
Гайдамакин Н. А. 16 страницаКак уже отмечалось, повышению эффективности поиска способствует морфологический разбор документов и запросов. Помимо существенного уменьшения объема словаря и, соответственно, индекса системы, морфологический разбор повышает и эффективность поиска, так как не реагирует на несущественные с точки зрения смыслового содержания грамматические различия искомого текста документов и запросов. Если вернуться опять-таки к примеру с запросом «экспорт редкоземельные элементы», то система с морфологическим разбором отберет не только те документы, в которых встречается буквальное сочетание словоформ «экспорт», «редкоземельные», «элементы», но и такие фразы, как «К вопросу об экспорте редкоземельных элементов», «Проблемы экспорта редкоземельные элементов» и т.п. Морфологический разбор в принципе дает возможность пользователю формировать запросы на естественном языке. Система при обработке запроса удаляет из него все «стоп-слова», остальные словоформы нормализует и, оставляя пользователя в полной иллюзии о том, что она действительно его «понимает», выполняет таким образом выхолощенный запрос. Некоторое время тому назад наблюдалось сильное увлечение таким подходом, от которого, к счастью, вскоре разработчики полнотекстовых ИПС отошли. Использование якобы естественного языка запросов на самом деле не позволяет применять логические операторы и другие развитые возможности, связанные с координатным анализом местонахождения и контекстного окружения искомых слов, терминов, сочетаний и т. д. Еще одной важной характеристикой поиска документов по индексу, в том числе с учетом логических операций посткоординации и морфологического разбора, является то, что такой поиск основывается на упрощенном детерминированном подходе. Иначе говоря, критерием поиска является вхождение или невхождение того или иного дескриптора-словоформы запроса в поисковый образ документа без учета общей «похожести» ПОД и ПОЗ. Масса остальных дескрипторов поискового образа документа не рассматривается. Поэтому в развитых полнотекстовых ИПС реализуются более тонкие и сложные алгоритмы поиска, основанные на сравнении ПОД и ПОЗ в целом по тем или иным критериям похожести, близости. Такой подход позволяет предоставлять пользователям более эффективные возможности выражения своих информационных потребностей без их явной формализации и структуризации по словоформам. В частности, пользователь может поставить ИПС задачу поиска документов, «похожих» по содержанию на какой-либо другой (известный ему релевантный, точнее пертинентный) документ или фрагмент документа. В этом случае не только ПОД, но и ПОЗ представляют собой полномасштабные двоичные векторы, часть дескрипторов которых будет совпадать, а часть не совпадать, и возникнет необходимость в использовании более тонких критериев определения близости документов и запроса. Кроме того, становится возможным определение количественных мер (показателей) близости, т.е. релевантности документов и запросов. 6.3.3. Методы количественной оценки релевантности документов Количественные показатели релевантности — процент соответствия содержимого документа запросу, ранжирование (самый релевантный документ, менее релевантный, еще менее релевантный) и т. п., позволяют существенно увеличить конечную эффективность использования документальной системы, предоставляя пользователю возможность после отбора документов сразу сосредоточиваться на наиболее важных из них. Определение количественных показателей релевантности документов в полнотекстовых ИПС основывается на тех или иных подходах по вычислению мер близости двоичных векторов документов и запросов. Документ Dk представляется в системе двоичным вектором:
где dk,i =1, если словоформа под номером i присутствует в k- мдокументе, и 0, если отсутствует. Аналогичным образом представляются поисковые образы запроса Z пользователя:
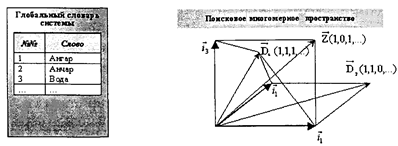
где zk = 1, если словоформа под номером k присутствует в запросе, и zk = 0, если отсутствует. Критерии релевантности подразделяются по моделям представления и сопоставления документов и запросов, к которым относятся: • булева модель; • модель нечетких множеств; • пространственно-векторная модель; • вероятностно-статистическая модель. В качестве показателя (меры) релевантности документов используется так называемое значение статуса выборки (retrieval status value — RSV). В булевой модели критерием релевантности является полное совпадение векторов ПОД и ПОЗ. Соответственно RSV в булевой модели определяется как логическая сумма операций попарного логического произведения соответствующих элементов векторов ПОД и ПОЗ:
