Головна сторінка Випадкова сторінка
КАТЕГОРІЇ:
АвтомобіліБіологіяБудівництвоВідпочинок і туризмГеографіяДім і садЕкологіяЕкономікаЕлектронікаІноземні мовиІнформатикаІншеІсторіяКультураЛітератураМатематикаМедицинаМеталлургіяМеханікаОсвітаОхорона праціПедагогікаПолітикаПравоПсихологіяРелігіяСоціологіяСпортФізикаФілософіяФінансиХімія
Глава 3. Функціонування єдиної державної системи цивільного захисту
Дата добавления: 2015-10-15; просмотров: 596
|
|
Регресійний аналіз вивчає вплив на значення досліджуваної (залежної) змінної значень однієї або кількох незалежних змінних.
Кореляційний аналіз досліджує характер і ступінь взаємозалежності факторів, які впливають на досліджувану змінну. Результати регресійно-кореляційного аналізу використовують для прогнозування найімовірнішого значення досліджуваної змінної для різних значень факторів, які на неї впливають.
На практиці регресійно-кореляційний аналіз полягає в пошуку (методами математичної статистики) оцінок числових характеристик системи випадкових величин. Тому він потребує ґрунтовного ознайомлення з основними поняттями теорії ймовірності.
Предмет теорії ймовірності — це специфічні закономірності масових однорідних випадкових явищ.
Випадковим називають явище, яке при неодноразовому відтворенні одного й того самого досліду (за незмінних основних найвпливовіших умов) відбувається кожного разу дещо по-іншому (через вплив багатьох другорядних факторів).
Елементарна подія — це можливий результат досліду, подія — це довільна підмножина множини елементарних подій.
Імовірність події - це чисельна міра об'єктивної можливості виникнення події (тобто однієї з її елементарних подій) у результаті досліду.
Відносна частота ймовірної події — це частота виникнення події в серії дослідів.
Безпосереднє обчислення ймовірності (виходячи з умов досліду, що відзначається симетрією через об'єктивно однакову можливість усіх випадків) можливе тільки для так званої схеми випадків, коли групі подій притаманні одночасно три властивості: утворюють повну групу подій, несумісні в кожному досліді й рівноможливі.
Випадок називають сприятливим для події, якщо його поява спричинює появу цієї події.
Тільки для "схеми випадків" правильним є "класичне" позначення ймовірності події А через Р(А)= т/п, тобто як відношення кількості сприятливих для події А випадків до загальної кількості всіх випадків.
Випадкова величина (далі в.в.) — це функція, яка кожній елементарній події ставить у відповідність деяке число. Розрізняють в.в. дискретні (набувають значення лише з деякої зліченної множини) та неперервні (можуть набувати будь-якого значення з інтервалу значень).
Закон розподілу в.в. встановлює зв'язок між можливими значеннями в.в. і відповідними їм ймовірностями.
Закон розподілу дискретної в.в. А найкраще описувати рядом розподілу, який у табличній формі задає ймовірність Р(Х = хп) =рп того, що X= хп. При цьому р1 + ... +рп = 1. Графічну версію ряду розподілу називають многокутником розподілу.
Для опису закону розподілу неперервної в.в. використовують функцію розподілу. Функція розподілу F задається співвідношенням F(x) = P(X<x).
Якщо функція розподілу диференційована, то для опису розподілу зручніше використовувати щільність розподілу f. Щільність розподілу — це перша похідна функції розподілу, f(x)=F'(x). Графік щільності розподілу називають кривою розподілу.
Наведені форми запису закону розподілу вичерпно характеризують в.в. На жаль, на практиці отримати ці форми дуже важко, як правило, навіть неможливо. Тому зазвичай шукають лише числові характеристики розподілу, які визначають його найістотніші особливості.
Найвідоміші такі числові характеристики;
• математичне сподівання тх — зважене ймовірностями середнє значення в.в.;
• мода Mod — найімовірніше значення в.в. X;
• медіана Med — значення в.в. X, для якого Р(Х < Med) = Р(Х >> Med);
• дисперсія Dx;
• середпьоквадратичне відхилення х;
• початкові vx і центральні mх моменти k:-го порядку.Математичне сподівання тх в.в. Xрозраховують за формулами:
тх =М[Х] = x1p1 + ... + хпрп для дискретної в.в.;
 для неперервної в.в.
для неперервної в.в.
Центрована випадкова величина — це різниця між в.в. X та її математичним сподіванням m (тобто Xc = X - mx); вона описує розподіл відхилень в.в. від її сподіваного значення.
Дисперсія Dx в.в. X— це математичне сподівання квадрата її центрованої в.в., тобто
Dx = D[X] = М[XС2] = М[(Х - тx)2] =M[Х2] - т2x.;
Середньоквадратичне (стандартне) відхилення а — це квадратний корінь з дисперсії (Dx)1/2. При цьому Середньоквадратичне відхилення має розмірність в.в. і є зручнішим для опису розсіювання значень навколо математичного сподівання, ніж дисперсія.
Початковий момент Vx k-ro порядку в.в. X—це математичне сподівання k-го степеня цієї в.в., тобто
vx = M[Xk]=x1kp1+...+ xnkpk, або 
Центральний момент μx k-го порядку в.в. X— це математичне сподівання k-то степеня її центрованої в.в., тобто
μx= М[(Xc)k] = M[(Х-mx)k] = (x1 -m1)kp1 +... + (хn -mn)kpn, або 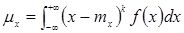
Можна показати, що
v1=mx,
μ1=mx,
μ2=v2-v12=Dx,
μ3=v3-3v2v1+2v13=Sxσ3 (де Sx=μ3/σ3 -асиметрія розподілу),
μ4=v4-4v3v1+6v2v12-3v14=Ex=(μ4/σ4) -3 (де Ех — ексцec розподілу).
