
Алгоритм 2. Копирование Листа 1 Рабочего файла на Лист 1(2).
Ответственный за технический выпуск: А.А. Лукашевич
Подписано в печать экспертным советом: 01.09.2009г.
Инструкция по выполнению контрольной работы Построение многофакторной линейной регрессионной модели зависимости объема продаж с помощью инструмента Регрессия надстройки Пакет анализа Подготовительный этап На данном этапе студент должен проделать следующие обязательные действия, связанные с организацией индивидуальной рабочей среды: · записать в свою персональную папку ФИО папку ISM-KR, содержащую два файла Рабочий(ИСМ-КР.хls) и Алгоритмическое обеспечение контрольной работы(АО-КР. doc); · сформировать индивидуальный вариант исходных. 1. Запись в персональную папку студента папки ISM-KR Для выполнения расчетов показателей и подготовки отчета по контрольной работе студент записывает в персональную папку с именем ФИО, папку ISM-KR. Для этого необходимо выполнитьследующие действия: 1. Скопировать папку с исходными данными и алгоритмическим обеспечением контрольной работы по следующему алгоритму: 1. На рабочем столе активизировать Мой компьютер; 2. В диалоговом окне выбрать папку Datadisk на “primary” (E:)\Преподаватели\Кафедра статистики\ISM-KR; 2. Скопировать папку ISM-KR с исходными данными и алгоритмическим обеспечением контрольной работы в персональную папку студента ФИО. Формирование индивидуальных исходных данных Номер варианта исходных данных соответствует номеру компьютера, на котором работает студент. Для того, чтобы сформировать индивидуальные исходные данные, необходимо: 1. открыть рабочий файл ИСМ-КР. хls с исходными данными, находящийся в папке ISM-KR; 2. ввести номер варианта в ячейку H2 Рабочего файла ИСМ-КР.хls, в результате чего Excel сформирует исходные данные варианта.
Алгоритмическое обеспечение контрольной работы Постановка задачи Построение многофакторной линейной регрессионной модели зависимости объема продаж с помощью инструмента Регрессия надстройки Пакет анализа Алгоритмы выполнения задачи Алгорит.1. Расчет параметров уравнения линейной регрессии и проверки адекватности модели исходным данным 1. Сервис => Анализ данных => Регрессия => ОК; 2. Входной интервал Y <= диапазон ячеек табл. 1 со значениями о бъема продаж (Е4:Е33); 3. Входной интервал X – диапазон ячеек табл. 1 со значениями факторных признаков (В4:D33); 4. Метки в первой строке/Метки в первом столбце – НЕ активизировать; 5. Уровень надежности <= 68,3 (или 68.3); 6. Константа – ноль – НЕ активизировать; 7. Выходной интервал <= адрес ячейки заголовка первого столбца первой выходной результативной таблицы (А38); 8. Новый рабочий лист и Новая рабочая книга – НЕ активизировать; 9. Остатки – НЕ активизировать; 10. Стандартизованные остатки – НЕ активизировать; 11. График остатков – НЕ активизировать; 12. График подбора – НЕ активизировать; 13. График нормальной вероятности – НЕ активизировать; ОК. В результате указанных действий осуществляется вывод трех выходных таблиц (таблицам необходимо присвоить номера Табл.2 – Табл.4), начиная с ячейки, указанной в поле Выходной интервал диалогового окна инструмента Регрессия (пример структуры выходных таблиц приведен на рис. 1). Таблица 2
Таблица 3
Таблица 4
Рис.1. Структура выходных таблиц Рассчитанные в сгенерированных таблицах коэффициенты регрессии позволяют построить уравнение, выражающее зависимость объема продаж от факторных признаков: У=а0+а1Х1+а2Х2+а3Х3 Однако после получения результативных таблиц необходимо сначала провести анализ адекватности построенной линейной регрессионной модели. Анализ адекватности регрессионной модели преследует цель оценить, насколько построенная теоретическая модель взаимосвязи признаков отражает фактическую зависимость между этими признаками. Оценка соответствия построенной регрессионной модели исходным (фактическим) значениям признаков выполняется в 4 этапа: 1) оценка статистической значимости коэффициентов уравнения а0, а1, а2, а3 и определение их доверительных интервалов для заданного уровня надежности; 2) определение практической пригодности построенной модели на основе оценок линейного коэффициента корреляции r и индекса детерминации R2; 3) проверка значимости уравнения регрессии в целом по F -критерию Фишера; 4) оценка погрешности регрессионной модели. Для анализа коэффициентов а0, а1, а2, и а3 линейного уравнения регрессии используется табл.4, в которой: – значения коэффициентов а0, а1, а2, и а3 приведены в ячейках В54 и В57 соответственно; – рассчитанный уровень значимости коэффициентов уравнения приведен в ячейках Е54 и Е57; – доверительные интервалы коэффициентов с уровнем надежности Р=0,95 и Р=0,683 указаны в диапазоне ячеек F54:I57. 