
Реализация. Определим размер MAX массива m и объявим сам массив m.
#include <stdio.h> #include <memory.h> #define MAX 101
int i,j,n,k; int m[MAX][MAX];
Обнулим массив m. Проведем инициализацию, положив f(i, 1) = f(0, i) = 1 (0 £ i < MAX). Заметим, что f(n, k) = f(n, k – 1) + (f(n – 1, k – 1) + f(n – 2, k – 1) + … f(1, k – 1) + f(0, k – 1)) = f(n, k – 1) + f(n – 1, k) Таким образом, значение m[ i ][ j ] можно пересчитать как сумму m[ i ][ j – 1] и m[ i – 1][ j ], взятую по модулю 1000000.
void main(void) { memset(m,0,sizeof(m)); for(i=0;i<MAX;i++) m[1][i] = m[i][0] = 1; for(i=2;i<MAX;i++) for(j=1;j<MAX;j++) m[i][j] = (m[i][j-1] + m[i-1][j]) % 1000000;
Для каждой входной пары чисел n и k выводим результат, хранящийся в ячейке m[ k, n ].
while(scanf("%d %d",&n,&k),n+k>0) printf("%d\n",m[k][n]); }
11. Задача группирования [Вальядолид, 11026]. Пусть а 1, a 2, …, an – заданные n чисел. Обозначим через F ik (i ³ k) сумму всех возможных произведений по k чисел, взятых среди первых i чисел a 1, …, ai. Построим следующую таблицу F ik:
Имеют место следующие рекуррентные соотношения: F i 1 = F(i -1)1 + ai, F ii = F(i -1) (i -1) * ai, 1 £ i £ n F ik = F(i -1) k + F(i -1) (k -1) * ai, 1 £ i £ n, 1 < k < i Значения каждой следующей строки пересчитываются через значения предыдущей строки, поэтому в памяти достаточно хранить один линейный массив d размера 1000. При этом пересчет значений i - ой строки следует начинать с конца: сначала вычислить F ii, потом F i (i -1) и так далее до F i 1. Все вычисления следует проводить по модулю m. Пример. Рассмотрим первый тест. Построим две таблицы: вычисления во второй будут производиться по модулю m = 10, а в первой – нет.
Ответом является максимальное число в четвертой строке второй таблицы. Реализация. Объявим линейный массив d, в котором будут пересчитываться значения F ik.
#include <stdio.h> #include <memory.h>
long long n,m,i,j; long long num,res,d[1000];
void main(void) {
Вводим количество чисел n и значение m. Для каждого входного теста изначально обнуляем массив d. Первое число a 1 заносим в d[0].
while(scanf("%lld %lld",&n,&m),n+m>0) { memset(d,0,sizeof(d)); scanf("%lld",&d[0]);
Вводим значение num = ai +1 (1 £ i < n) и пересчитываем значения F ik, k = i, i – 1, …, 1 по выше приведенным рекуррентным формулам. Все вычисления проводим по модулю m.
for(i=1;i<n;i++) { scanf("%lld",&num); d[i] = (d[i-1] * num) % m; for(j=i-1;j>0;j--) d[j] = (d[j-1]*num+d[j]) % m; d[0] = (d[0] + num) % m; }
Находим максимальное значение среди элементов массива d и заносим его в переменную res. Выводим результат.
res = d[0]; for(i=1;i<n;i++) if (d[i] > res) res = d[i]; printf("%lld\n",res); } }
12. Подсчет общих подпоследовательностей [Топкодер, раунд 298, дивизион 1, уровень 3]. В ячейке f[ i ][ j ][ k ] будем хранить количество общих подпоследовательностей строк a 1 a 2… ai, b 1 b 2… bj и c 1 c 2… ck., где ai = bj = ck. Если для тройки (i, j, k) последнее равенство не выполняется, то полагаем f[ i ][ j ][ k ] = 0. Если i = 0, то считаем, что строка a пустая. Аналогично при j = 0 (k = 0) считаем, что строка b (c) пустая. Положим f[0][0][0] = 1, считая, что общей подпоследовательностью трех пустых строк является пустая строка. Искомое количество общих подпоследовательностей трех строк a, b и c равно
где l, m, n – длины соответственно строк a, b и c. Вычисление значений f[ i ][ j ][ k ] совершаем следующим образом. Перебираем все возможные значения троек (i, j, k) и для каждого значения f[ i ][ j ][ k ], большего нуля (ai = bj = ck) перебираем все буквы латинского алфавита и для каждой буквы ищем ее появление во всех строках в позициях, больших соответственно i, j и k. Пусть такими позициями будут x, y и z. Добавляем к f[ x +1][ y +1][ z +1] значение f[ i ][ j ][ k ] (индексы сдвинуты на 1, так как нумерация массивов в Си начинается с нуля, а индексу 0 в массиве f соответствует пустая строка).