где k = 1,..., N, N — количество документов в базе, L — количество словоформ в словаре, &—логическая операция «И». Значением RSV в булевой модели может быть единица (релевантный документ) или ноль (нерелевантный документ). По сути, булева модель не дает количественной меры релевантности и ничем не отличается от простого поиска по индексу системы с логической операцией «И» словоформ-дескрипторов. В системах наоснове модели нечетких множеств значения компонент векторов ПОД и ПОЗ могут принимать не только два альтернативных значения —1 и 0 (термин принадлежит документу или не принадлежит), но и такое значение, как «неполная, частичная принадлежность». Соответственно в модели нечетких множеств переопределены и логические операции, чтобы учитывать возможность неполной принадлежности подобных логических элементов анализируемым множествам (поисковым образам запросов). Вычисление значений статуса выборки RSV производится аналогичным булевой модели образом с учетом переопределения операции & («И»). Несмотря на некоторое расширение выразительных возможностей представления и сопоставления документов и запросов, модель нечетких множеств, как и булева модель, не дает по-настоящему количественной меры релевантности, хотя достоинством обеих моделей является их простота и невысокие вычислительные затраты на реализацию. В системах на основе пространственно-векторных моделей поисковое пространство представлено многомерным пространством, каждое измерение которого соответствует словоформе (термину) из словаря системы. Например, если в словаре всего три словоформы, то поисковое пространство является трехмерным, и т. д. В исходном варианте пространство имеет евклидову метрику, т. е. представляется ортогональным базисом нормированных векторов, отражающих соответствующие словоформы словаря системы. Поисковый образ документа и запроса в поисковом пространстве представляется многомерным вектором единичной длины, координаты которого отражают наличие или отсутствие в документе соответствующих словоформ. В случае трехмерной размерности пространственно-векторная модель иллюстрируется на рис. 6.10. Показатель релевантности (по аналогии с булевой моделью будем обозначать его RSV) для пространственно-векторной модели в простейшем случае определяется скалярным произведением векторов ПОД и ПОЗ:
Рис. 6.10. Иллюстрация пространственно-векторной модели представления и сопоставления документов и запросов Таким образом, определяемый показатель релевантности RSV может изменяться в диапазоне от 0 до N(N — число словоформ или терминов в словаре системы) и действительно количественно отражает степень релевантности документов. Так, в приведенном на рис. 6.10 примере значение RSV1 = 2, а значение RSV2 = 1. Для выдачи пользователю конкретного набора релевантных документов информационно-поисковые системы ограничиваются выдачей документов, показатель релевантности которых запросу RSV превышает некоторый заранее установленный порог. Следует также заметить, что при таком подходе абсолютные значения показателя релевантности зависят не только собственно от самой степени релевантности, но и от количества N словоформ в словаре системы. Поэтому на практике применяют нормализованный вариант RSV, определяя его с учетом ортогональности и ортонормированности поискового пространства как косинус угла между вектором ПОД и вектором ПОЗ:
В этом случае RSV принимает значения от 0 до 1 и не зависит от объема словаря системы. Определенным недостатком такого подхода к расчету количественной меры релевантности является нечувствительность к степени соответствия отсутствующих словоформ (терминов) в ПОД и ПОЗ. Интуитивно понятно, что чем ближе содержание документа и запроса, тем меньше в документе должно быть словоформ (терминов), которых нет в запросе. Если, к примеру, в словаре системы всего 6 элементов и имеется два документа Такой чувствительностью обладает показатель релевантности, определяемый следующим образом:
где Если вернуться к предыдущему примеру с документами Более развитым, но и более сложным подходом к определению мер близости ПОД и ПОЗ является учет разной значимости словоформ (терминов) и их зависимости друг от друга. В пространственно-векторной модели это означает отход от ортогональности и ортонормированности базисных векторов поискового пространства. В этом случае скалярное произведение векторов ПОД и ПОЗ более гибко и осмысленно отражает близость соответствующих векторов и, тем самым, смысловое содержание документов и запросов. В простейшем варианте подобного расширения пространственно-векторной модели различные словоформы в глобальном словаре системы дополняются специальными весовыми коэффициентами, отражающими важность соответствующей словоформы (термина) для конкретной предметной обласmu. Соответственно поисковые векторы документов и запросов в этом случае превращаются из двоичных векторов в обычные, т. е. с любыми значениями (а не только 0 или 1) своих компонент. Иногда такой подход называют «окрашиванием»* глобального словаря системы. Следует также заметить, что в случае перехода от глобального словаря (отражающего все слова и словоформы) к словарю терминов происходит вырождение полнотекстового характера ИПС и она переходит в категорию систем на основе тезаурусов. * В смысле окрашивания по определенной предметной области.
