
Отчет по курсовому проекту. по курсу «Программирование и основы алгоритмизации»по курсу «Программирование и основы алгоритмизации» вариант №15
Выполнил: студент группы 03-205 Хоритонов А. А. Проверил: доцент каф. 301 Галютин В. Б.
Москва, 2012. Мне плевать на слова, покажите мне исходный код АННОТАЦИЯ Пояснительная записка к курсовой работе: 63 страницы; 7 разделов; Объект исследования: нелинейное уравнение. Цель работы: разработка программы и решение с её помощью нелинейных уравнений методом половинного деления. Метод исследования: изучение литературы, написание и отладка программы на компьютере. Данную программу можно использовать, чтобы подтереться ею в туалете, и для нахождения корней нелинейных уравнений в заданном интервале. Разработана одна с половиной программа, которая находит корень произвольного нелинейного уравнения. Программа разработана под пивом на языке программирования C++, с использованием Windows API, в среде программирования Dev-C++ версии 4.9.9.2.
СОДЕРЖАНИЕ Введение.................................................................................................. 4 стр. ГЛАВА 1. Теоретическая часть 1.1 Постановка задачи..................................................................... 5 стр. 1.2 Математическая модель............................................................. 6 стр. 1.3 Блок-схема алгоритма............................................................... 7 стр. ГЛАВА 2. Проект программы 2.1 Состав проекта........................................................................... 8 стр. 2.2 Обзор проекта программы....................................................... 9 стр. 2.3 Схема связей модулей проекта.................................................. 34 стр. ГЛАВА 3. Показательная часть 3.1 Характеристика программы..................................................... 35 стр. 3.2 Решение контрольных примеров.............................................. 36 стр. 3.3 Инструкция пользователя......................................................... 37 стр. Выводы по работе................................................................................... 38 стр. Приложения............................................................................................. 39 стр. Список использованных источников..................................................... 64 стр.
ВВЕДЕНИЕ В наше время всем глубоко насрать, какое место компьютеры занимают в математике и так далее. Современный компьютер, даже персональный, способен выполнять миллиарды операций в секунду. А это предопределяет его судьбу – производить колоссальные вычисления, на которые людям не хватит ни сил, ни времени. Вычислительные мощности компьютера позволяют реализовывать на нём различные численные методы решения уравнений, систем уравнений. Последние же, в свою очередь, имеют неоценимое значение для науки. С помощью численных методов удаётся найти решение, пусть и приближённое, там, где аналитически это сделать крайне затруднительно или вовсе невозможно. Но для того, чтобы компьютер выполнял нужные вычисления, необходимо В процессе разработки программы не стоит также забывать, что программа должна быть для людей. С точки зрения пользователя программы, она должна иметь дружелюбный и интуитивно понятный интерфейс. Так как
ГЛАВА 1. ТЕОРЕТИЧЕСКИЙ РАЗДЕЛ 1.1. ПОСТАНОВКА ЗАДАЧИ Целью данной работы является написание программы, позволяющей находить корень нелинейного (произвольного) уравнения методом половинного деления. С точки зрения пользователя программа должна принимать на вход само уравнение (в текстовом виде, т.к. уравнение в общем случае нелинейно), отрезок, в котором будет искаться корень (этого требует сам метод решения), и погрешность вычисления. Для удобства пользователя все эти параметры должны вводиться из текстовых полей оконной формы, и результат также должен выводиться в эту форму. Контрольные примеры: f(x) = ex – ln(x); f(x) = 8sin2(x) – cos(√x); f(x) = 12x4 – 6x3 + 7x2 + 5x – 24;
1.2. МАТЕМАТИЧЕСКАЯ МОДЕЛЬ Метод деления отрезка пополам (или метод бисекции) — простейший численный метод для решения нелинейных уравнений вида f(x) = 0. Алгоритм данного метода основывается на следствии из теоремы Для начала итераций необходимо знать интервал Итерационный процесс продолжается до тех пор, пока длина отрезка, внутри которого ищется решение, не станет меньше или равным наперёд заданной погрешности. Это гарантирует, что расстояние от любого конца отрезка до искомого корня будет меньше, чем величина погрешности, и, следовательно, заданная погрешность обеспечена.
