и логическое значение. Язык SQL, конечно же, с точки зрения профессиональных программистов построен довольно просто, но, вместе с тем, как уже отмечалось, надежды на то, что на нем станут общаться с базами данных пользователи-непрограммисты, не оправдались. Причина этого, вероятно, заключается в том, что, несмотря на простоту, язык SQL все же является формализованным искусственным языком, осваивание и использование которого в большинстве случаев тяготит конечных пользователей. Исследования основ и способов интерфейса человека с компьютером, эргономических и психологических основ работы с компьютерной информацией, проведенные в конце 70-х и в 80-х годах, показали, что пользователи-специалисты в конкретных предметных областях (а не в области вычислительной техники и программирования) более склонны к диалогово-визуальным формам работы с вычислительными системами и компьютерной информацией. Поэтому с конца 80-х годов в развитии СУБД наметились две тенденции: • СУБД для конечных пользователей; • СУБД для программистов (профессионалов). В СУБД для конечных пользователей имеется развитый набор диалоговых и визуально-наглядных средств работы с базой данных в виде специальных диалоговых интерфейсов и пошаговых «мастеров», которые «ведут» пользователя по пути выражения им своих потребностей в обработке данных. Например, при создании новой таблицы соответствующий «мастер» последовательно запрашивает у пользователя имя таблицы, имена, типы и другие параметры полей, индексов и т. д. При этом интерфейсная часть СУБД формирует для ядра СУБД (машины данных) соответствующую и порой весьма сложную инструкцию SQL. В профессиональных СУБД язык базы данных (SQL) дополняется элементами, присущими процедурным языкам программирования — описателями и средствами работы с различного типа переменными, операторами, функциями, процедурами и т. д. В результате формируется специализированный на работу с данными декларативно-процедурный язык высокого уровня, который встроен в СУБД (точнее надстроен над ядром СУБД). Такие языки называют «включающими» (см. рис. 2.1). На основе включающего языка разрабатываются полностью автономные прикладные информационные системы, реализующие более простой и понятный для специалистов в определенной предметной области (скажем, в бухгалтерии) интерфейс работы с информацией. С учетом этапов в развитии программных средств СУБД такие языки получили название языков четвертого поколения — 4GL (Forth Generation Language). Языки 4GL могут быть непосредственно встроены в сами СУБД, а могут существовать в виде отдельных сред программирования. В последнем случае в таких средах разрабатываются прикладные части информационных систем, реализующие только интерфейс и высокоуровневые функции по обработке данных. За низкоуровневым, как говорят, «сервисом» к данным такие прикладные системы обращаютсяк SQL-серверам, являющимися отдельными специализированными разновидностями СУБД. «Общение» между прикладными системами и SQL-серверами происходит соответственно на языке SQL. Свои языки 4GL имеют практически все развитые профессиональные СУБД—Orac/e, SyBase, Informix, Ingres, DB2, отечественная СУБД ЛИНТЕР. Распространенными отдельными средами программирования для создания информационных систем в настоящее время являются системы Visual Basic фирмы Microsoft и Delphi фирмы Borland Intemational. Кроме того, уже упоминавшиеся CASE-средства автоматизированного проектирования — PowerBuilder фирмы PowerSoft, Oracle Designer фирмы Oracle, SQLWindows фирмы Gupta и др., также, как правило, имеют свои встроенные языки 4GL. В заключение следует отметить, что в последнее время наметилась тенденция встраивания развитых языков уровня 4GL и в СУБД для конечных пользователей. В качестве примера можно привести СУБД Access фирмы Microsoft, имеющей один из наиболее развитых интерфейсов по созданию и работе с базами данных для конечных пользователей, и в то же время оснащенной встроенным языком уровня 4GL — VBA (Visual Basic for Application), являющегося диалектом языка Visual Basic. 4.2. Ввод, загрузка и редактирование данных Базы данных создаются для удовлетворения информационных потребностей пользователей. Однако для выполнения этой главной задачи базу данных необходимо не только правильно организовать и построить, но и наполнить самими данными. Как правило, эта задача требует больших затрат особенно на начальном этапе ввода информационных систем в эксплуатацию. Поэтому способам, удобству ввода и редактирования данных в СУБД всегда придавалось и придается важное значение. 4.2.1. Ввод и редактирование данных в реляционных СУБД В настоящее время можно выделить четыре основных способа ввода, загрузки и редактирования данных в современных реляционных СУБД: • непосредственный ввод и редактирование данных в табличном режиме; • ввод и редактирование данных через формы;* • ввод, загрузка и редактирование данных через запросы на изменения; • ввод данных через импорт из внешних источников. * Если формы предназначены только для ввода, просмотра и изменения данных их еще называют входными (вводными) формами.