На практике применяются также и другие подходы, расширяющие возможности двоичной (ортогональной и ортонормированной) пространственно-векторной модели. Такие подходы базируются на вероятностно-статистической модели. При этом можно выделить две разновидности вероятностно-статистического подхода: • придание весовых коэффициентов словоформам (терминам) глобального словаря вне контекста конкретного документа; • придание весовых коэффициентов компонентам векторов ПОД по итогам индексирования конкретного документа (с учетом контекста конкретного документа). Первый подход основан на анализе итогов индексирования совокупности документов, уже вошедших в базу (хранилище) ИПС. Совокупность словоформ (терминов), обязательно присутствующих в любом документе базы, считается наиболее адекватно отражающей тематику предметной области ИПС, и соответствующие словоформы (термины предметной области) получают наибольший вес, наибольшую значимость в словаре системы, по которому производится индексирование документов. В качестве числовых характеристик весов значимости терминов используются те или иные статистические параметры, такие, например, как относительная или абсолютная частота вхождения термина в документы базы системы. Разновидностью такого подхода является учет количества вхождений в совокупность документов базы тех или иных словоформ или терминов. Более сложные варианты развития первого подхода основываются на технологиях «обучения» и настраивания ИПС на конкретные предметные области. Традиционный способ обучения основывается на использовании обучающей выборки документов. Такая выборка формируется либо на основе отбора текстов экспертами в конкретной предметной области, либо путем использования документов по соответствующим рубрикам каталогов библиотек и т. п. Далее осуществляется исследование обучающей выборки на предмет статистических показателей вхождений в документы выборки тех или иных словоформ или терминов. Результатом обучения является «окрашенность» (различные весовые коэффициенты словоформ) словаря системы. Другой подход основывается на апостериорном выделении в поисковом пространстве «сгущений» векторов ПОД и последующем анализе совокупности и количественных данных вхождения в такие группы документов тех или иных словоформ (терминов). Предполагается, что такие группы соответствуют особенностям тематики конкретной предметной области, и словоформы, в них входящие, получают наибольшие весовые коэффициенты на основе тех или иных статистических параметров. Еще одним вариантом является учет дискриминируемости (различимости) термина. Если при внесении в текст одного из двух близких по векторам ПОД документов какого-либо термина происходит резкое «расщепление» этих векторов, то такой термин считается более информативным и значимым, и его коэффициент важности, соответственно, должен быть выше. При втором подходе к реализации вероятностно-статистической модели различия в весах значимости словоформ или терминов проявляются по результатам индексирования конкретного документа. В простейшем варианте анализируется, сколько раз тот или иной термин входит в данный документ. Словоформам или терминам, имеющим наибольшее количество вхождений, присваиваются более высокие веса в векторе ПОД. В векторах запросов (ПОЗ) все словоформы или термины считаются равнозначными, но их различные веса в векторах ПОД обеспечивают большую релевантность тех документов, где соответствующие словоформы или термины встречаются наиболее часто. Отдельной ветвью развития второго подхода является использование обратной, интерактивной связи с пользователем. В этом случае информационно-поисковая система стремится настроиться не столько на определенную предметную область, сколько на специфические особенности тематики информационных потребностей конкретного пользователя. В общем виде для каждого пользователя ИПС создает