1.3. БЛОК-СХЕМА АЛГОРИТМА
ГЛАВА 2. ПРОЕКТ ПРОГРАММЫ 2.1. СОСТАВ ПРОЕКТА Проект программы содержит 11 файлов, из них 3 заголовочных файла и 8 файлов исходного кода. Список файлов: - main.h - main.cpp - FloatInput.cpp - WarningsOut.cpp - WorkSolve.cpp - formuls.h - formuls.cpp - formuls2.cpp - Analisator.h - Analisator.cpp - AnalisatorService.cpp
2.2. ОБЗОР ПРОЕКТА ПРОГРАММЫ Для начала – нами выбран оконный тип приложения, для выполнения в операционной системе Windows. Оконное Windows приложение имеет свой шаблон: регистрация класса окна, создание главного окна приложения и цикл обработки сообщений системы, а так же функция обработки сообщений. Функция, с которой начинается выполнение Windows приложения, имеет имя WinMain и находится в файле main.cpp. Листинг 1. Функция WinMain int WINAPI WinMain(HINSTANCE hThisInstance, HINSTANCE hPrevInstance, LPSTR lpszArgument, int nFunsterStil) { MSG messages; WNDCLASSEX wincl;
wincl.hInstance = hThisInstance; wincl.lpszClassName = "WinApp"; wincl.lpfnWndProc = WinPro; wincl.style = CS_DBLCLKS; wincl.cbSize = sizeof (WNDCLASSEX); wincl.hIcon = LoadIcon (NULL, IDI_APPLICATION); wincl.hIconSm = LoadIcon (NULL, IDI_APPLICATION); wincl.hCursor = LoadCursor (NULL, IDC_ARROW); wincl.lpszMenuName = NULL; wincl.cbClsExtra = 0; wincl.cbWndExtra = 0; wincl.hbrBackground = (HBRUSH) COLOR_3DSHADOW;
if (!RegisterClassEx (&wincl)) return -80; // error - win hInst = hThisInstance; // class not registered
hwnd = CreateWindow("WinApp", "Sample Solve 3D", CW_USEDEFAULT, CW_USEDEFAULT, 480, 220, HWND_DESKTOP, NULL, hThisInstance, NULL);
ShowWindow(hwnd, nFunsterStil);
while (GetMessage (&messages, NULL, 0, 0)) { TranslateMessage(&messages); DispatchMessage(&messages); };
return messages.wParam; }
При создании окна необходимо добавить поля для ввода и подписи к ним, а так же кнопку включения и поле для вывода результата. Это делается в функции обработки сообщений WinPro при получении сообщения WM_CREATE. Листинг 2. Функция WinPro, создание элементов управления LRESULT CALLBACK WinPro(HWND hwnd, UINT message, WPARAM wParam, { switch (message) { case WM_CREATE: { CreateWindow("static", "Уравнение F(x) =", 20, 10, 120, 20, hwnd, (HMENU) 1, equ = CreateWindow("edit", "", WS_CHILD | 150, 10, 300, 20, hwnd, (HMENU) 2, CreateWindow("static", "Интервал:", 30, 60, 100, 20, hwnd, (HMENU) 3, segmin = CreateWindow("edit", "", WS_CHILD | 150, 60, 60, 20, hwnd, (HMENU) 4, CreateWindow("static", ";", 220, 60, 20, 20, hwnd, (HMENU) 5, segmax = CreateWindow("edit", "", WS_CHILD | 230, 60, 60, 20, hwnd, (HMENU) 6, CreateWindow("static", "Погрешность:", 30, 90, 100, 20, hwnd, (HMENU) 7, epsi = CreateWindow("edit", "", WS_CHILD | WS_VISIBLE | WS_BORDER | ES_AUTOVSCROLL, 150, 90, 60, 20, hwnd, (HMENU) 8, CreateWindow("button", "Решить!", 30, 150, 100, 20, hwnd, (HMENU) 9, res = CreateWindow("edit", "", WS_CHILD | 150, 150, 200, 20, hwnd, (HMENU) 10, hInst, NULL);
AddStringFloat(segmin); AddStringFloat(segmax); AddStringFloat(epsi); break; };
По нажатию на кнопку «Решить!» (hMenu = 9) программа должна считать данные из соответствующих полей (в виде текста), выполнить решение и вывести результат, или вывести сообщение об ошибке. Функция, выполняющая решение по методу половинного деления, имеет имя WorkSolve и находится в файле WorkSolve.cpp. Функция, обрабатывающая коды ошибок, называется wOut и находится, соответственно, в файле WarningsOut.cpp. Листинг 3. Выполнение решения case WM_COMMAND: if(LOWORD(wParam) == 9) { char str_equ[256]; char str_segmin[64]; char str_segmax[64]; char str_epsi[64]; char str_res[64];
SendMessage(equ, WM_GETTEXT, 256, (LPARAM)str_equ); SendMessage(segmin, WM_GETTEXT, 64, (LPARAM)str_segmin); SendMessage(segmax, WM_GETTEXT, 64, (LPARAM)str_segmax); SendMessage(epsi, WM_GETTEXT, 64, (LPARAM)str_epsi);
int err = WorkSolve(str_equ, str_segmin, str_segmax,
if(err) wOut(err); else SendMessage(res, WM_SETTEXT, 64, (LPARAM)str_res); }; break;