1. Определение значимости коэффициентов уравнения Уровень значимости – это величина α; =1– Р, где Р – заданный уровень надежности (доверительная вероятность). Режим работы инструмента Регрессия использует по умолчанию уровень надежности Р=0,95. Для этого уровня надежности у ровень значимости равен α = 1 – 0,95 = 0,05. Этот уровень значимости считается заданным. В инструменте Регрессия надстройки Пакет анализа для каждого из коэффициентов а0, а1, а2, и а3 вычисляется у ровень его значимости αр, который указан в результативной таблице (Табл.4термин "Р- значение "). Если рассчитанный для коэффициентов а0, а1, а2, и а3 уровень значимости αр, меньше заданного уровня значимости α;= 0,05, то этот коэффициент признается неслучайным (т.е. типичным для генеральной совокупности), в противном случае – случайным. Если один или несколько коэффициентов а1, а2, и а3 признается случайными, то соответствующие им факторы необходимо исключить. Для этого необходимо скопировать Лист 1 Рабочего файла на Лист 1(2) по следующему алгоритму. Алгоритм 2. Копирование Листа 1 Рабочего файла на Лист 1(2). 1. Подвести курсор к закладке Лист 1 щелкнуть правой клавишей мыши; 2. В появившемся падающем меню выбрать пункт Переместить/Скопировать; 3. В появившемся диалоговом окне 1. в поле перед листом выбрать (переместить в конец); 2. поле Создавать копию – Активизировать ; ОК. В созданном Листе 1(2) удалить столбцы с данными, соответствующие факторам, признанными случайными и выполнить Алгоритм 1 без учета этих факторов (для этого необходимо в Алгоритме 1 изменить следующие пункты: 2. Входной интервал Y <= диапазон ячеек табл. 1 со значениями о бъема продаж); 3. Входной интервал X – диапазон ячеек табл. 1 со значениями факторных признаков. После чего выполнить п. 1. Определение значимости коэффициентов уравнения для полученного нового уравнения регрессии. В случае, если признается случайным свободный член а0, то уравнение регрессии целесообразно построить заново без свободного члена а0. Для этого необходимо: 1. скопировать Лист 1(2) Рабочего файла нановый Лист 1(3) по описанному выше Алгоритму 2; 2. выполнить Алгоритм 1, задав в диалоговом окне Регрессия те же самые параметры, за исключением параметра Константа-ноль, который следует Активизировать (это означает, что модель будет строиться при условии а0=0). Доверительные интервалы коэффициентов а0, а1, а2, и а3 построенного уравнения регрессии при уровнях надежности Р=0,95 и Р = 0,683 представлены в выходной табл.4 в диапазоне ячеек F54:I56. 2. Определение практической пригодности построенной регрессионной модели. Практическую пригодность построенной линейной регрессионной модели можно охарактеризовать по величине линейного коэффициента корреляции r. Близость Пригодность построенной регрессионной модели для практического использования можно оценить и по величине индекса детерминации R2, показывающего, какая часть общей вариации признака Y объясняется в построенной модели вариацией факторов X1, Х2 Х3. В основе такой оценки лежит равенство R = r (имеющее место для линейных моделей связи), а также шкала Чэддока, устанавливающая качественную характеристику тесноты связи в зависимости от величины r. Согласно шкале Чэддока высокая степень тесноты связи признаков достигается лишь при Значение индекса детерминации R2 приводится в табл.2 в ячейке В42 (термин " R - квадрат "). 3. Общая оценка адекватности регрессионной модели по F-критерию Фишера Адекватность построенной регрессионной модели фактическим данным устанавливается по критерию Р.Фишера, оценивающему статистическую значимость (неслучайность) индекса детерминации R2. Значение множественного коэффициента детерминации R2показывает зависимость общей вариации результативного признака от вариаций факторных признаков. Рассчитанная для уравнения регрессии оценка значимости R2 приведена в табл. 3 в ячейке F49 (термин " Значимость F "). Если она меньше заданного уровня значимости α; = 0,05, то величина R2 признается неслучайной и, следовательно, выбранные факторы существенно влияют на объем продаж.
4. Оценка погрешности регрессионной модели Погрешность регрессионной модели можно оценить по величине стандартной ошибки Погрешность регрессионной модели выражается в процентах и рассчитывается как величина В адекватных моделях погрешность не должна превышать 12%-15%. Значение Значение
|
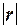 к единице свидетельствует о хорошей аппроксимации исходных (фактических) данных с помощью построенной линейной функции связи.
к единице свидетельствует о хорошей аппроксимации исходных (фактических) данных с помощью построенной линейной функции связи.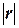 >0,7, т.е. при
>0,7, т.е. при  >0,7. Для индекса детерминации R2 это означает выполнение неравенства R2 >;0,5.
>0,7. Для индекса детерминации R2 это означает выполнение неравенства R2 >;0,5. построенного линейного уравнения регрессии. Величина ошибки
построенного линейного уравнения регрессии. Величина ошибки  исходных (фактических) значений yi признака Y от его теоретических значений
исходных (фактических) значений yi признака Y от его теоретических значений 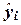 , рассчитанных по построенной модели.
, рассчитанных по построенной модели. .
. рассчитано с ячейке Е35.
рассчитано с ячейке Е35. 