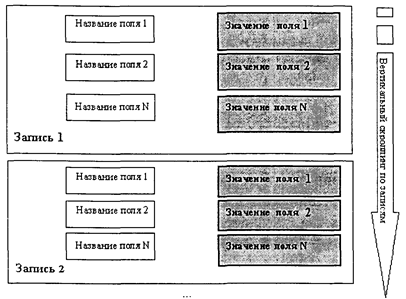
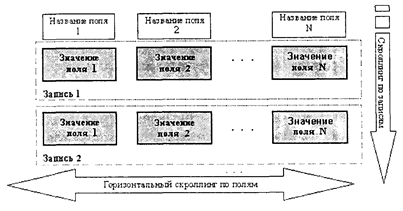
Ввод данных в табличном режиме и через формы является наиболее естественным с точки зрения табличного характера организации данных в реляционных СУБД. Как отмечалось при рассмотрении реляционной модели организации данных, единичным элементом информации, имеющим отдельное смысловое значение, является кортеж, т. е. табличная строка-запись, состоящая из дискретного набора значений по полям таблицы. Иначе говоря, данные в реляционные базы вводятся или удаляются кортежами-записями. Отображать кортежи-записи можно двумя способами, располагая поля записи вертикально или горизонтально (см. рис. 4.4 и рис. 4.5).
Рис. 4.4. Вертикальный способ расположения полей записей В первом случае пользователь «видит» и имеет доступ, как правило, сразу ко всем полям одной записи и его внимание сосредоточивается на одной записи как отдельном объекте. Записи располагаются друг за другом вертикально, и на экране компьютера обеспечивается вертикальная прокрутка (скроллинг) записей.
Рис. 4.5. Горизонтальный способ расположения полей записей Во втором способе каждая запись отображается в виде табличной строки и на экране может отображаться не одна, а несколько строк, что дает возможность пользователю производить анализ и просмотр сразу группы записей. Вместе с тем при достаточно большом количестве полей (столбцов) таблицы все они могут не уместиться на экране по горизонтальным строкам. В этом случае пользователь видит сразу не всю запись (записи), а лишь некоторый вертикальный фрагмент, и восприятие записи как отдельного объекта несколько расплывается. Для просмотра всех полей организуется их горизонтальная прокрутка. С учетом того что, как правило, ключевые поля располагаются первыми в строках-записях, при использовании горизонтальной прокрутки происходит «отрыв» ключевой информации, идентифицирующей каждую конкретную строку, от информации по другим полям записи. Таким образом, и тот и другой способ отображения записей имеет свои преимущества и недостатки. Практически все реляционные СУБД предоставляют возможность работы с данными и тем и другим способом. Реализация непосредственного ввода данных в табличном режиме или через формы осуществляется через «открытие» соответствующей таблицы базы данных. При открытии таблицы страницы файла данных, содержащие просматриваемые записи таблицы, помещаются в буферы оперативной памяти и отображаются в том или ином режиме. Непосредственный ввод и корректировка данных при этом осуществляются через использование табличного курсора, позаимствованного из технологии работы в табличных редакторах. В табличном режиме табличный курсор может свободно перемещаться по ячейкам таблицы, определяя в каждый момент так называемую текущую строку и текущую ячейку. Вводимые с клавиатуры данные автоматически помещаются в текущую ячейку, т. е. имитируется работа с таблицами в табличных редакторах. Вместе с тем по сравнению с табличными редакторами имеется все же одно принципиальное отличие. Единичным элементом ввода данных в СУБД, как уже отмечалось, является кортеж-запись, т. е. табличная строка целиком, а не отдельно взятая ячейка. Поэтому СУБД в режиме открытой таблицы явно (через специальные команды) или неявно (при перемещении табличного курсора на другую строку) осуществляет фиксацию изменений в существующей строке или фиксирует новую строку в файле базы данных, т. е. фиксирует соответствующую транзакцию. При этом проверяется соответствие введенных или откорректированных данных установленным типам полей, уникальность значений