Полностью файл main.cpp приведён в Приложении 1. А так же там приведён файл main.h, в котором объявляются необходимые функции из других файлов, и подключается стандартная библиотека windows.h, необходимая для работы Windows приложения. В несколько полей должны вводиться дробные десятичные числа. Чтобы обеспечить фильтрацию всех неподходящих символов и обеспечить правильную запись чисел для последующей обработки, нам потребуется модифицировать функцию обработки соответствующих полей. Для этого при создании элементов управления были добавлены вызовы функции AddStringFloat для элементов segmin, segmax и epsi. Функционал, необходимый для обеспечения ввода вещественных чисел в текстовые поля, находится в файле FloatInput.cpp, который приведён в Приложении 2. Функция AddStringFloat(HWND) добавляет указанный в качестве параметра элемент управления в отдельный список и замещает функцию обработки этого элемента на FloatNumStringPro, сохраняя предыдущую. Сам список имеет структурный тип и представляет собой связанный список. Листинг 4. Список элементов для ввода вещественных чисел struct StringFloatNumeric { HWND handle; WNDPROC EditWndProc; StringFloatNumeric *next; };
static StringFloatNumeric *first = NULL;
Листинг 5. Функция AddStringFloat void AddStringFloat(HWND str) { StringFloatNumeric *cur;
if(first == NULL) { first = new StringFloatNumeric; cur = first; } else { for(cur = first; cur->next!= NULL; cur = cur->next); cur->next = new StringFloatNumeric; cur = cur->next; };
cur->next = NULL; cur->handle = str; cur->EditWndProc = (WNDPROC)SetWindowLong(str, GWL_WNDPROC, }
Для грамотного управления памятью добавлена функция ClearStringFloatList, которая освобождает из памяти весь список. Листинг 6. Функция ClearStringFloatList void ClearStringFloatList() { StringFloatNumeric *cur = first; StringFloatNumeric *p;
while(cur!= NULL) { p = cur; SetWindowLong(cur->handle, GWL_WNDPROC, cur = cur->next; delete p; }; }
И, наконец, сама функция FloatNumStringPro, которая получает все сообщения, направленные элементам, добавленным ранее в список. Она отслеживает сообщение WM_CHAR, ввод символа, и осуществляет отбор символов по сложному условию. Если символ не должен быть пропущен на дальнейшую обработку, то индикатор сообщения – переменная message – обнуляется. Все цифры и BackSpaсe пропускаются, точка пропускается только если её ещё нет (т. е. если она нашлась в строке, то сообщение тут же блокируется), и, наконец, минус может быть пропущен, если курсор стоит в начале строки, но будет блокирован, если минус там уже стоит. В конце вызывается сохранённая функция, чтобы обработать пропускаемые и все остальные, кроме WM_CHAR, сообщения. Листинг 7. Функция FloatNumStringPro LRESULT CALLBACK FloatNumStringPro(HWND hwnd, UINT message, { StringFloatNumeric *cur;
for(cur = first; cur!= NULL; cur = cur->next) if(hwnd == cur->handle) break;
if(message == WM_CHAR) // при вводе символа решаем, какие { if(wParam == VK_BACK || isdigit((int) wParam));
else if(wParam == '.') // а вот с точкой сложнее { char* tbuff = new char [128]; char* Text = tbuff;
CallWindowProc(cur->EditWndProc, cur->handle,
while(*Text++) if(*Text == '.') { message = 0; MessageBeep(MB_SERVICE_NOTIFICATION); break; }; delete tbuff; }
else if(wParam == '-') { LRESULT i = CallWindowProc(cur->EditWndProc,
if(LOWORD(i) == 0) { char Text [128]; CallWindowProc(cur->EditWndProc, cur->handle,
if(Text[0] == '-') // и, если вдруг, вначале уже { message = 0; } else { message = 0; MessageBeep(MB_SERVICE_NOTIFICATION);}; }
else { // все остальные символы не пропускаются message = 0; MessageBeep(MB_SERVICE_NOTIFICATION); }; };
return CallWindowProc(cur->EditWndProc, hwnd, message, } В файле WorkSolve.cpp находится основная функция, которая реализует алгоритм решения уравнения методом половинного деления – Далее идут два параметра – числа, означающие границы отрезка, в котором ищется решение, представленные также в текстовом виде. Для получения числовых значений служит библиотечная функция Четвёртый параметр содержит число, также в текстовом представлении, означающее погрешность для вычисления корня. Ну и последний параметр – это срока, вернее буфер, в который следует выводить значение полученного корня. Для конвертации числа в строковое представление существует функция gcvt(double, int, char*). Её параметры – само число, основание системы счисления и собственно буфер, куда выводить. Уравнение в общем случае нелинейно, и поэтому для вычислений требуется математический интерпретатор. В данном случае для представления формулы в вычислимом виде решено использовать такую структуру как дерево. Его узлы представляют собой объекты классов, производных от базового класса, содержащего чисто виртуальный метод Calc() – «вычислить». Для начала требуется создать это дерево, используя интерпретатор. Для этого служит функция SyntaxAnalysing(const char*), находящаяся в файле Analisator.cpp. Функция возвращает указатель на верхний элемент дерева, типизируя его как FORMULA* (базовый виртуальный класс). Листинг 8. Начало функции WorkSolve static FORMULA* Equation = NULL;
