
Теоретические основы. Кластерный анализ представляет собой статистические методы, используемые для классификации многомерных объектов или событий в относительно однородные группыКластерный анализ представляет собой статистические методы, используемые для классификации многомерных объектов или событий в относительно однородные группы, которые называют кластерами. Объекты в каждом кластере должны быть похожи друг на друга в большей степени, чем на объекты других классов, и отличаться от объектов других кластеров сильнее, чем от объектов собственного класса. В экономике кластерный анализ используется для достижения следующих целей: сегментации рынка, изучения поведения покупателей, определения конкурентоспособности нового товара, сокращения размерности данных и др. Кластеризацию используют, когда отсутствуют априорные сведения относительно классов, к которым можно отнести объекты исследуемого набора данных, либо когда число объектов велико, что затрудняет их ручной анализ. Постановка задачи кластеризации сложна и неоднозначна, так как:
Распространенной мерой оценки близости между объектами является метрика, или способ задания расстояния. Наиболее популярные метрики – евклидово расстояние и расстояние Манхэттена. Важно понимать, что сама по себе кластеризация не приносит каких-либо результатов анализа. Для получения эффекта необходимо провести содержательную интерпретацию каждого кластера. Такая интерпретация предполагает присвоение каждому кластеру емкого названия, отражающего его суть. Для интерпретации аналитик детально исследует каждый кластер: его статистические характеристики, распределение значений признаков объекта в кластере, оценивает мощность кластера – число объектов, попавших в него. Обычно в задачах кластерного анализа исходные данные представляют в форме прямоугольной таблицы, каждая строка которой представляет результат измерения p признаков на соответствующем объекте:
где n - число объектов, подлежащих классификации. Числовые значения признаков, входящих в матрицу, могут соответствовать трем типам переменных: качественным, ранговым и количественным. Качественные переменные, как правило, принимают два и более значений, которым, хотя и можно поставить в соответствие некоторые числа, но эти числа не будут отражать какую-либо упорядоченность значений качественных переменных. И это нужно учитывать при определении близости. Значения ранговых переменных, в отличие от качественных, упорядочены. Их можно пронумеровать натуральными числами. Однако арифметические операции над этими числами не имеют смысла. Количественные переменные обладают свойством упорядоченности, и над ними, в отличие от других, можно приводить арифметические операции. Желательно, чтобы вся таблица исходных данных соответствовала одному типу переменных. Если это не так, то разные типы переменных стараются свести к какому-то одному типу переменных. Самый простой является процедура сведения к качественным переменным. Суть этой процедуры в следующем. Если есть количественные данные, то они сначала сводятся к ранговым, для чего область значений количественных переменных разбивается на интервалы, которые нумеруются числами натурального ряда. Ранговые переменные можно считать качественными, если не учитывать упорядоченность их значений. В свою очередь, качественные переменные переводятся в дихотомические по следующему правилу. Каждое из возможных значений качественной переменной заменяется на 1, если качественная переменная приняла это значение, и 0 - в противном случае. В тех случаях, когда все показатели количественные, часто возникает проблема их нормирования, поскольку различие в единицах измерения делает эти показатели несопоставимыми. Так, например, при классификации промышленных предприятий по результатам финансово-хозяйственной деятельности в описание включаются такие показатели, как прибыль, рентабельность, себестоимость, коэффициент текущей ликвидности и т.д. По прибыли предприятия могут различаться на десятки и сотни тысяч единиц, а по рентабельности - на единицы, а то и десятые доли единицы. Такая несопоставимость практически перечеркивает идею многомерной классификации, так как она автоматически будет осуществляться по более масштабному показателю. Поэтому процедуре непосредственного разнесения объектов по классам должна предшествовать процедура приведения всех показателей к сопоставимому виду, которую принято называть нормированием. В практических расчетах чаще других используются два подхода к нормированию. Один из них связан с идеей статистической стандартизации, осуществляемой по формуле:
где
При использовании такой нормировки все показатели, описывающие классифицируемый объект, приводятся к виду, когда среднее равно 0, а разброс вокруг среднего равен 1. Второй подход предусматривает преобразование показателей путем отображения интервала их возможных значений на промежуток [0;l]. Это осуществляется с помощью формулы:
где Таким образом, с помощью нормирования удается избавиться от нежелательного влияния разномасштабности показателей на степень схожести между объектами. Выбор меры сходства является одним из узловых моментов в задачах классификации, так как от нее, в основном, зависит при данном алгоритме классификации окончательный вариант разбиения объектов на классы. В каждом конкретном случае этот выбор осуществляется в зависимости от цели исследования и природы самих классифицируемых объектов.
|
 , (4.1)
, (4.1) , (4.2)
, (4.2)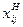 - нормированный j -ый показатель i -го объекта;
- нормированный j -ый показатель i -го объекта; – значение j -го показателя i -го объекта;
– значение j -го показателя i -го объекта; - среднее значение j-го показателя по всему множеству классифицируемых объектов;
- среднее значение j-го показателя по всему множеству классифицируемых объектов; - среднеквадратическое отклонение j -го показателя.
- среднеквадратическое отклонение j -го показателя.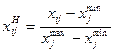 , (4.3)
, (4.3) ;
;  .
.


