Головна сторінка Випадкова сторінка
КАТЕГОРІЇ:
АвтомобіліБіологіяБудівництвоВідпочинок і туризмГеографіяДім і садЕкологіяЕкономікаЕлектронікаІноземні мовиІнформатикаІншеІсторіяКультураЛітератураМатематикаМедицинаМеталлургіяМеханікаОсвітаОхорона праціПедагогікаПолітикаПравоПсихологіяРелігіяСоціологіяСпортФізикаФілософіяФінансиХімія
Практична робота № 2
Дата добавления: 2015-09-19; просмотров: 736
|
|
Основным элементом, из совокупности которых складывается статистическая модель, является одна случайная реализация моделируемого явления, например, «один случай работы машины до ее отказа», «один день работы промышленного цеха», «одна эпидемия» и т. д. Реализация — это как бы один «экземпляр» случайного явления со всеми присущими ему случайностями. Реализации отличаются друг от друга за счет этих случайностей.
Отдельная реализация разыгрывается с помощью специально разработанной процедуры (алгоритма), в которой важную роль играет «бросание жребия». Каждый раз, когда в ход явления вмешивается случай, его влияние учитывается не расчетом, а жребием.
Поясним понятие «жребия». Пусть в ходе процесса наступил момент, когда его дальнейшее развитие (а значит и результат) зависит от того, произошло или нет какое-то событие А? Например, попал ли в цель снаряд? Исправна ли аппаратура? Обнаружен ли объект? Устранена ли неисправность? Тогда нужно «бросанием жребия» решить вопрос: произошло событие или нет. Как можно осуществить этот жребий? Нужно привести в действие какой-то механизм случайного выбора (например, бросание монеты или игральной кости, или же вынимание жетона с цифрой из вращающегося барабана, или выбор наугад какого-то числа из таблицы). Нам хорошо знакомы некоторые механизмы случайного выбора (например, «пляска шариков» перед объявлением выигравших номеров «Спортлото»). Если жребий бросается для того, чтобы узнать, произошло ли событие А, его нужно организовать так, чтобы условный результат розыгрыша имел ту же вероятность, что и событие А. Как это делается—мы увидим ниже. Кроме случайных событий, на ход и исход операции могут влиять различные случайные величины, например: время до первого отказа технического устройства; время обслуживания заявки каналом СМО; размер детали; вес поезда, прибывающего на участок пути; координаты точки попадания снаряда и т. п. С помощью жребия можно разыграть и значение любой случайной величины, и совокупность значений нескольких.
Условимся называть «единичным жребием» любой опыт со случайным исходом, который отвечает на один из следующих вопросов:
1. Произошло или нет событие A?
2. Какое из событий А1, А2, ..., Ak произошло?
3. Какое значение приняла случайная величина X?
4. Какую совокупность значений приняла система случайных величин X1, Х2, ..., Хk?
Любая реализация случайного явления методом Монте-Карло строится из цепочки единичных жребиев, перемежающихся с обычными расчетами. Ими учитывается влияние исхода жребия на дальнейший ход событий (в частности, на условия, в которых будет разыгран следующий жребий).
Единичный жребий может быть разыгран разными способами, но есть один стандартный механизм, с помощью которого можно осуществить любую разновидность жребия. А именно, для каждой из них достаточно уметь получать случайное число R, все значения которого от 0 до 1 равновероятны[2]). Условимся кратко называть величину R— «случайное число от0до1». Покажем, что с помощью такого числа можно разыграть любой из четырех видов единичного жребия.
1. Произошло или нет событие А? Чтобы ответить на этот вопрос, надо знать вероятность р события А. Разыграем случайное число R от 0 до 1, и если оно
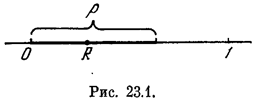 оказалось меньше р, как
оказалось меньше р, как
показано на рис. 23.1,
будем считать, что событие произошло, а если больше р — не произошло.