int WorkSolve(const char* EquationString, const char* SegmentMinimum, const char* SegmentMaximum, const char* Epsilon, char* OutputString) { reset_error();
float left = atof(SegmentMinimum); float right = atof(SegmentMaximum); float middle;
if(left >= right) return WorkError(-5);
float eps = atof(Epsilon); if(eps <= 0) return WorkError(-6);
Equation = SyntaxAnalysing(EquationString); if(get_error()) return WorkError(-8);
Сначала проверяется корректность указанного интервала, корректность введённой погрешности. Также, проверяется, не возникло ли ошибки при работе синтаксического анализатора (интерпретатора). Функции get_error() (получение кода ошибки) и reset_error() (установка кода ошибки в ноль) содержатся в файле AnalisatorService.cpp, который используется файлом Analisator.cpp. Вычисления производятся функцией Calculate(FORMULA*, float), которая описана в файле formuls.cpp, содержащем также описания функций Calc() всех классов, дочерних для FORMULA. Листинг 9. Подготовка для вычислений float F_left = Calculate(Equation, left); float F_right = Calculate(Equation, right); float F_middle;
if(get_error()) return WorkError(-36);
if(F_left * F_right > 0) return WorkError(-12); // (или их там нет)"
И, наконец, сам итерационный процесс. Листинг 10. Итерационный процесс метода половинного деления while(right - left > eps) { middle = (left + right) / 2;
F_middle = Calculate(Equation, middle); if(get_error()) return WorkError(-36);
if(F_left * F_middle > 0) { left = middle; F_left = F_middle; } else { right = middle; F_right = F_middle; }; };
gcvt(middle, 10, OutputString);
FreeFormula(Equation); return 0; }
В конце, для освобождения памяти, вызывается функция FreeFormula, которая позволяет удалить из памяти все элементы дерева. Функция WorkError позволяет при возникновении ошибки сделать вызов FreeFormula, необходимый при любом выходе из функции, и возвращает переданное ей число (код ошибки). Это позволяет грамотно прерывать работу функции WorkSolve, используя один оператор return. Листинг 11. Функция WorkError int WorkError(int i) { if(Equation) FreeFormula(Equation); return i; }
Полностью файл WorkSolve.cpp приведён в Приложении 3. Как уже говорилось ранее, для вычислений используется классовая модель дерева. Каждый математический оператор можно представить как функцию, которая имеет аргументы в виде операторов (или функций) более высокого приоритета. Таким образом, его можно представить как вершину дерева с ветвями – аргументами, и для вычисления какого либо значения требуется сначала вызвать подсчёт у своих ветвей, а затем, используя эти значения, выдать результат собственной операции. Функции и операторы многообразны, и поэтому для каждого из них создан свой класс. Однако сам оператор не может знать, какого типа его аргументы, и поэтому требуется один базовый абстрактный класс, потомками которого являются классы всех операторов и функций. Этот класс назван FORMULA; он не содержит ничего, кроме абстрактного метода Calc(), который собственно и производит вычисления, и ещё метод destroy() – также абстрактный, для последующего удаления формулы. Класс не содержит указателей на другие формулы, как на ветви дерева, поскольку в разных случаях число (и интерпретация) аргументов функции различно. Функциями следует также считать и сам аргумент (x) и числовую константу. Первый при вычислении просто возвращает значение аргумента, а вторая – число, сохранённое в соответствующем поле. Эти функции не содержат аргументов, а значит и указателей на другие функции. Описание всех классов содержится в файле formuls.h. Это заголовочный файл, который включается во все файлы, где используется класс FORMULA и, соответственно, формульная модель. Файл приведён в Приложении 4. Листинг 12. Класс FORMULA и оконечные классы class FORMULA { public: virtual float Calc() = 0; virtual void destroy() = 0; };
class ARGUMENT: public FORMULA { public: float Calc(); void destroy(); };
class CONSTANT: public FORMULA { public: float num; float Calc(); void destroy(); };
Математические операторы, такие как сложение, вычитание, умножение, деление и степень имеют два аргумента, поэтому для них возможно создать один базовый класс, в котором определены указатели на левый и правый аргументы, однако метод Calc() для каждого оператора остаётся индивидуальным.