Пусть a = b = c = “abc”. Тогда f[0][0][0] = 1, общая подпоследовательность (“”, “”, “”). f[1][1][1] = 1, общая подпоследовательность (“a”, “a”, “a”). f[2][2][2] = 2, общие подпоследовательности (“b”, “b”, “b”), (“ab”, “ab”, “ab”). f[3][3][3] = 4, общие подпоследовательности (“c”, “c”, “c”), (“bc”, “bc”, “bc”), (“ac”, “ac”, “ac”), (“abc”, “abc”, “abc”). Остальные значения f[ i ][ j ][ k ] равны нулю. Количество общих подпоследовательностей равно 1 + 2 + 4 = 7.
#include <cstdio> #include <string> #define i64 long long using namespace std;
i64 f[51][51][51],res;
class CountingCommonSubsequences { public: i64 countCommonSubsequences(string a, string b, string c) { int i,j,k,x,y,z; f[0][0][0] = 1; res = 0; for(i=0;i<=a.size();i++) for(j=0;j<=b.size();j++) for(k=0;k<=c.size();k++) if (f[i][j][k] > 0) { for(char ch = 'a'; ch <= 'z';ch++) { x = a.find(ch,i); y = b.find(ch,j); z = c.find(ch,k); if (x!= string::npos && y!= string::npos && z!= string::npos) f[x+1][y+1][z+1] += f[i][j][k]; } res += f[i][j][k]; } return res-1; } }; 13. Исправить расстановку скобок [Топкодер, раунд 301, дивизион 2, уровень 3]. Обозначим через f(i, j) наименьшее количество символов, которое можно изменить так, чтобы подстрока sisi +1… sj -1 sj стала правильной. Тогда имеют место соотношения: 1. f(i, j) = 0 при i > j, так как в таком случае подстрока будет пустой строкой. 2. f(i, j) = f(i + 1, j – 1) + enc(si, sj). Делаем так, чтобы символ si был открывающейся скобкой, а sj – соответствующий ему закрывающейся скобкой. Далее рекурсивно рассматриваем подстроку si +1… sj -1. Функция enc(si, sj) возвращает: а) 0, если символы si и sj являются соответствующими открывающейся и закрывающейся скобками; б) 2, если символ si является закрывающейся скобкой, а sj – открывающейся; в) 1 иначе. В этом случае достаточно изменить один из символов si или sj так, чтобы они образовали правильную скобочную пару; 3. f(i, j) = В ячейках m[ i ][ j ] массива m сохраняем значения f(i, j). Ответом задачи будет f(0, | s | – 1), где s – входная строка.