свое поисковое пространство с индивидуальным окрашиванием компонентов векторов ПОД. Такое индивидуальное окрашивание производится путем запрашивания системой у пользователя его оценки релевантности выданных на каждый текущий запрос документов. Уточнив у пользователя, какие на его взгляд документы наиболее релевантны, система анализирует особенности и статистические параметры вхождения тех или иных словоформ (терминов) в эти наиболее релевантные документы, переопределяет и уточняет их весовые коэффициенты. Тем самым в последующих запросах более адекватно и глубже учитываются информационные потребности конкретного пользователя. Существуют и другие разновидности вероятностно-статистических подходов к расширению пространственно-векторной модели поиска документов, но, к сожалению, из-за отсутствия в документации на коммерческие ИПС соответствующей информации по деталям механизмов поиска и релевантности документов оценить и проанализировать их эффективность довольно затруднительно. В целом же информационно-поисковые полнотекстовые системы являются одним из наиболее интенсивно развивающихся направлений документальных информационных систем, существенно продвигая теорию и практику информационного поиска документов и развивая методы анализа и автоматизированной обработки текстовой неструктурированной информации. 6.4. Гипертекстовые информационно-поисковые системы Анализ организации работы различных аналитических служб и отдельно взятого аналитика показывает, что основой их информационного обеспечения в традиционных «бумажных» технологиях являются различные тематические подборки, папки с текстовыми документами (служебные документы, копии статей из специальной периодики, выписки из книг, газетные вырезки и т. п.), систематизированные по расположению на основе какого-либо критерия (в алфавитном порядке по названиям, хронологически по дате документов, ранжированием по важности или по иным критериям). Причем документы в таких папках-подборках, как правило, снабжаются еще специальными пометками и взаимными отсылками по каким-либо смысловым ассоциациям. Отталкиваясь от какого-либо одного, релевантного документа, аналитик по отсылкам отбирает из подборки и все, ассоциированные по данному смысловому содержанию, документы. Процесс отбора документов по ссылкам в определенной степени напоминает навигацию по географическим картам, чем и определяется название соответствующего подхода к организации документального поиска. В отличие от информационно-поисковых систем на основе индексирования документов, семантически-навигационные системы изначально возникли и развивались как чисто компьютерные системы и прошли пока еще короткий, но уже достаточно богатый период развития. Считается, что первым идеи ассоциативно-навигационного подхода к анализу текстовой информации выдвинул в 1945 году советник президента Рузвельта по науке Ванневар Буш. В своей статье «Как мы могли бы мыслить», где он излагал проект создания технической (точнее, (фотомеханической) системы, обеспечивающей «ассоциативное» связывание текстов, В. Буш писал: «Работа человеческой мысли построена на принципе ассоциаций. Анализируя какое-либо понятие или элемент, она непременно стремится поставить ему в соответствие какой-нибудь другой знакомый образ, подсказываемый ассоциацией мыслей, и это соответствие устанавливается благодаря трудноуловимой паутине связей, формируемых клетками человеческого мозга».* Идеи В. Буша, как это иногда бывает, намного опередили свое время, и потребовался более чем 20-летний период накопления опыта работы с компьютерной информацией, пока в 70-х годах не были предприняты первые попытки практической реализации систем с ассоциативным связыванием текстов, выразившиеся в технике так называемого гипертекста. * Цитируется по работе: Елисеев В., Ладыженский Г. Введение в Интранет / СУБД. — 1996. — № 5-6. — С. 24.
