Головна сторінка Випадкова сторінка
КАТЕГОРІЇ:
АвтомобіліБіологіяБудівництвоВідпочинок і туризмГеографіяДім і садЕкологіяЕкономікаЕлектронікаІноземні мовиІнформатикаІншеІсторіяКультураЛітератураМатематикаМедицинаМеталлургіяМеханікаОсвітаОхорона праціПедагогікаПолітикаПравоПсихологіяРелігіяСоціологіяСпортФізикаФілософіяФінансиХімія
СЛОВОСПОЛуЧеННЯ. пі
Дата добавления: 2015-10-19; просмотров: 830
|
|
1 —да;
2 — нет;
3 — не помню.
При обработке данных опроса нам для проверки гипотезы необходимо сопоставить значения независимой переменной (возраст) с соответствующими им значениями зависимой переменной (участие или неучастие в выборах). С целью такого сопоставления мы после соответствующей обработки данных (вручную или с помощью компьютерного пакета SPSS) составляем табл. 4.14.
Таблица 4.14
Участие в выборах избирателей различных возрастов
| Возраст, годы | Участие в голосовании | Всего | |||
| нет ответа | да | нет | не помнят | ||
| 18-24 | |||||
| Процент построке | 34,8 | 58,7 | 6,5 | 9,2 | |
| Процентпо столбцу | 5,3 | 17,4 | 7,9 | ||
| 25-29 | |||||
| Процентпостроке | 54,5 | 32,7 | 12,7 | 11,0 | |
| Процент по столбцу | 10,0 | 11,6 | 18,4 | ||
| 30-39 | |||||
| Процент по строке | 3,1 | 59,8 | 27,8 | 9,3 | 19,4 |
| Процент по столбцу | 50,0 | 19,3 | 17,4 | 23,7 | |
| 40—49 | |||||
| Процент по строке | 0,9 | 65,2 | 27,8 | 6,1 | 23,0 |
| Процент по столбцу | 16,7 | 24,9 | 20,6 | 18,4 | |
| 50-59 | |||||
| Процент по строке | 64,9 | 27,0 | 8,1 | 14,8 | |
| Процент по столбцу | 15,9 | 12,9 | 15,8 | ||
| 60-70 | |||||
| Процент по строке | 70,0 | 25,7 | 4,3 | 14,0 | |
| Процентпостолбцу | 16,3 | 11,6 | 7,9 | ||
| Старше 70 | |||||
| Процент по строке | 4,7 | 58,1 | 30,2 | 7,0 | 8,6 |
| Процентпо столбцу | 33,3 | 8,3 | 8,4 | 7,9 | |
| Всего | |||||
| Процент | 1,2 | 60,2 | 31,0 | 7,6 | 100,0 |
Такая таблица называется «кросстаб»20, а процесс ее создания — «кросстабуляция». Это один из основных способов анализа, используемых для того, чтобы увидеть, какую связь переменные имеют друг с другом. Вообще говоря, категории независимой переменной могут размещаться как по строкам, так и по столбцам (или, что то же самое, — графам) кросстаба. Обычно независимую переменную помещают в верхней части кросстаба, формируя таким образом столбцы из значений зависимой переменной. Однако на практике — чаще всего из соображений удобства — для наглядности и для того, чтобы уместить кросстаб на одной странице, его иногда конструируют так, чтобы сверху вниз шла переменная с большим числом категорий (т.е. значений, которые может принимать переменная). Реально, конечно, не имеет значения, как будет сконструирован кросстаб: имея независимую переменную в верхней части таблицы (по горизонтали) или сверху вниз (по вертикали). Главное — соблюсти правило: когда выбор сделан, процентные отношения в таблице должны вычисляться таким образом, чтобы проверить наличие связи. Давайте на примере кросстаба 17 посмотрим, как производится чтение таблицы — процесс, в ходе которого и выявляется наличие или отсутствие связи между переменными и ее параметры.