#include <cstdio> #include <string> #include <memory> #define min(i,j) (i<j)?i:j using namespace std;
int m[51][51]; string s;
int enc(char c, char d) { string p="([{)]}"; if (p.find(c)/3>0 && p.find(d)/3<1) return 2; if (p.find(c)%3==p.find(d)%3 && c!=d) return 0; return 1; }
int f(int i, int j) { if (i>j) return 0; if (m[i][j]>=0) return m[i][j]; int r = f(i+1,j-1) + enc(s[i],s[j]); for(int k=i+1;k<j;k+=2) r = min(r,f(i,k) + f(k+1,j)); return m[i][j]=r; }
class CorrectingParenthesization { public: int getMinErrors(string s) { ::s = s; memset(m,-1,sizeof(m)); return f(0,s.size()-1); } };
14. Просуммировать всех [Топкодер, раунд 311, дивизион 1, уровень 2]. Пусть функция f(x) вычисляет сумму цифр всех чисел от 0 до x. Тогда ответом задачи будет значение f(upperBound) – f(lowerBound – 1). Заведем массив dp[10][11], в котором dp[ i ][ j ] равно сумме цифр всех j - значных чисел, первая цифра которых равна i. Изначально положим dp[ i ][0] = 0. Ячейка dp[0][ j ] содержит сумму цифр всех чисел, содержащих менее j цифр, то есть сумму цифр всех (j – 1) - значных чисел, начинающихся с любой цифры включая ноль: dp[0][ j ] = Любое j - значное число, первая цифра которого равна i, образуется из (j – 1) - значного числа приписыванием впереди цифры i. Поэтому сумма их цифр равна сумме цифр (j – 1) - значных чисел плюс цифра i, умноженная на количество j - значных чисел с первой цифрой i (количество последних равно 10 j -1). Получаем соотношение: dp[ i ][ j ] = dp[0][ j ] + 10 j -1 * i Остается описать вычисление функции f(x). Очевидно, что f(0) = 0. Пусть x = 1. Числа от 0 до 2. Числа от Таким образом f(x) = Функция info(x, * len, * FirstDigit, * Rest) по входному значению x возвращает количество знаков в числе len, первую цифру числа FirstDigit и число Rest, полученное зачеркиванием первой цифры в числе x.
#include <stdio.h> #define i64 __int64
i64 dp[10][11]; int digits[10];
void info(int x,int *len,int *FirstDigit,int *Rest) { int pow10 = *len = 1;*Rest = 0; while(x > 9) { (*len)++; *Rest = *Rest+(x%10)*pow10; x /= 10; pow10 *= 10; } *FirstDigit = x; }
i64 f(int x) { int i,len,FirstDigit,Rest; i64 res; if (!x) return 0; info(x,&len,&FirstDigit,&Rest); for(res=i=0;i<FirstDigit;i++) res += dp[i][len]; return res + FirstDigit*(Rest+1) + f(Rest); }
class SumThemAll { public: i64 getSum(int lowerBound, int upperBound) { int i,j,k; for (i = 0;i<10;i++) dp[i][0] = 0; for (k=j=1;j<11;j++) { dp[0][j] = 0; for (i = 0; i < 10; i++) dp[0][j] += dp[i][j - 1]; for (i = 0; i < 10; i++) dp[i][j] = dp[0][j] + k * i; k *= 10; } return f(upperBound) - f(lowerBound-1); } };
Рекурсивная реализация. Рассмотрим рекурсивную реализацию функции f(x). Суммирование цифр чисел от 0 до x = 1. суммирование цифр чисел от 0 до 2. суммирование цифр чисел от Рассмотрим первое множество чисел. На последней позиции повторяется последовательность из чисел 0, 1, …, 9 x / 10 раз. Сумма цифр от 0 до 9 равна 45, поэтому сумма единиц в числах первого множества равна x / 10 * 45. Сумма цифр, стоящих на других местах, равна 10 * f(x / 10 – 1). Сумма цифр в числах второго множества состоит из суммы цифр единиц (0 + 1 + … + a 0) и суммы цифр числа (temp + 1) * sum(x / 10) + temp * (temp + 1) / 2
#include <stdio.h> #define i64 __int64
int sum (int x) { return (!x)? 0: x%10 + sum(x/10); }
i64 f(i64 x) { if (x<=0) return 0; i64 res = x / 10 * 45; i64 temp = x % 10; res = res + 10*f(x/10-1) + (temp+1)*sum(x/10) + temp*(temp+1)/2; return res; }
class SumThemAll { public: i64 getSum(int lowerBound, int upperBound) { return f(upperBound) - f(lowerBound-1); } };