Листинг 13. Группа классов «Арифметические» class ARITHMETIC: public FORMULA { public: FORMULA* left; FORMULA* right; virtual float Calc() = 0; void destroy(); };
class ADDITION: public ARITHMETIC { public: float Calc(); }; class SUBTRACTION: public ARITHMETIC { public: float Calc(); }; class MULTIPLICATION: public ARITHMETIC { public: float Calc(); }; class DIVISION: public ARITHMETIC { public: float Calc(); }; class POWER: public ARITHMETIC { public: float Calc(); };
Все математические функции, такие как экспонента, квадратный корень и т.д. имеют один единственный аргумент. Для них создан материнский класс MATH_LIB («математическая библиотека»). Унарный минус хоть и не относится к функциям, но чисто формально имеет также один аргумент, поэтому удобно сделать его наследником этого класса. Листинг 14. «Математическая библиотека» class MATH_LIB: public FORMULA { public: FORMULA* sub; virtual float Calc() = 0; void destroy(); };
class NEGATIVE: public MATH_LIB { public: float Calc(); }; class SIN_: public MATH_LIB { public: float Calc(); }; class COS_: public MATH_LIB { public: float Calc(); }; class TAN_: public MATH_LIB { public: float Calc(); }; class CTG_: public MATH_LIB { public: float Calc(); }; class SH_: public MATH_LIB { public: float Calc(); }; class CH_: public MATH_LIB { public: float Calc(); }; class TH_: public MATH_LIB { public: float Calc(); }; class CTH_: public MATH_LIB { public: float Calc(); }; class ASIN_: public MATH_LIB { public: float Calc(); }; class ACOS_: public MATH_LIB { public: float Calc(); }; class ATAN_: public MATH_LIB { public: float Calc(); }; class ACTG_: public MATH_LIB { public: float Calc(); }; class EXP_: public MATH_LIB { public: float Calc(); }; class LN_: public MATH_LIB { public: float Calc(); }; class SQRT_: public MATH_LIB { public: float Calc(); }; class ABS_: public MATH_LIB { public: float Calc(); };
В файле formuls.cpp находятся реализации метода Calc() всех классов, а также функция Calculate(FORMULA*, float), которая запускает процесс вычисления. В файле находится глобальная переменная static float Arg, она используется классом ARGUMENT, метод Calc() которого возвращает значение, сохранённое в этой переменной. Функция Calculate присваивает переменной Arg значение, передаваемое ей во втором аргументе, и вызывает метод Calc объекта, указанного в первом аргументе. Сам файл formuls.cpp содержится в Приложении 5. Приводить очевидные операции вычисления всех математических функций здесь не имеет смысла. Метод destroy() позволяет удалять все элементы дерева, вызывая сначала этот метод для своих ветвей, а потом удаляя их. Поскольку реализация зависит только от числа ветвей, то она определена уже в классах ARITHMETIC и MATH_LIB. Функция FreeFormula(FORMULA*), которая используется в файле WorkSolve.cpp, позволяет запустить этот метод для указанного объекта, а потом удалить его. Таким образом можно удалять всё дерево сразу. Функция FreeFormula и реализации методов destroy() описаны в файле formuls2.cpp, который помещён в Приложении 6. Листинг 15. Файл formuls2.cpp #include "formuls.h"
void FreeFormula(FORMULA* E) { E->destroy(); delete E; return; }
void ARGUMENT::destroy() { return; }
void CONSTANT::destroy() { return; }
void ARITHMETIC::destroy() { if(left) { left->destroy(); delete left; }
if(right) { right->destroy(); delete right; }
return; }
void MATH_LIB::destroy() { if(sub) { sub->destroy(); delete sub; }
return; }
Наконец, пришло время поговорить о самом главном – об анализаторе, или математическом интерпретаторе. Его части находятся в таких файлах как Analisator.h, Analisator.cpp и AnalisatorService.cpp. Интерпретатор, вообще говоря, состоит из Синтаксического и Лексического анализаторов. Лексический анализатор выполнен в виде отдельного класса, в котором содержатся и анализируемая строка, и переменные, определяющие текущее состояние (текущую лексему), и, самое главное, метод, считывающий следующую лексему. Класс имеет имя AnalisingContainer. Состояние лексемы описывается – 1) её типом, переменная curr_tok, имеет перечисляемый тип token_type. В нашем случае лексемой может быть: число (численная константа), аргумент (икс), именованная функция, плюс, минус, умножить, разделить, степень, левая и правая скобки, а так же конец строки и «что-то неизвестное». 2) Числовое значение, если тип лексемы – число. 3) Тип (номер) функции, если текущая лексема – это функция; тип этого параметра так же перечисляемый (func_type). Листинг 16. Файл Analisator.h #include "formuls.h" #include <ctype.h>