ключевых полей, выполнение других ограничений целостности данных. Если обнаруживается какое-либо несоответствие, то отвергается фиксация сразу всей строки, а не конкретной ячейки. Ввод новой записи осуществляется через активизацию в конце таблицы специальной «пустой» строки открытой таблицы. В некоторых случаях таблицы могут открываться только для ввода новых данных—так называемый режим открытия на добавление. В этом случае в открытой таблице показывается только одна «пустая» строка для ввода новых данных. Вертикальный способ отображения полей записей в современных СУБД вместе с идеями электронных бланков трансформировался в технику форм. Естественным и интуитивно-понятным способом работы со структурированной информацией для большинства «обычных»* людей являются всевозможные бланки, анкеты и т.п. «бумажные» формы. Формы в СУБД как раз и выполняют функции предоставления пользователям привычного интерфейса при вводе структурированных данных с имитацией «заполнения» бланков, анкет и т.п. * То есть в данном контексте не являющихся профессиональными программистами.
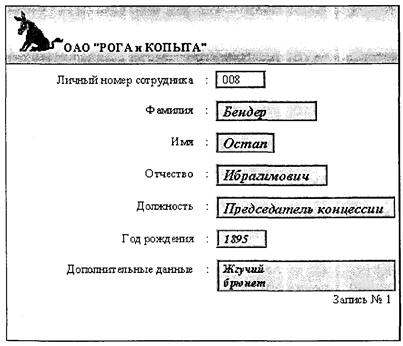
Таким образом, форма в СУБД представляет собой специальный экранный объект, включающий поля для ввода данных одной записи базовой таблицы и другую поясняющую информацию. На рис. 4.6 приведен пример формы для ввода, просмотра и изменения данных в таблице «Сотрудники» базы данных известной организации.
Рис. 4.6. Пример формы для ввода/просмотра/изменения данных Записи соответствующей таблицы через форму «прокручиваются» по вертикали. Присутствует также аналог табличного курсора, определяющий текущее поле для ввода/изменения данных. Так же как и в табличном режиме, форма может открываться только на ввод новых данных, т.е. в режиме добавления без возможности просмотра ранее введенных в таблицу данных. Форма может отображать записи или предоставлять возможность для ввода новых записей одной (базовой) таблицы. Однако идея экранных форм в реляционных СУБД оказалась более плодотворной, чем просто предоставление удобств для ввода/просмотра сразу всех полей одной записи. В определенных случаях «бумажная» информационная технология, которую автоматизирует банк данных АИС, предусматривает накопление и образование данных сразу в комплексе по ряду информационных задач. К примеру, при ведении учета командировок сотрудников в бухгалтерии используются специальные бланки, в которых отображается информация по сотруднику (ФИО, Подразделение, Должность, Сл. тел.) и данные собственно по командировке (Дата начала. Дата окончания, Полученный аванс, Фактические расходы, Пункты назначения, Служебные задания). При проектировании базы данных для автоматизации такого учета, исходя из требований нормализации таблиц, перечисленные выше в «бумажном» бланке данные распределяются сразу по нескольким связанным таблицам «Сотрудник», «Командировка», «Пункты», «Служебные задания». Техника форм СУБД предоставляет возможность создавать «комплексные» электронные бланки для ввода информации сразу в несколько связанных таблиц. Такие формы называются структурными (сложными) и обеспечивают естественный в технологическом плане совместный ввод данных в связанные таблицы. Чаще всего такой способ позволяет вводить и просматривать записи, находящиеся в таблицах, связанных отношением «Один-ко-многим». При прокрутке записей в главной форме, отражающей записи базовой таблицы на стороне «один», в структурных элементах, называемых иногда «подчиненными» формами, прокручиваются связанные записи из таблиц на стороне «многие». На рис. 4.7 приведен пример такой формы.