6.4.1. Гипертекст
Рис. 6.11. Принцип гипертекста Гипертекст в узком смысле представляет собой обычный текст, содержащий ссылки на другие связанные по смыслу фрагменты того же текста (документа) или на другие тексты (на внешние документы). При этом ссылки для пользователя-читателя в тексте имеют вид выделенных слов или словосочетаний, обладающих какой-либо смысловой связью с текстом того фрагмента или другого текста, куда «направляет» ссылка (так называемая гиперссылка). Программное средство, отображающее гипертекст, например текстовый редактор или броузер сети Интернет, обеспечивает отображение гипертекста и навигацию пользователя-читателя по гиперссылкам. «Щелкнув» мышью по выделенному слову (т. е. по гиперссылке), пользователь-читатель открывает связанный по ссылке текст (другой фрагмент этого же текста или другой текст). Привычным «бумажным» аналогом гипертекста являются оглавления и предметные указатели книг, содержащие ссылки на главы, разделы или фрагменты книги с соответствующей информацией. При этом ссылка выглядит как номер страницы, с которой начинается соответствующая глава или раздел, где находится соответствующий фрагмент текста. Отобрав в оглавлении или предметном указателе нужное название или термин и считав номер соответствующей страницы, читатель открывает книгу в искомом месте, т. е. переходит, или, выражаясь по-другому, осуществляет «навигацию» в нужное место книги. В 70-е и 80-е годы, в особенности в период «персонализации» вычислительной техники, были предприняты многочисленные попытки создания специальных гипертекстовых оболочек, на основе которых либо совершенствовался примитивный текстово-командный интерфейс ранних операционных систем (знаменитая оболочка «Norton Commander» для ОС MS DOS), либо для прикладных программных средств создавались гипертекстовые справочные (help-овые) системы и руководства. В конце 80-х — начале 90-х годов были предприняты первые попытки стандартизации гипертекста. Таким стандартом являлся стандарт American Cybernetics Hypertext System (ACI Hypertext), реализованный в среде встроенной системы макрокоманд широко известного в «узких» программистских кругах текстового редактора MultiEdit. Впоследствии гипертекст стал широко использоваться в справочных системах программ-приложений операционной системы Windows и фирмой MicroSoft был разработан специальный пакет WinHelp для создания гипертекстовых справочных «систем помощи». В настоящее время техника гипертекста является фактическим стандартом создания разнообразных компьютерных справочных и учебных систем, руководств пользователя и энциклопедий. Период взрывной интенсификации применения технологий гипертекста связан с бурным развитием и распространением в конце 80-х — начале 90-х годов глобальных информационных систем, и, в частности, сети Интернет. Идеи гипертекста как принципа ассоциативного связывания в распределенную информационную среду документов на территориально удаленных компьютерах были использованы группой специалистов под руководством Теодора Нельсона, который в 1988 г. представил проект гипертекстовой системы Хаnаdu, финансировавшийся впоследствии основателем известной компании Autodesk Джоном Уокером, который в то время пророчески предвещал всеобъемлющее развитие и распространение гипертекстовых технологий. В 1989 г. в Лаборатории физики элементарных частиц европейского центра ядерных исследований (ЦЕРН) под руководством Тима Бернерса-Ли стартовал проект создания гипертекстовой системы обмена научными данными в сети Интернет, получивший впоследствии название «Всемирной паутины» — World-Wide Web (WWW). В 90-х годах паутина WWW стала одним из наиболее бурно развивающихся сегментов сети Интернет, создав немыслимую ранее глобальную гипертекстовую информационную инфраструктуру. 6.4.2. Структура, принципы построения и использования гипертекстовых ИПС В структуре гипертекстовой ИПС можно выделить несколько функциональных подсистем (см. рис. 6.12). Основными из них являются: • подсистема отображения документов и гиперссылок; • подсистема навигации по связям (гиперссылкам); • подсистема формирования связей (гиперссылок); • и собственно сама гипертекстовая база (хранилище) документов.