15. Забор для травы [Топкодер, раунд 314, дивизион 2, уровень 3; дивизион 1, уровень 2]. Площадь треугольника со сторонами a, b, c ищем в функции area(a, b, c) по формуле Герона: S = Пусть P – некоторое подмножество имеющихся кусков забора. Функция FindSol(mask) будет находить максимальную площадь, которую можно оградить при помощи них треугольными формами. Переменная mask содержит маску подмножества: она является 16-битовым числом, i -ый бит которого равен 1, если подмножество P содержит кусок fences[ i ], и 0 иначе. Ответом на задачу в таком случае будет значение FindSol(2 n - 1), где n – количество чисел в массиве fences. Значения всевозможных масок mask лежит в промежутке от 0 до 216 – 1 (по условию имеются не более 16 кусков забора). В ячейке best[ mask ] храним максимальную площадь, которую можно оградить подмножеством кусков изгороди, описывающим маской mask. Для вычисления FindSol(mask) следует перебрать все возможные тройки кусков забора i, j, k, присутствующих в mask, проверить для них неравенство треугольника (можно ли из них составить треугольник) и найти сумму area(fences[ i ], fences[ j ], fences[ k ]) + FindSol(mask \ { i, j, k }). Перебираем все тройки (i, j, k) и находим такую, для которой указанная сумма максимальна. Ее значение присваиваем ячейке best[ mask ]. Извлечение из подмножеста mask i – го элемента эквивалентно выполнению операции исключающего или: mask ^ (1 << i). Если изначально длины кусков забора отсортировать, то при проверке неравенства треугольника (стороны которого равны fences[ i ], fences[ j ], fences[ k ]), достаточно проверить только одно условие: fences[ i ] + fences[ j ] > fences[ k ], так как из неравенства fences[ i ] £ fences[ j ] £ fences[ k ] всегда сдедует, что fences[ i ] + fences[ k ] > fences[ j ] и fences[ j ] + fences[ k ] > fences[ i ].
#include <cstdio> #include <cmath> #include <vector> #include <algorithm> using namespace std;
double best[1<<16]; int n;
class GrasslandFencer{ public: vector<int> f;
double FindSol(int mask) { int i,j,k; double mx = 0; if (best[mask] >= 0.0) return best[mask]; if (!mask) return 0; for(i=0;i<n-2;i++) if (mask & (1<<i)) for(j=i+1;j<n-1;j++) if (mask & (1<<j)) for(k=j+1;k<n;k++) if (mask & (1<<k)) if (f[i] + f[j] > f[k]) mx = max(mx,area(f[i],f[j], f[k])+ FindSol(mask ^ (1 << i) ^ (1 << j) ^ (1 << k))); best[mask] = mx; return mx; }
double area(int a, int b, int c) { double p = (a+b+c)/2.0; return sqrt(p*(p-a)*(p-b)*(p-c)); }
double maximalFencedArea(vector<int> fences) { sort(fences.begin(),fences.end()); n = fences.size(); f = fences; memset(best,-1,sizeof(best)); return FindSol((1<<n)-1); } };
16. Починка забора [Топкодер, раунд 325, дивизион 1, уровень 1]. Исходя из ограничений на массив boards и на длины его элементов, заключаем, что длина наибольшего возможного входного забора не более 50*50 = 2500. Объединим строки массива boards в b. Заведем массив c длины 2501, в котором c[ i ] будет хранить минимальную стоимость, за которую можно починить забор от нулевой позиции до (i – 1) - ой, причем c[0] положим равным 0. Тогда дешевле всего починить первые i секции (от 0 - ой до (i – 1) - ой) забора следующим образом: 1. Если i - ая секция цела (b[ i – 1] = ‘.’), то достаточно починить только первые i – 1 секций: c[ i ] = c[ i – 1]; 2. Если i - ая секция сломана (b[ i – 1] = ‘X’), то чиним забор от 0 - ой до j - ой секции (0 £ j < i), потратив c[ j ] денег, а затем чиним доски от (j + 1) - ой до i - ой секции за Положив c[0] = 0, последовательно вычисляем c[1], c[2], …, c[ n ], где n – длина забора. Ответом задачи будет значение c[ n ].