enum token_type { NUMBER, FUNC, END, UNKNOW, X='x', PLUS='+', MINUS='-', MUL='*', DIV='/', PWR='^', LeftP='(', RightP=')' };
enum func_type { F_SIN, F_COS, F_TAN, F_CTG, F_SH, F_CH, F_TH, F_CTH, F_ASIN, F_ACOS, F_ATAN, F_ACTG, F_EXP, F_LN, F_SQRT, F_ABS };
class AnalisingContainer { public: const char* src_str; token_type curr_tok; float curr_value; func_type curr_func; void get_token(); };
extern AnalisingContainer AC; extern MATH_LIB* new_func();
Описание метода get_token() мы рассмотрим чуть позже, а пока обратимся к файлу Analisator.cpp, где содержится Синтаксический анализатор. Результат его работы – дерево элементов классов, дочерних FORMULA. Анализ начинается с обработки операторов, имеющих самый низкий приоритет – это сложение и вычитание. Листинг 17. Функция expr() FORMULA* expr() { FORMULA* left = term();
for(;;) switch(AC.curr_tok) { case PLUS: { ADDITION* res = new ADDITION; AC.get_token(); res->left = left; res->right = term(); left = (FORMULA*) res; break; }; case MINUS: { SUBTRACTION* res = new SUBTRACTION; AC.get_token(); res->left = left; res->right = term(); left = (FORMULA*) res; break; }; default: return left; }; }
Аргументами сложения и вычитания являются результаты операторов более высокого приоритета – умножения и деления (а может и дальше). Поэтому необходимо запустить их обработчик – функцию term(). При нахождении (своеместном) плюса или минуса создаются соответствующие объекты; в качестве левого аргумента используется то, что уже было получено ранее, а в качестве правого – то, что получит term() сразу после текущего знака. Если после обработки всех операторов более высокого уровня далее не следует плюс или минус, то, значит, обработка окончена. В функции term() всё аналогично для умножения и деления, только обработкой более высокого по приоритету оператора степени занимается функция pw(). Листинг 18. Функция term() FORMULA* term() { FORMULA* left = pw();
for(;;) switch(AC.curr_tok) { case MUL: { MULTIPLICATION* res = new MULTIPLICATION; AC.get_token(); res->left = left; res->right = pw(); left = (FORMULA*) res; break; }; case DIV: { DIVISION* res = new DIVISION; AC.get_token(); res->left = left; res->right = pw(); left = (FORMULA*) res; break; }; default: return left; }; }
Функция pw() сначала получает первичное (функцией prim()), после этого проверяет, стоит ли после него знак степени (^). В этом случае создаёт (вернее, размещает в памяти) объект POWER, левый аргумент – полученное ранее первичное, правый – ещё одно первичное, и возвращает указатель на этот объект. В противном случае просто возвращает полученное первичное. Листинг 19. Функция pw() FORMULA* pw() { FORMULA* left = prim(); if(AC.curr_tok == PWR) { POWER* res = new POWER; AC.get_token(); res->left = left; res->right = prim(); return (FORMULA*) res; }; return left; }
Функция prim() возвращает объект, являющийся первичным элементом в синтаксисе. Это может быть число, аргумент функции, унарный минус, функция или выражение в скобках. В соответствии с текущей лексемой создаётся объект. Далее, для числа в соответствующее поле записывается значение распознанного числа; для минуса в качестве подвыражения берётся следующее первичное, также и для функции. Если встретились скобки, тогда требуется заново запустить анализ операторов самого низкого приоритета, чтобы получить всё выражение в скобках. Если вдруг встретился конец строки, то возвращаем соответственно NULL (НИЧЕГО). Во всех остальных случаях имеет место ошибка. Листинг 20. Функция prim() FORMULA* prim() { switch(AC.curr_tok) { case NUMBER: { CONSTANT* res = new CONSTANT; res->num = AC.curr_value; AC.get_token(); return (FORMULA*) res; }; case X: { AC.get_token(); return (FORMULA*) new ARGUMENT; }; case MINUS: { NEGATIVE* res = new NEGATIVE; AC.get_token(); res->sub = prim(); return (FORMULA*) res; }; case FUNC: { MATH_LIB* res = new_func(); AC.get_token(); res->sub = prim(); return (FORMULA*) res; }; case LeftP: { AC.get_token(); FORMULA* e = expr(); if(AC.curr_tok!= RightP) return error(4); AC.get_token(); return e; }; case END: return NULL; default: return error(16); // нарушен порядок символов }; }
