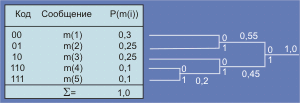
Статический алгоритм ХаффменаОдин из первых алгоритмов эффективного кодирования информации был предложен Хаффманом в 1952 году. Идея алгоритма состоит в следующем: зная вероятности вхождения символов в сообщение, можно описать процедуру построения кодов переменной длины, состоящих из целого количества битов. Символам с большей вероятностью присваиваются более короткие коды. Коды Хаффмена имеют уникальный префикс, что и позволяет однозначно их декодировать, несмотря на их переменную длину. Статический алгоритм Хаффмена можно считать классическим. Пример: Пусть сообщения m(1),…,m(n) имеют вероятности P(m(1)),… P(m(n)) и пусть для определенности они упорядочены так, что P(m(1)) ³ P(m(2)) ³ … ³ P(m(N)). Пусть x1,…, xn – совокупность двоичных кодов и пусть l1, l2,…, lN – длины этих кодов. Задачей алгоритма является установление соответствия между m(i) и xj. Можно показать, что для любого ансамбля сообщений с полным числом более 2 существует двоичный код, в котором два наименее вероятных кода xN и xN-1 имеют одну и ту же длину и отличаются лишь последним символом: xN имеет последний бит 1, а xN-1 – 0. Редуцированный ансамбль будет иметь свои два наименее вероятные сообщения, сгруппированными вместе. После этого можно получить новый редуцированный ансамбль и так далее. Процедура может быть продолжена до тех пор, пока в очередном ансамбле не останется только два сообщения. Процедура реализации алгоритма сводится к следующему (см. рис. 2.6.5.1). Сначала группируются два наименее вероятные сообщения, предпоследнему сообщению ставится в соответствие код с младшим битом, равным нулю, а последнему – код с единичным младшим битом (на рисунке m(4) и m(5)). Вероятности этих двух сообщений складываются, после чего ищутся два наименее вероятные сообщения во вновь полученном ансамбле (m(3) и m`(4); p(m`(4)) = p(m(4)) + P(m(5))).
Рис. 2.6.5.1 Пример реализации алгоритма Хафмана На следующем шаге наименее вероятными сообщениями окажутся m(1) и m(2). Кодовые слова на полученном дереве считываются справа налево. Алгоритм выдает оптимальный код (минимальная избыточность). При использовании кодирования по схеме Хаффмена надо вместе с закодированным текстом передать соответствующий алфавит. При передаче больших фрагментов избыточность, сопряженная с этим не может быть значительной. Для одного и того же массива бит могут быть сформированы разные алфавиты, но они будут одинаково оптимальными (среднее число бит, приходящихся на один символ для любого такого алфавита, будет идентичным). Таким образом, коды Хаффмена являются оптимальным (наиболее экономным), но не единственным решением. Возможно применение стандартных алфавитов (кодовых таблиц) для пересылки английского, русского, французского и т.д. текстов, программных текстов на С++, Паскале и т.д. Кодирование при этом не будет оптимальным, но исключается статистическая обработка пересылаемых фрагментов и отпадает необходимость пересылки кодовых таблиц. Ниже в таблице представлена таблица возможных кодов Хаффмена для английского алфавита.
Ниже представлена аналогичная таблица для русского алфавита. В этой таблице коды букв Е и Ё идентичны, аналогичная сутуация с кодами Ь и Ъ. Следует также иметь в виду, что помимо букв определенные коды должны быть присвоены символам пунктуации, числам и некоторым специальным символам (1 2 3 4 5 6 7 8 9 0.,:;!?... ' " ~ % # * + - = \ () [ ] { } _).
Методы сжатия информации
|