Прежде всего обратим внимание на крайний правый столбец и две нижние строки. Здесь сведены контрольные суммы. Смысл приведенных цифр таков: число в верхней правой ячейке гово- рит о том, что общее число опрошенных в возрасте от 18 до 24 лет составляет 46 человек; цифра в ячейке ниже сообщает, что это составляет 9,2% общей численности выборочного массива, (500 человек, которые и принимаются за 100%, — данные в клет-1 ках в правом нижнем углу таблицы); общее число опрошенных в возрасте от 25 до 29 лет — 55 человек, это составляет 11,0% общей численности выборочного массива и т.д. В самой нижней строке приведены контрольные суммы количества тех, кто дал различные ответы об участии в голосовании по всем возрастным группам. Так, общее число принимавших участие в голосовании («да») — 301 человек, что составляет 60,2% общего объема выборочного массива; тех, кто не принимал участие («нет»), было в выборочном массиве 155, или Ъ\%,\\ т.д. Две ячейки в нижнем правом углу указывают на общую численность участников опро-
са, которая принимается за 100% для обеих исследуемых переменных. Контрольные суммы позволяют убедиться, что в процессе обработки были учтены ответы всех без исключения категорий респондентов.
Отметим также, что в этой таблице мы привели для максимальной полноты распределение по возрастам и тех, кто вообще не дал в анкете ответа на данный вопрос (столбец под заголовком «нет ответа»), а также тех, кто не смог точно вспомнить факта своего участия или неучастия (столбец «не помнят»). Вообще говоря, содержимое этих столбцов не очень информативно, и в итоговом отчете их можно опустить (здесь они нужны скорее для того, чтобы убедиться, что сошлись контрольные суммы). Хотя порой знание о том, какое число (и какой процент) респондентов не дали ответа или в той или иной форме уклонились от него, бывает достаточно полезным — например, при анализе осведомленности респондентов или степени заинтересованности их в какой-то проблеме. Кроме того, следовало бы подвергнуть особому анализу обе категории (тех, кто не дал ответа, и тех, кто не помнит), если бы численность их оказалась статистически значимой.
Анализ проводят, отслеживая изменения значений зависимой переменной при переходе ее от одного значения к другому. В данном примере в качестве независимой переменной выступает возраст респондентов, в качестве зависимой — их электоральная активность (выражаемая участием либо неучастием в голосовании). Процедуру отслеживания изменений значения зависимой переменной можно проводить как по строкам, так и столбцам. Двигаясь по строкам, мы начинаем с первого значения независимой переменной (возраст) — 18—24 года. Мы видим, что здесь число принимавших участие в выборах заметно — более чем в 1,5 раза — меньше числа тех, кто не участвовал. Перейдя к следующей строке — 25—29 лет, мы убеждаемся, что в этой возрастной категории соотношение между числом участвовавших и не участвовавших противоположное: первых уже более чем в 2 раза больше. Это соотношение еще более возрастает при переходе к следующим возрастным категориям, хотя и несколько снижается для самой старшей группы избирателей (старше 70 лет). Это позволяет нам сделать выводы: 1) о наличии связи между независимой (возраст) и зависимой (участие в выборах) переменными; 2) о направлении этой связи, которая в данном случае является прямой или положительной, поскольку ее можно выразить следующим простым описанием: чем больше значения независимой переменной (воз-212
раст), тем больше значения зависимой переменной (процент участия в выборах).
Фактически, как мы видим, непосредственному анализу здесь подвергались далеко не все цифры, а лишь некоторые из них — те, которые можно было бы свести в сокращенном варианте в виде табл. 4.14а.
Таблица 4.14а
Соотношения участия в выборах и абсентеизма21 в различных возрастных группах
| Возраст, годы | Участвовали | Не участвовали |
| 18-24 | 34,8 | 58,7 |
| 25-29 | 54,5 | 32,7 |
| 30-39 | 59,8 | 27,8 |
| 40-49 | 65,2 | 27,8 |
| 50-59 | 64,9 | 27,0 |
| 60-70 | 70,0 | 25,7 |
| Старше 70 | 58,1 | 30,2 |
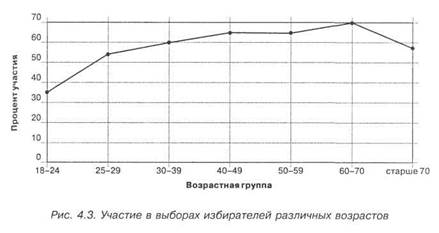
Данные, приведенные в табл. 4.14 и 4.14а и отраженные в виде графика на рис. 4.3, позволяют нам сделать следующие основные выводы: 1) существует отчетливо выраженная связь между возрастом избирателей и их электоральной активностью; 2) эта связь в основном положительная — чем больше возраст, тем выше процент участия представителей этой возрастной группы в голосов вании; исключение составляет лишь самая верхняя возрастная группа, где электоральная активность по вполне понятным причинам снижается. Второй из указанных выводов основан на правиле, определяющем направление связи: когда низкие значения одной переменной ассоциируются с низкими значениями дру-гой переменной (и наоборот), имеет место положительная связь; например, «чем выше уровень образования у кого-то, тем выше уровень его политического интереса». Когда низкие значения одной переменной ассоциируются с высокими значениями другой, между двумя переменными существует отрицательная связь; например, «чем выше чей-то доход, тем менее он либерален».