#include <cstdio> #include <vector> #include <string> #include <cmath> #include <numeric> #define min(i,j) (i < j)? i: j using namespace std;
class FenceRepairing { public: double calculateCost(vector<string> boards) { string b = accumulate(boards.begin(),boards.end(),string()); int i, j; double c[2501]; for(c[0] = 0, i = 1; i <= b.size(); i++) { c[i] = 2000000000; if (b[i-1] == '.') c[i] = c[i-1]; else for(j = 0; j < i; j++) c[i] = min(c[i],c[j] + sqrt(1.0 * i - j)); } return c[b.size()]; } };
17. Расширенное счастливое число [Топкодер, раунд 334, дивизион 2, уровень 3; дивизион 1, уровень 2]. Поскольку значение k в процессе вычислений фиксировано, заведем массив powk, в котором powk[ i ] = ik. Им будет удобно пользоваться при вычислении значений S k (n) в функции sum(n). Наибольшее значение, которое могут принимать элементы последовательности n, S k (n), S k (S k (n)), …, не больше 4*106, так как даже при k = 6 значение S6(n) при n < 4*106 не больше 36 + 6*96 = 3189375 < 4*106. Заведем массив f[4000000], в котором будем хранить f[ i ] = S k (i). Рассмотрим для некоторого i последовательность a 0 = i, a 1 = S k (i), a 2 = S k (S k (n)), …. Очевидно, что найдутся такие индексы s и t (пусть s < t для определенности), что as = at. Тогда f[ ak ], (0 £ k £ t) положим равным минимуму среди чисел ak, ak +1, …, at. При этом начиная вычислять значение f[ a 0], в процессе мы находим все значения f[ ak ], 0 £ k £ t. Описанную процедуру совершаем в функции g. Значение f[ i ] считается вычисленным, если f[ i ] > 0. При первом проходе по числам a 0, …, at устанавливаем f[ ai ] = -1. Дойдя до at = as, продолжаем путь as, as +1, …, at, устанавливая f[ ai ] = ai для s £ i £ t. Когда вторично дойдем до f[ at ], значение этой ячейки уже будет положительным и рекурсия начнет раскручиваться назад. Двигаясь назад по кольцу дважды от at до as, а потом и до a 0, устанавливаем f[ ai ] в наименьшее значение среди чисел ai, ai +1, …, at.
#include <stdio.h> #define i64 long long #define MAX 4000000
int powk[10]; int f[MAX],ptr;
int min(int i, int j) { return (i < j)? i: j; }
int sum(int n) { int s; for(s=0;n;n/=10) s += powk[n % 10]; return s; }
int g(int n) { if (f[n] > 0) return f[n]; else if (f[n] == 0) f[n] = -1; else if (f[n] == -1) f[n] = n; return f[n] = min(n,g(sum(n))); }
class ExtendedHappyNumbers { public: i64 calcTheSum(int a, int b, int k) { int i,j,s; i64 res=0; for(i=0;i<10;i++) { for(s=1,j=0;j<k;j++) s *= i; powk[i] = s; } for(i=a;i<=b;i++) res += g(i); return res; } };
18. Быстрый почтальон [Топкодер, раунд 346, дивизион 2, уровень 3]. Если почтальон на своем пути поравняется с некоторым домом, куда следует доставить письмо, то его следует отдавать сразу же, при первом же подходе к дому. Если почтальон уже разнес письма в i - ый и j - ый дома, то он точно уже разнес письма во все дома, которые находятся между i - ым и j - ым домом. Таким образом, множество домов, куда уже разнесена почта, представляет собой отрезок прямой с точкой initialPos внутри. Следует также отметить, что направление движения почтальон может менять только в точке с домом, в который он только что доставил письмо. Состояние почтальона определим тройкой чисел: 1. левый конец интервала домов, куда уже разнесена почта; 2. правый конец интервала домов, куда уже разнесена почта; 3. текущее положение почтальона; Вместо самих чисел в состоянии почтальона лучше хранить их индексы в массиве address. На каждом шаге (i, j, k) следует определить, куда лучше двигаться почтальону: вправо (i, j + 1, j + 1) или влево (i – 1, j, i – 1). Также заметим, что для каждого состояния (i, j, k) текущее положение почтальона k равно i или j. В ячейках sol[ i ][ j ][0] будем хранить наименьшее время, за которое почтальон разнесет все письма в дома в интервале (i, j), причем находиться будет в точке i (в левом конце интервала). Соответственно в sol[ i ][ j ][1] будет содержаться та же информация, только почтальон будет находиться в правом конце интервала – в точке j. Отсортируем адреса домов по возрастанию их координат. Чтобы при сортировке соответствующим образом переставлялось и граничное время доставки, создадим вектор пар houses, первый элемент которого содержит адрес дома, а второй – максимальное время доставки письма в этот дом. При сортировке вектора пар по возрастанию сортировка производится по первой компоненте – то есть по расстоянию от левого края улицы. Инициализация массива sol: sol[ i ][ i ][0] = sol[ i ][ i ][1] = | address[ i ] – initialPos | = | houses[ i ].first – initialPos | Для доставки