Рис. 6.12. Структура гипертекстовой ИПС Подсистема отображения документов и гиперссылок (гипертекста) базируется на принципах отображения документов в текстовых редакторах (страницы, поля, абзацы, шрифт, скроллинг и т. д.) с дополнительными приемами внешнего отображения в тексте гиперссылок. Как уже отмечалось, стандартным способом отображения гиперссылок является выделение в тексте специальным фоном, цветом или шрифтом ключевых слов, имеющих определенную смысловую связь с тем фрагментом или документом, на который указывает ссылка. В развитых гипертекстовых системах, как, например, в системе WWW, в гипертексте могут отображаться также графика (рисунки, диаграммы), звуковые и даже видеоанимационные элементы, что в совокупности создает мультимедииную технологию работы с информацией. В этом случае в качестве гиперссылок могут также выступать и специальные изображения, значки, иконки, что дает возможность использования для отображения связей различных графических ассоциаций. В остальном подсистема отображения гипертекста напоминает обычный текстовый редактор, допуская стандартные операции просмотра (скроллинг, масштаб) и обработки текста (копирование, контекстный поиск и т. д.). Подсистема навигации по связям реализует специальный интерфейс перехода по гиперссылкам. Если гиперссылка указывает на другой фрагмент того же документа, то подсистема навигации обеспечивает скроллинг (прокрутку) отображения текста к соответствующему фрагменту. Если гиперссылка указывает на внешний документ, то стандартным приемом для систем, реализованных в оконно-графических операционных средах (MS Windows), является открытие в новом окне соответствующего документа. Приемом инициализации перехода по гиперссылке обычно является «щелчок мышью» по ключевому слову или графическому значку, обозначающему соответствующую гиперссылку, либо перевод текстового курсора на соответствующую гиперссылку и нажатие клавиши «Enter». Для осуществления навигации в гипертекстовом документе для каждой гиперссылки хранится адрес расположения соответствующего документа или фрагмента. В современных гипертекстовых средах для удобства ориентирования пользователя применяется специальный прием «подсказки» адреса гиперссылки при осуществлении подготовительных операций перед ее активизацией (т. е. при переводе курсора мыши или текстового курсора на гиперссылку непосредственно перед щелчком или нажатием клавиши «Enter»). Навигация по гиперссылкам формирует для пользователя определенный сюжетно-тематический поток по цепочке ассоциаций. Нетривиальной проблемой, как и при навигации в банках фактографических систем с сетевой моделью организации данных, является способ отображения и визуализации цепочек «пройденных» документов. Так как такие цепочки документов могут быть неопределенно длинными, то открытие и отображение каждого следующего по проходу документа в дополнительном окне приводят к быстрому заполнению, а потом и наслоению окон с документами на экране компьютера. При этом документ, на который указывает гиперссылка из другого документа, может помимо непосредственной ассоциации включать и совершенно иной содержательный контекст, что быстро «уводит» пользователя от основной темы и дезориентирует его. Поэтому в большинстве систем используется только одно окно для отображения документов, а при переходе по гиперссылке к связанному документу происходит «выталкивание» предыдущего документа в специальный неотображаемый стек для пройденных документов. Дополнительно обеспечивается свободная навигация по сформированной таким образом цепочке документов (по пройденному пути) по принципу «Вперед-Назад», что позволяет пользователю путем возвращений назад или перемещений вперед лучше анализировать сюжетно-тематическии поток ассоциаций. Способ формирования и отображения цепочки пройденных документов по линейному принципу «Вперед-Назад» не всегда адекватно позволяет представить схему сюжетно-тематического потока документов из-за наличия возможных ветвлений в таких цепочках. Если из какого-либо документа (узла цепочки) имеется несколько гиперссылок на различные документы, то сценарием «разговора» пользователя с гипертекстовой базой может быть «спуск» от такого документа по имеющимся ветвям на определенную глубину, с последующим возвратом (подъемом) и спуском по другим ветвям. Линейно-списочный способ отображения цепочек пройденных документов в этом случае из-за многочисленных возвратов не дает общего представления и взгляда на ассоциативную окрестность связанных документов (см. рис. 6.13).
|




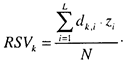
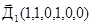 и
и  , то для запроса
, то для запроса 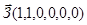 значение RSV для обоих документов будет равно 2 (33%), хотя интуитивно понятно, что более близким по содержанию является первый документ, а второй документ, скорее всего, затрагивает более широкую тематику, не обязательно интересующую пользователя.
значение RSV для обоих документов будет равно 2 (33%), хотя интуитивно понятно, что более близким по содержанию является первый документ, а второй документ, скорее всего, затрагивает более широкую тематику, не обязательно интересующую пользователя.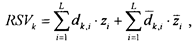
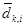 и
и 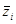 — дополнение к элементам
— дополнение к элементам 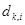 и
и  , т. е.
, т. е. 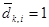 , если
, если 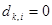 и наоборот.
и наоборот.