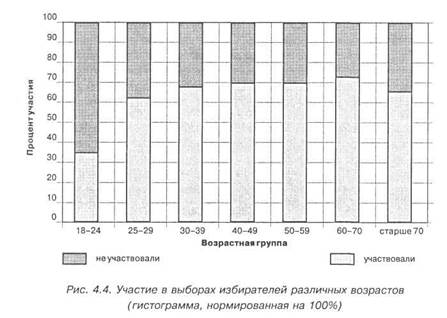
Мы могли бы построить графическое отображение и несколько иным способом — в виде распределения, нормированного на 213
100%, где в столбцах диаграммы отражена доля каждой из категорий в общей сумме (рис. 4.4).
Иногда для большей наглядности и убедительности анализа используют различные индексы. Это специально создаваемые показатели, с помощью которых связь между переменнными проявляется более зримо и отчетливо. Здесь должны прийти на помощь 214
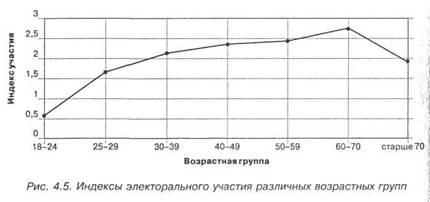
воображение и опыт. Мы могли бы, например, сконструировать по данным табл. 4.14а «индекс электорального участия», равный частному от деления числа принимавших участие в каждой из возрастных групп на число тех, кто не голосовал. Результаты отражены в табл. 4.146 и на рис. 4.5.
Таблица 4.146 | Индекс электорального участия в различных возрастных группах
| Возраст, годы | Индекс участия |
| 18-24 | 0,592845 |
| 25-29 | 1,666667 |
| 30-39 | 2,151079 |
| 40-49 | 2,345324 |
| 50-59 | 2,403704 |
| 60-70 | 2,723735 |
| Старше 70 | 1,923841 |
Нетрудно убедиться, что формы кривых на рис. 4.3 и 4.5 совершенно идентичны (та же зависимость), хотя значения на оси ординат иные. Мы могли бы построить индекс иначе (скажем, не разделив, а вычтя одно из другого) и убедиться, что результат был бы таким же.
Теперь представим себе, что данные опроса были бы принципиально иными, такими, например, как это представлено в гипотетической табл. 4.14в.
Вывод, который мы могли бы сделать из такого рода данных, сомнения не вызывает: связи между возрастом и электоральной активностью не наблюдается. При этом мы опираемся на прави-ло, сформулированное в предыдущей главе: нет изменения — нет связи.
Глава 4. Анализ эмпирических данных 215
Понятие силы связи имеет отношение к тому, насколько существенно различаются наблюдаемые значения зависимой переменной при изменении значений независимой переменной. Если, предположим, характер голосования одной категории избирателей (к примеру, мужчин) значительно отличается от характера голосования другой категории (женщин), тогда мы можем утверждать, что имеет место сильная связь между двумя переменными. Если степень различия в характере их голосования мала, имеет место слабая связь.
Таблица 4.14в
Соотношения участия в выборах и абсентеизма в различных возрастных группах (в процентах к численности каждой возрастной группы)
| Возраст, годы | Участвовали | Не участвовали |
| 18-24 | 59,8 | 27,8 |
| 25-29 | 59,8 | 27,8 |
| 30-39 | 59,8 | 27,8 |
| 40-49 | 59,8 | 27,8 |
| 50-59 | 59,8 | 27,8 |
| 60-70 | 59,8 | 27,8 |
| Старше 70 | 59,8 | 27,8 |
Источник: Гипотетические данные.