письма в единственный дом, индекс которого равен i, необходимо затратить время, равное расстоянию от начального положения initialPos до местоположения дома address[ i ]. Рассмотрим интервал (i, j). Почтальон может оказаться в его левом конце двигаясь либо с левого конца интервала (i + 1, j), либо с правого конца интервала (i + 1, j). В первом случае ему требуется пройти расстояние address[ i + 1] – address[ i ], во втором address[ j ] – address[ i ]. То есть sol[ i ][ j ][0] = = min(sol[ i + 1][ j ][0] + address[ i + 1] – address[ i ], sol[ i + 1][ j ][1] + address[ j ] – address[ i ]) Аналогично почтальон может оказаться в правом конце итервала (i, j), если он будет двигаться либо с левого конца интервала (i, j – 1), либо с правого конца интервала (i, j – 1). В первом случае ему требуется пройти расстояние address[ j ] – address[ i ], во втором address[ j ] – address[ j – 1]. Таким образом sol[ i ][ j ][1] = = min(sol[ i ][ j – 1][0] + address[ j ] – address[ i ], sol[ i ][ j – 1][1] + address[ j ] – address[ j – 1]) Если на каком-нибудь этапе вычисления значение sol[ i ][ j ][0] (или sol[ i ][ j ][1]) станет большим maxTime[ i ] (или соответственно maxTime[ j ]), то установим его равным плюс бесконечности (значению INF = 2000000000). Последнее означает тот факт, что добраться до соответствующего дома в отведенное время почтальон не может. Почтальон доставит все письма, когда будут пройдены все дома из интервала (0, n – 1), где n – количество домов. При этом нам не важно, в каком из концов этого интервала закончит путь почтальон. То есть ответом будет значение min(sol[0][ n – 1 ][0], sol[0][ n – 1][1]) Если это значение равно плюс бесконечности, то разнести письма в срок не удастся и следует вернуть -1 как требуется в условии задачи.
#include <cstdio> #include <vector> #include <memory> #include <algorithm> #define INF 2000000000 using namespace std;
int sol[50][50][2];
int min(int i, int j) { return (i < j)? i: j; }
class FastPostman { public: int minTime(vector<int> address, vector<int> maxTime, int initialPos) { int res,i,j,n = address.size(); vector<pair<int, int> > houses; for(i=0;i<n;i++) houses.push_back(make_pair(address[i],maxTime[i])); sort(houses.begin(),houses.end()); memset(sol,0,sizeof(sol)); for(i=0;i<n;i++) { sol[i][i][0] = sol[i][i][1] = abs(houses[i].first - initialPos); if (sol[i][i][0] > houses[i].second) sol[i][i][0] = sol[i][i][1] = INF; } for(i=n-1;i>=0;i--) { for(j=i+1;j<n;j++) { sol[i][j][0] = min(sol[i+1][j][0]+houses[i+1].first-houses[i].first, sol[i+1][j][1]+houses[j].first-houses[i].first); if (sol[i][j][0] > houses[i].second) sol[i][j][0] = INF; sol[i][j][1] = min(sol[i][j-1][0]+houses[j].first-houses[i].first, sol[i][j-1][1]+houses[j].first-houses[j-1].first); if (sol[i][j][1] > houses[j].second) sol[i][j][1] = INF; } } res = min(sol[0][n-1][0],sol[0][n-1][1]); if (res == INF) return -1; return res; } };
19. Прыгатель по платформам [Топкодер, раунд 353, дивизион 2, уровень 3; дивизион 1, уровень 2]. Поскольку игрок при прыжках всегда движется вниз, то его путь всегда конечный, а каждая платформа может быть посещена не более одного раза. Пусть opt[ i ] содержит наибольшее количество монет, которое можно собрать по всем путям, заканчивающихся на i - ой платформе. Обозначим через s[ i ] множество платформ, с каждой из которых за один прыжок можно попасть на i - ую платформу. Пусть coins[ i ] – количество монет, находящихся на i - ой платформе. Тогда имеет место рекуррентность: opt[ i ] = coins[ i ] + Остается научиться определять, можно ли прыгнуть из одной платформы на другую. Пусть платформы имеют координаты (x 1, y 1) и (x 2, y 2), y 1 > y 2. Игрок должен преодолеть по горизонтали расстояние | x 1 – x 2|, по вертикали | y 1 – y 2|. Наибольшая горизонтальная скорость движения при прыжке равна v, которая по условию задачи постоянна. Тогда время, за которое может быть преодолена горизонтальная составляющая, равно t = | x 1 – x 2| / v. Вычислим расстояние, на которое переместится за это время игрок по оси ординат. Оно равно dy = g * t 2 / 2 Если dy > | y 1 – y 2|, то прыжок совершить невозможно. Перепишем последнее неравенство в виде: g * | x 1 – x 2|2 / 2 v 2 > | y 1 – y 2|, или для избежания операции деления: g * | x 1 – x 2|2 > | y 1 – y 2| * 2 v 2 Отсортируем платформы по y - координате. Последовательно, начиная с наивысшей платформы, вычисляем значения массива opt согласно выше приведенной рекуррентной формуле. В переменной res накапливаем ответ – он равен наибольшему значений среди всех ячеек массива opt.