Рис. 4.7. Пример формы для ввода данных в таблицы, связанные отношением «Один-ко-многнм» Зачастую при создании базы данных новой АИС часть данных уже имеется в электронном виде в других, ранее созданных базах данных. Если это базы данных того же формата, т. е. созданные и функционирующие под управлением той же СУБД, или другой реляционной СУБД, поддерживающей основанный на языке SQL специальный протокол обмена данными между реляционными СУБД — ODBC* (Open Database Connectivity), то имеется возможность вводить, или, как в этом случае говорят, загружать данные из таблиц, находящихся в файлах других (внешних) баз данных. Такая загрузка реализуется на основе техники запросов на изменение данных, в качестве источников которых указываются таблицы в других БД.** * Стандартный протокол доступа к данным на серверах баз данных SQL... ** Запросы на изменения данных рассматриваются в п. 4.3.2.2.
Ряд СУБД предоставляет возможность загружать табличные данные, созданные и находящиеся под управлением не СУБД, а приложений другого типа — табличных и текстовых редакторов. В этом случае говорят об импорте данных из внешних источников. Ввод данных при этом осуществляется на основе «знания» СУБД формата внешних табличных данных и соответствующей их трансформации в структуры реляционных таблиц. Некоторые СУБД предоставляют возможность ввода в реляционные таблицы текстовых данных, размеченных специальными разделителями на последовательно расположенные дискретные порции. Каждая такая порция помещается в соответствующее поле табличной строки по принципу последовательного заполнения строк таблицы «Слева-направо, Сверху-вниз». При этом СУБД проверяет соответствие вводимых значений установленным типам полей, а также другим параметрам полей и ограничениям целостности данных. Таким образом, в современных реляционных СУБД имеется развитый арсенал возможностей по вводу и загрузке данных, который позволяет эффективно решать задачи по наполнению БД данными. 4.2.2. Особенности ввода и загрузки данных в СУБД с сетевой моделью организации данных Характерной особенностью логической и физической структуры данных в сетевых СУБД, как уже отмечалось, является хранение информации по связям между информационными объектами как отдельных самостоятельных объектов — наборов экземпляров связей. В результате более сложная, чем в реляционных СУБД структура данных, определяет использование в сетевых СУБД преимущественно нелинейных структур физической организации данных, что обеспечивает более эффективный доступ к данным, но вместе с тем вызывает повышенные затраты на изменения (добавление, удаление, редактирование) данных. Любые процессы модификации данных в большинстве случаев приводят к необходимости «перетряски» всего банка данных, что чрезвычайно замедляет ввод и редактирование данных. Поэтому вСУБД с сетевой организацией данных непосредственный ввод данных (ручной ввод с клавиатуры) чаще всего построен по принципу «стакана и емкости». Сначала данные вводятся в так называемое «входное сообщение». Специальный интерфейс в таких СУБД предоставляет пользователю возможности ввода данных во входное сообщение по аналогии с непосредственным вводом данных в реляционных СУБД — табличном режиме или в режиме форм. При этом данные физически размещаются во временном файле — стакане. Кроме того, в отличие от реляционных СУБД, пользователь может вводить данные сразу в различные (связанные) таблицы, непосредственно «переходя» по полям-отсылкам из одного объекта (таблицы) в другой. После подготовки файла входного сообщения, который размещается, так же как и файл базы данных, на внешней дисковой памяти, осуществляется загрузка входного сообщения в базу данных, т.е. «стакан» выливается в «емкость».* СУБД при этом «перетасовывает» всю базу данных, вставляя новые, изменяя месторасположение «старых» записей, модифицируя физические адреса отсылок и т.д. * Отсюда, собственно, исторически и возникли различия в понимании терминов «ввод» и «загрузка».