Наиболее сильная из возможных связей между двумя переменными — это такая связь, при которой значение зависимой переменной для каждого случая в одной категории независимой переменной отличается от каждого из случаев в другой категории. Такую связь называют совершенной, потому что зависимая переменная абсолютно ассоциируется с независимой переменной, не допуская никаких исключений. Совершенная связь между независимой и зависимой переменными дает исследователю возможность точно предсказать значение любого из случаев зависимой переменной, если известно значение независимой. Пример совершенной связи для гипотетического случая различий в голосовании приведен в табл. 4.14г. Между переменными может существовать как совершенная положительная, так и совершенная отрицательная связь, поскольку направление и сила — это разные свойства связи.
Строго говоря, в реальных распределениях социологических данных крайне редко встречаются как совершенная связь, так и абсолютно полное отсутствие связи. Фактически отсутствие связи выражается в слабости связи. Слабой можно было бы считать такую связь, при которой различия наблюдаемых значений зависимой перемен-216
ной для различных категорий независимой переменной незначительны. Фактически наиболее слабая связь — это такая, в которой распределение было бы идентично для всех категорий независимой переменной — другими словами, связь просто отсутствует.
Таблица 4.14г
Различия в голосовании за различных кандидатов в зависимости от пола избирателей
| Кандидат | Голосование(%) | |
| Мужчины | Женщины | |
| Иванов | ||
| Петрова | ||
| Всего |
Источник: Гипотетические данные.
Пример из социологической практики.Американские социологи Раймонд Уолфингер и Стивен Розенстоун в своем анализе причин, J. по которым люди голосуют, использовали анализ кросстаба для про- ■ верки гипотезы, что чем выше уровень образования индивида, тем сбольшей вероятностью он примет участие в голосовании. Табл. 4.15 позволяет прийти к следующим выводам: 1) связь между образова- .; нием и явкой избирателя на выборы реально существует; 2) направление ее таково, как определяет гипотеза; 3) связь довольно сильная. Это хороший пример кросстаба с независимой переменной, разме- * щенной сверху вниз таблицы, поскольку она включает много кате- i горий. В этом случае процентные отношения размешаются по стро- \ кам, а сравнение проводится вниз по столбцам.
Таблица 4.15
Связь между образованием иявкой на выборы
| Число лет образования (независимая переменная) | Явка на выборы (зависимая переменная) | ||
| Голосовали{%) | Не голосовали(%) | Общая доля в выборке (%) | |
| 0-4 года | |||
| 5-7лет | |||
| 8 лет | |||
| 9-11 лет | |||
| 12 лет | |||
| 1-3 года колледжа | |||
| 4 года колледжа | |||
| Sлетколледжа |
Довольно часто используемым показателем силы связи выступают различные коэффициенты корреляции22. Корреляция указывает на степень статистической взаимосвязи признаков. Одним из индексов такого рода при использовании порядковой шкалы измерения выступает коэффициент ранговой корреляции Спирмена, названный так по имени американского психолога Чарльза Спирмена, который использовал его в своих исследованиях вместо обычных коэффициентов корреляции. Формула расчета его имеет следующий вид:

где dj — разность рангов; /— общее число сопоставляемых пар.
Понятно, что коэффициент ранговой корреляции Спирмена будет равен +1 (абсолютная положительная связь), если ответы респондентов анализируемых групп будут в точности совпадать; он будет равен -1 (абсолютная отрицательная связь), если ответы всех респондентов обеих анализируемых групп будут прямо противоположны; если rs = 0, то это означает полное отсутствие всякой связи.
Строго говоря, коэффициент ранговой корреляции показывает, насколько одинаковыми или различными оказываются ответы на один и тот же вопрос со стороны двух сравниваемых между собою групп респондентов. Рассмотрим процедуру расчета rs на примере данных исследования о стереотипах сексуального поведения. Респондентов просили высказать степень своего согласия (выразив это в баллах от 5 — «полностью согласен», до 1 — «совершенно не согласен») с целым рядом суждений, связанных с теми или иными сторонами интимной жизни. После расчетов среднего значения были получены следующие результаты(табл. 4.16).