#include <cstdio> #include <vector> #include <string> #include <algorithm> #define i64 long long using namespace std;
struct pos { i64 x,y,coins; } c[50];
int f(pos a, pos b) { return a.y < b.y; }
class PlatformJumper { public: int maxCoins(vector<string> platforms, int v, int g) { int i,j,res,n=platforms.size(),opt[50]; for(res=i=0;i<n;i++) sscanf(platforms[i].c_str(),"%lld %lld %lld", &c[i].x,&c[i].y,&c[i].coins); sort(c,c+n,f); for(i=n-1;i>=0;i--) { opt[i] = c[i].coins; for(j=i+1;j<n;j++) if ((opt[j] + c[i].coins > opt[i]) && (g*(c[i].x - c[j].x)*(c[i].x - c[j].x) <= (c[j].y - c[i].y)*2*v*v)) opt[i] = opt[j] + c[i].coins; if (opt[i] > res) res = opt[i]; } return res; } };
|
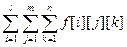 или
или  – 1
– 1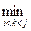 (f(i, k) + f(k +1, j)). Подстроку sisi +1… sj -1 sj рассматриваем как последовательность двух правильных скобочных структур: si … sk и sk +1… sj.
(f(i, k) + f(k +1, j)). Подстроку sisi +1… sj -1 sj рассматриваем как последовательность двух правильных скобочных структур: si … sk и sk +1… sj.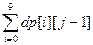
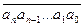 . Для вычисления f(x) разобъем множество чисел от 0 до x на два подмножества:
. Для вычисления f(x) разобъем множество чисел от 0 до x на два подмножества: . Сюда входят все (n + 1) - значные числа, начинающиеся цифрой 0, 1, …, an – 1. Сумма их цифр равна dp[0][ n + 1] + dp[1][ n + 1] + … + dp[ an – 1][ n + 1].
. Сюда входят все (n + 1) - значные числа, начинающиеся цифрой 0, 1, …, an – 1. Сумма их цифр равна dp[0][ n + 1] + dp[1][ n + 1] + … + dp[ an – 1][ n + 1].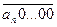 0 до
0 до 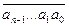 + 1) раз. Сумма остальных цифр этого множества равна f(
+ 1) раз. Сумма остальных цифр этого множества равна f(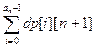 + an * (
+ an * (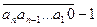 ;
; до
до 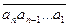 = x /10, умноженного на количество чисел во множестве, то есть на (a 0 + 1). Положим temp = a 0 = x % 10. Пусть sum(x) – функция, вычисляющая сумму цифр числа x. Тогда сумма цифр всех чисел второго множества равна
= x /10, умноженного на количество чисел во множестве, то есть на (a 0 + 1). Положим temp = a 0 = x % 10. Пусть sum(x) – функция, вычисляющая сумму цифр числа x. Тогда сумма цифр всех чисел второго множества равна , где p =
, где p = 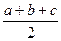
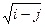 денег. При этом среди всех возможных j следует выбрать такое, для которого сумма c[ j ] +
денег. При этом среди всех возможных j следует выбрать такое, для которого сумма c[ j ] + 