Полностью файл Analisator.cpp содержится в Приложении 8, а заголовочный файл Analisator.h – в Приложении 7. А теперь – о файле AnalisatorService.cpp. Помимо самой функции get_token() там содержатся функции MATH_LIB* new_func(), FORMULA* error(int code), int get_error(), void reset_error(). Но обо всём по порядку. Функция new_func() возвращает объект конкретной функции согласно тому, какой тип функции определил Лексический анализатор. Функция error(int) записывает переданный ей код ошибки в глобальную переменную error_code, если там ещё не содержится кода ошибки (переменная определяется как static int error_code = 0;). Также эта функция возвращает NULL в качестве указателя на формулу (для совместимости с функциями Синтаксического анализатора). Функция get_error() возвращает сохранённый код ошибки, а reset_error() устанавливает error_code в ноль. Теперь о самой get_token(), которая сканирует исходную строку и распознаёт лексемы. Вот как она работает. Для начала необходимо пропустить все обобщённые пробелы (в это понятие входит и табуляция, и т. д.). Если достигнут конец строки, то, формально, текущая лексема – «конец». Листинг 21. Начало функции get_token() void AnalisingContainer::get_token() { while(isspace((int) *src_str)) src_str++; char ch = *src_str;
if(ch == '\0') { curr_tok = END; return; };
Далее идёт распределение по текущему символу. Если это + - * / () ^ или аргумент («х»), то они обозначают соответствующие лексемы, и поэтому в curr_tok они записываются напрямую. Листинг 22. Простейшие лексемы switch(ch) { case '+': case '-': case '*': case '/': case '(': case ')': case '^': case 'x': curr_tok = token_type(ch); src_str++; return;
Если текущий символ – цифра, то следует прочитать число. Признаком конца является символ – не цифра и не точка. Далее остаётся перевести строку в число (типа float). Листинг 23. Распознавание чисел case '0': case '1': case '2': case '3': case '4': case '5': case '6': case '7': case '8': case '9': case '.': { curr_tok = NUMBER;
char* buff = new char [128]; char* buff2 = buff;
while(isdigit((int) *src_str) || *src_str == '.') *buff = '\0';
curr_value = atof(buff2); delete buff2; return; };
В противном случае это может быть только математическая функция. Исходный текст проверяется на соответствие названию какой-либо из функций. Названия содержатся в массиве const char* F_names [16]. Для каждого из 16 названий происходит сравнение его символов и символов исходной строки до тех пор, пока не кончится строка или пока символы совпадают. Если после этого сравнение остановилось на конце строки в массиве, значит соответствующая функция распознана. Иначе, если после сравнения со всеми элементами массива правильное совпадение так и не найдено, значит лексема нам не известна и имеет место ошибка. Листинг 24. Распознавание математической функции default: { register int i; register int k;
for(i = 0; i < 16; i++) { k = 0; while(src_str[k]!= '\0' && F_names[i][k] == src_str[k])
if(F_names[i][k] == '\0') { curr_tok = FUNC; curr_func = func_type(i); src_str += k; return; }; };
curr_tok = UNKNOW; error(8); // неизвестная функция return; };