Якщо результат досліду описується кількома в.в., то кажуть про систему випадкових величин. Властивості системи в.в. залежать не тільки від властивостей її складових, а й від можливого взаємозв'язку між ними.
Випадкові величини системи в.в. можуть бути або зовсім незалежні, або цілком (математично або функціонально) залежні, або мати імовірнісну (стохастичну) залежність.
Систему двох в.в. позначають (X,Y) і зображують на площині випадковою точкою або випадковим вектором.
Функцію розподілу системи двох в.в. (X, Y) позначають F(x,y), a щільність розподілу системи розраховують за формулою f(x,y)=(F'х)'у(х,у) =f1(x)f(y|x), де f1(x) — щільність розподілу в.в. X; f(y|x) -умовна щільність розподілу в.в. У за умови, що в.в. X набула значення X,
Випадкову величину Г називають незалежною від X, якщо умовна щільність не залежить від значення X, тобто f(y|x) =f2(y), де f2(у) -щільність розподілу в.в. Y. Для незалежної в.в. f(x,y) =f1(x)f2(y).
Кореляційний момент (коваріація) — це математичне сподівання добутку центрованих величин К = μ1,1 = M[XCYc] = М[(Х-mx)(Y-my)]. Недолік коваріації Kxy полягає в тому, що вона характеризує рівень взаємозалежності в.в. та їх розсіяння в сукупності. Отже, інформацію про рівень взаємозалежності з коваріації безпосередньо виділити неможливо. Тому використовують іншу характеристику — коефіцієнт кореляції.
Коефіцієнт кореляції характеризує рівень лінійної залежності двох в.в. і обчислюється за формулою rxy=Кxy/(σxσy), де σx, σy — се-редньоквадратичні відхилення. Для незалежних в.в. системи Кxy = 0 і rxy =0. Зазвичай -1≤rxy≤+1 і тільки при точній лінійній залежності  . Кореляція є додатною (rxy> 0) або від'ємною (rхy < 0), якщо при збільшенні однієї в.в. інша має тенденцію відповідно до збільшення або зменшення.
. Кореляція є додатною (rxy> 0) або від'ємною (rхy < 0), якщо при збільшенні однієї в.в. інша має тенденцію відповідно до збільшення або зменшення.
Наявність істотної кореляції і функціональну форму кореляції бачимо з графіка розподілу випадкових точок.
Однопараметрична лінійна регресія описується рівнянням Y = аХ +b.
Якщо досліджувана змінна в.в. К залежить від кількох незалежних змінних в.в. Хi, маємо багатопараметричну лінійну регресію з рівнянням типу Y = a1X1 + а2Х2 + ...+ апХп + b.
Нелінійна регресія (нелінійна залежність досліджуваної змінної від однієї або кількох незалежних змінних) може бути:
• поліноміальною (у=b + с1х + с2х2 + с3х3 + ... + сбх6);
• логарифмічною (у = сlnх + b);
• експоненціальною (у = сеbx);
• періодичною (у = nsinx).
Закон розподілу системи в.в. (у будь-якій формі) є вичерпним імовірнісним описом системи. Проте в перелічених далі випадках:
• недостатньо статистичного матеріалу,
• невиправдана важкість пошуку закону через невисокі вимоги до точності результатів,
• тип закону наперед відомий, а потрібні деякі параметри використовують приблизний опис системи в.в. за допомогою мінімальної кількості таких числових характеристик:
• п математичних очікувань (які характеризують середні значення в.в.) m1, m2,...,mn;
• п дисперсій (які характеризують розсіяння в.в.) D1,D2-.., Dn;
• п(п - 1) кореляційних моментів (які характеризують попарну кореляцію всіх величин системи) Kij = M[(Xc)i(Xc)j] =M[(Xi-mi)(Xj-mj)].
При цьому кореляційні моменти зручно розміщувати у вигляді прямокутної кореляційної матриці, на головній діагоналі якої розміщуються дисперсії. Через симетрію елементів матриці відносно головної діагоналі, як правило, заповнюють лише її верхню половину. Для некорельованих величин усі елементи кореляційної матриці (крім дисперсій у головній діагоналі) дорівнюють нулю.
Для п величин кореляційна матриця має такий вигляд:

для двох величин

Якщо потрібно знайти лише числові характеристики функції від випадкових величин (аргументів) за відомими числовими характеристиками аргументів, використовують такі співвідношення:
М[с] = 0; М[сХ] = сМ[Х]; М[Х + У]=M[Х] + М[У], D[c] = 0; D[cX] = C2D[X]; D[X+Y] = D[X] + D[Y] + 2Kxy.
Якщо Y = a1X1 +... +anXn+b, то M[У]=а1М[Х1] +... + anM[Xn]+b, D[Y] = a12D[X1] + ... + an2D[Xn] + 2Si<jaiajKij,
Точковою оцінкою параметра в математичній статистиці називають приблизне значення параметра, обчислене на основі обмеженої кількості дослідів. Бажано, щоб точкова оцінка була змістовною, ефективною і незміщеною. Наприклад, для дисперсії незміщена оцінка для вибірки (в Excel її повертає статистична функція ДИСП) і статистична оцінка для генеральної сукупності (в Excel її повертає статистична функція ДИСПР) задовольняють рівняння Dв=Dстn/(n-1).
| <== предыдущая лекция | | | следующая лекция ==> |
| Глава 2. Єдина державна система цивільного захисту та її складові | | | Глава 5. Сили цивільного захисту |