После ранжировки по степени согласия с тем или иным суждением таблица приобретет несколько иной вид (табл. 4.16а). Рассчитав величину для каждого из значений, возведя ее в квадрат, а затем сложив, мы можем проделать в соответствии с формулой (4.2) следующую процедуру для расчета коэффициента корреляции:
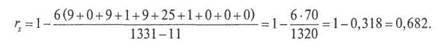
| Таблица 4.16 Степень согласия с суждениями (в средних значениях по 5-балльной шкале) | |||||
| Суждение | Мужчины | Женщины | |||
| Инициатива в интимных отношениях должна принадлежать юношам | 3,42 | 3,55 | |||
| Если девушка в 18—20 лет невинна, то, скорее всего, она никому не нужна | 1,58 | 1,57 | |||
| Без секса жизнь неинтересна | 3,77 | 3,03 | |||
| Любовь бывает исключительно в книгах, в фильмах, а в жизни—только секс | 2,12 | 1,76 | |||
| Верю, что в жизни у меня будет (есть) настоящая любовь | 3,88 | 3,91 | |||
| Девушка, ведущая беспорядочную половую жизнь, останется несчастной и одинокой | 3,04 | 3,03 | |||
| Курение и алкоголь — злейшие враги сексуальности | 3,42 | 3,79 | |||
| Прежде чем вступить в брак, надо проверить, подходитлитебе человек в сексуальном отношении | 4,19 | 3,33 | |||
| Без любви не стоит заниматься сексом | 2,75 | 3,45 | |||
| Наличие денег играет большую роль в выборе сексуального партнера | 2,37 | 2,64 | |||
| Интимная близость — это соединение, в первую очередь, не половых органов, а любящих душ | 3,62 | 4,22 | |||
| Таблица 4.16а | |||||
| Суждение | Мужчины | Женщины | d | d* | |
| Интимная близость — это соединение, в первую очередь, не половых органов, а любящих душ | |||||
| Верю, что в жизни у меня будет (есть) настоящая любовь | |||||
| Курение и алкоголь — злейшие враги сексуальности | |||||
| Инициатива в интимных отношениях должна принадлежать юношам | |||||
| Без любви не стоит заниматься сексом | |||||
| Прежде чем вступить в брак, надо проверить, подходитлитебе человек в сексуальном отношении | -5 | ||||
| Без секса жизнь неинтересна | |||||
| Девушка, ведущая беспорядочную половую жизнь, останется несчастной и одинокой | -1 | ||||
| Наличие денег играет большую роль в выборе сексуального партнера | |||||
| Любовь бывает исключительно в книгах, в фильмах, а в жизни — только секс | |||||
| Если девушка в 18-20 лет невинна, то, скорее всего, она никому не нужна | |||||
Это довольно высокий уровень корреляции, указывающий на относительную близость взглядов мужчин и женщин по всему комплексу приведенных суждений (несмотря на существенные расхождения по отдельным позициям).
Глава 5. ТАБЛИЧНОЕ И ГРАФИЧЕСКОЕ ПРЕДСТАВЛЕНИЕ ДАННЫХ1
Таблицы и графики — одно из самых гениальных изобретений человеческой мысли, стремившейся выразить через образный видеоряд сухие колонки цифр и фактов. Во всех странах мира таблица считается наиболее наглядной и компактной формой представления статистического материала.
Табличное и графическое оформление социологических данных — это всегда завершающий этап эмпирического исследования. Закончена полевая стадия, в ходе опроса (или наблюдения, анализа документов) вы использовали анкеты, бланки, карточки, проверили правильность их заполнений. Теперь собранные сведения надо проанализировать. Инструментальная фаза позади, а впереди — аналитическая. Сейчас вам предстоят еще три важных и ответственных этапа — обработка данных, их анализ2 и составление итогового аналитического отчета.
| <== предыдущая лекция | | | следующая лекция ==> |
| УМІННЯ ОРІЄНТУВАТИСЯ В УМОВАХ СПІЛКУВАННЯ | | | УМІННЯ ЗБИРАТИ МАТЕРІАЛ ДЛЯ ВИСЛОВЛЮВАННЯ |