Полностью файл приведён в Приложении 9. Ну вот, казалось бы и всё. А нет! Программа ещё и обрабатывает ошибки, полученные в процессе Работы. Делает она это с помощью функции wOut(), упомянутой ранее при описании оконной процедуры. Находится эта функция в файле WarningsOut.cpp. На вход ей подаётся код ошибки, полученный от функции WorkSolve, задача самой функции – вывести уведомление с описанием ошибки. Для начала создаём строку – буфер, куда будет записан текст уведомления, он будет выглядеть так: «error:» код_ошибки «-» описание_ошибки; а так же опционально номер и описание синтаксической или вычислительной ошибки. Создаём указатель на этот буфер и сразу же помещаем его после слова «error:». Записываем в это место число – код ошибки (функция itoa переводит число в строковое представление) и проматываем до границы этой записи. Первые приготовления закончены, теперь надо добавить описание ошибки. Для этого создаём указатель и, в соответствии с кодом ошибки, настраиваем его на одну из строковых констант. Далее, с помощью цикла while копируем её в наш буфер. Листинг 25. Создание уведомления об ошибке void wOut(int err) { char err_str [256] = "error: ";
char* p = err_str + 7; itoa(err, p, 10); while(*p++); p--;
char* mp; switch(err) { case -5: mp = " - некорректный интервал"; break; case -6: mp = " - отрицательная погрешность"; break; case -8: mp = " - некорректная формула"; break; case -36: mp = " - ошибка при вычислениях"; break; case -12: mp = " - на интервале чётное число корней (или их там };
while(*p++ = *mp++); p--;
Если код ошибки – -8, то это синтаксическая ошибка; мы дополнительно приписываем «syntax error:», код синтаксической ошибки, получаемый функцией get_error(), и её описание. А если код ошибки – -36, то это вычислительная ошибка, и с ней аналогично. Теперь осталось только вывести сообщение об ошибке. Листинг 26. Расширенное описание ошибки if(err == -8) { mp = "\nsyntax error: "; while(*p++ = *mp++); p--;
itoa(get_error(), p, 10); while(*p++); p--;
switch(get_error()) { case 2: mp = " - ожидался конец строки"; break; case 4: mp = " - требуется закрывающая скобка"; break; case 8: mp = " - неизвестная функция"; break; case 16: mp = " - неверный порядок символов"; break; };
while(*p++ = *mp++); }
else if(err == -36) { mp = "\ncalculate error: "; while(*p++ = *mp++); p--;
itoa(get_error(), p, 10); while(*p++); p--;
switch(get_error()) { case 64: mp = " - деление на ноль"; break; case 68: mp = " - неверный аргумент тангенса"; break; case 66: mp = " - неверный аргумент котангенса"; break; case 130: mp = " - неверный аргумент гиперкотангенса"; case 256: mp = " - неверный аргумент арксинуса"; break; case 257: mp = " - неверный аргумент арккосинуса";break; case 80: mp = " - корень из отрицательного числа"; };
while(*p++ = *mp++); };
MessageBox(hwnd, err_str, "Work Error", MB_ICONERROR | MB_OK); }
Полностью файл в Приложении 10. Ну вот и всё. С Вами был Стас Давыдов. Подписывайтесь, оценивайте, а видео на обзор присылайте вот сюда, в раздел «на обзор».
2.3. СХЕМА СВЯЗЕЙ МОДУЛЕЙ ПРОЕКТА
ГЛАВА 3. ПОКАЗАТЕЛЬНАЯ ЧАСТЬ 3.1. ХАРАКТЕРИСТИКА ПРОГРАММЫ
НЗС:
3.2. РЕШЕНИЕ КОНТРОЛЬНЫХ ПРИМЕРОВ
Пример 1. f(x) = ex – ln(x) Ответ: Ошибка, на интервале чётное число корней или их там нет. Всё верно, ибо эта функция не имеет корней, она нигде не пересекает ось абсцисс. Граф
|
 , тогда если
, тогда если 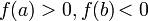 , то
, то 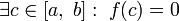 .
. Ввиду объёмности программного проекта, файлов много, и что-то как-то невозможно описать всю ту творческую работу по отладке программы и ловле ошибок, но в результате бессонных ночей и долгой работы программа получилась стабильной и адекватной. По заверениям Диспетчера задач Windows, программа занимает 1 140 Кбайт оперативной памяти, что совсем пофиг, ибо программка совсем не влияет на работоспособность системы. Исполняемый файл занимает на диске 1,08 МБ.
Ввиду объёмности программного проекта, файлов много, и что-то как-то невозможно описать всю ту творческую работу по отладке программы и ловле ошибок, но в результате бессонных ночей и долгой работы программа получилась стабильной и адекватной. По заверениям Диспетчера задач Windows, программа занимает 1 140 Кбайт оперативной памяти, что совсем пофиг, ибо программка совсем не влияет на работоспособность системы. Исполняемый файл занимает на диске 1,08 МБ.