Дополнительной проблемой при этом является отождествление новых и старых записей. В реляционных СУБД эта проблема решается исключительно на основе уникальности значений ключевых полей. Новая запись с уже существующим значением ключевого поля в реляционных СУБД автоматически отвергается и данные по ней можно ввести только путем корректировки полей уже существующей записи с соответствующим значением ключевого поля.* * В этом, кстати, проявляется один существенный недостаток реляционных СУБД—отсутствие возможностей темпорального отображения данных, т.е. отображения данных с предысторией их изменения.
В сетевых СУБД, ввиду поддержки полей с множественным характером значений, обеспечивается «слияние» данных. При слиянии записей из входного сообщения с уже существующими записями в базе данных поля с множественным типом значений объединяются, а по полям с единичным характером значений устанавливаются дифференцированный режим замены или отвержения нового значения. 4.3. Обработка данных Обработка данных представляет собой емкое понятие, включающее широкий набор различных функций и операций по удовлетворению информационных потребностей пользователя. Тем не менее в технологическом плане этот широкий набор удобно разделить на три группы: • поиск, фильтрация и сортировка данных; • запросы к базе данных; • механизм реализации событий, правил (триггеров) и процедур в базе данных. На практике работа пользователя с базой данных может включать сразу весь комплекс операций, однако с методической точки зрения целесообразно рассмотреть их последовательно. 4.3.1. Поиск, фильтрация и сортировка данных Операции по поиску, фильтрации и сортировке данных реализуют самые простые информационно-справочные потребности пользователей, но являются, вероятно, наиболее частыми при работе с базами данных. Отличительная особенность операций по поиску, фильтрации и сортировке данных заключается в том, что они осуществляются в режиме открытой таблицы или формы. Забегая несколько вперед, следует отметить главную отличительную особенность этих операций по сравнению с запросами на выборку к базам данных — результатом операций по поиску или фильтрации данных является изменение состояния просмотра открытой таблицы (формы), но не самих данных, которые физически остаются в той же таблице и в том же порядке. Например, результатом поиска какой-либо конкретной записи в открытой таблице является установление табличного курсора на ключевое поле искомой записи-строки или «показ» (отображение) в открытой форме полей искомой записи. Собственно поиск данных реализуется в виде: • поиска записи по ее номеру; • поиска записи (записей) по значению (значениям) какого-либо поля; • поиска записей с помощью фильтров (фильтрация). Поиск записи по ее номеру производится на основе механизма распределения записей по страницам файла данных. Результатом такого поиска является перевод табличного курсора в ключевое поле соответствующей записи или «показ» в форме полей искомой записи. Поиск записи по значению поля осуществляется также на основе механизма распределения записей по страницам файла данных с использованием техники вхождения образца в значения просматриваемого поля. Результатом поиска является установка табличного курсора в соответствующее поле найденной записи. Если записей с искомым значением выделенного поля несколько, тогда, как правило, реализуется последовательная «остановка» (последовательный просмотр) табличного курсора в соответствующих полях найденных записей. Фильтр представляет собой набор условий, применяемых для отбора подмножества записей. Результатом фильтрации является «показ» (отображение) в открытой таблице или форме только отфильтрованных записей с временным «скрытием» всех остальных записей. При этом остальные записи физически никуда не перемещаются, не удаляются и вновь отображаются в открытой таблице после «снятия» фильтра. Набор условий, определяющих фильтр, формируется в различных СУБД по-разному, но общепринятым является использование выражений в условиях отбора данных. Под выражением в данном случае понимается структура, подобная обычному математическому выражению. Аргументами выражения могут быть числа, даты, текст, имена полей, которые соединяются знаками математических операций, неравенств (+, -, *, /, >, <, =) и логических операций (AND, OR, NOT). При этом текстовые значения и аргументы заключаются в кавычки («Иванов»), даты в символы # (#01.01.98#). Как отмечалось при рассмотрении реляционной модели данных, строки в таблицах формируются и хранятся в неупорядоченном виде. Вместе с тем одной из простых, но частых информационных потребностей пользователя при работе с базой данных является как раз упорядочение записей по возрастанию/убыванию или по алфавиту по определенному полю (например, по полям дат, по полям с размерами должностных окладов, по полю с фамилией сотрудников и т. п.). Такие процедуры реализуются сортировкой данных, которая упорядочивает последовательность расположения строк открытой таблицы по значениям какого-либо поля. При этом в файле базы данных строки таблицы физически остаются не упорядоченными. Иначе говоря, сортировка строк открытой таблицы происходит только в буферах страниц в оперативной памяти. Новый порядок расположения строк таблицы (т. е. их размещение по страницам файла БД) может быть зафиксирован специальной командой при закрытии таблицы. При больших объемах таблиц (при большом количестве строк-записей) операции сортировки могут занимать продолжительное время, которое существенно сокращается, если сортировка осуществляется по индексированному полю. В этом плане опыт эксплуатации базы данных может привести к уточнению списка индексированных полей в таблицах. 4.3.2. Запросы в реляционных СУБД Запросы являются наиболее распространенным видом обработки данных при решении пользователями АИС тематических, логических, статистических и технологических информационных задач. Иначе говоря, для удовлетворения сложных информационных потребностей пользователи «общаются» с базой данных через запросы. Запрос представляет собой спецификацию (предписание) на специальном языке (языке базы данных) для обработки данных. В реляционных СУБД запросы к базе данных выражаются, соответственно, на языке SQL. Формирование запросов в СУБД может осуществляться в специальном редакторе (командный режим) или через наглядно-диалоговые средства (конструкторы) и пошаговые мастера формирования запросов. Сформированный запрос в виде SQL-инструкции сохраняется в файле базы данных и впоследствии специальной командой СУБД может запускаться (открываться) на выполнение. Все многообразие запросов можно проклассифицировать схемой, приведенной на рис. 4.8. Сточки зрения решаемых информационных задач и формы результатов исполнения запросов их можно разделить на три группы: • запросы на выборку данных; • запросы на изменение данных; • управляющие запросы. 4.3.2.1. Запросы на выборку данных Запросы на выборку применяются для решения тематических, логических и статистических информационных задач и относятся к одному из наиболее часто применяемых видов запросов. Данный вид запросов реализуется SQL-инструкцией SELECT с предложением FROM. Результатом исполнения запроса на выборку является набор данных, который представляет временную таблицу данных со структурой (поля, их типы и параметры), определяемой параметрами запроса и параметрами полей таблиц, из которых выбираются данные. В отличие от режимов поиска и фильтрации запросами на выборку данные выбираются из «не открытых» таблиц базы данных. Результаты запросов на выборку помещаются в специальную временную таблицу, размещаемую на период исполнения («открытия») запроса в оперативной памяти. В этом смысле с точки зрения дальнейшей обработки данных запрос (как результат) в реляционных СУБД тождественен просто таблице данных, «открытие» которой осуществляется в результате выполнения запроса. Из этого следует возможность исполнения запросов над запросами, точнее над результатами исполнения других запросов, что существенно облегчает построение сложных запросов при решении логических и статистических информационных задач.
Рис. 4.8. Классификация запросов в реляционных СУБД В большинстве СУБД наборы данных, формируемые запросами на выборку, являются динамическими. Динамичность означает, что с результатом исполнения запроса можно производить все те же операции, что и с данными в режиме открытой таблицы. Иначе говоря, изменения данных, осуществляемые в наборе данных, сформированных по запросу, фиксируются в исходных таблицах, из которых выбираются данные, и, наоборот, — изменения данных в исходных таблицах, если они производятся в открытых таблицах после исполнения запроса, отображаются в наборе данных по результатам «открытого», т. е. исполняемого в это же время, запроса.
|