А как быть,— спросит читатель,— если число R оказалось в точности равным р? Вероятностью такого совпадения можно пренебречь. А уж если оно случилось, можно поступать как угодно: или всякое «равно» считать за «больше», или за «меньше», или попеременно за то и другое — от этого результат моделирования практически не зависит.
2. Какое из нескольких событий появилось? Пусть события А1, А2,...,Ak несовместны и образуют полную группу. Тогда сумма их вероятностей р1, р2,...,рk равна единице. Разделим интервал (0, 1) на k участков длиной р1,р2,...,рk (рис. 23.2). На какой из участков попало число R — то событие и появилось.
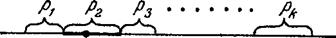
0 R 1
Рис. 23.2.
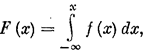 Какое значение приняла случайная величина X? Если случайная величина Xдискретна, т. е. имеет значения Х1, Х2, . . ., хk С вероятностями р1, р2,...,рk, ТО, очевидно, случай сводится к предыдущему. Теперь рассмотрим случай, когда случайная величина непрерывна и имеет заданную плотность вероятности f(x). Чтобы разыграть ее значение, достаточно осуществить следующую процедуру: перейти от плотности вероятности f(x) к функции распределения F(x) по формуле
Какое значение приняла случайная величина X? Если случайная величина Xдискретна, т. е. имеет значения Х1, Х2, . . ., хk С вероятностями р1, р2,...,рk, ТО, очевидно, случай сводится к предыдущему. Теперь рассмотрим случай, когда случайная величина непрерывна и имеет заданную плотность вероятности f(x). Чтобы разыграть ее значение, достаточно осуществить следующую процедуру: перейти от плотности вероятности f(x) к функции распределения F(x) по формуле
(23.1)
затем найти для функции F обратную ей функцию Ψ.
Затем разыграть случайное число R от 0 до 1 и взять от него эту обратную функцию:
X= Ψ(R). (23.2)
Можно доказать (мы этого делать не будем), что полученное значение X имеет как раз нужное нам распределение f(x).
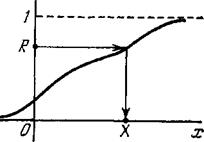 Графически процедура розыгрыша значения X показана на рис. 23.3. Разыгрывается число R от 0 до 1 и для него ищется такое значение X, при котором F(X) = R
Графически процедура розыгрыша значения X показана на рис. 23.3. Разыгрывается число R от 0 до 1 и для него ищется такое значение X, при котором F(X) = R
*= R (это показано стрелками
на рис. 23.3).
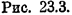 На практике часто приходится разыгрывать значение случайной величины, имеющей нормальное распределение. Для нее, как для любой непрерывной случайной величины, правило розыгрыша (23.2) остается справедливым, но
На практике часто приходится разыгрывать значение случайной величины, имеющей нормальное распределение. Для нее, как для любой непрерывной случайной величины, правило розыгрыша (23.2) остается справедливым, но
можно поступать и иначе (проще). Известно, что (согласно центральной предельной теореме теории вероятностей) при сложении достаточно большого числа независимых случайных величин с одинаковыми распределениями получается случайная величина, имеющая приближенно нормальное распределение. На практике, чтобы получить нормальное распределение, достаточно сложить шесть экземпляров случайного числа от 0 до 1. Сумма этих шести чисел
Z = R1 +R2 + ... + Rв (23.3)
имеет распределение, настолько близкое к нормальному, что в большинстве практических задач им можно заменить нормальное. Для того чтобы математическое ожидание и среднее квадратическое отклонение этого нормального распределения были равны заданным тх, х, нужно подвергнуть величину Z линейному преобразованию и вычислить
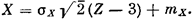 (23.4)
(23.4)
Это и будет нужная нам нормально распределенная случайная величина.
1. Какую совокупность значений приняли случайные величины Х1Х2,...,Хk? Если случайные величины независимы, то достаточно k раз повторить процедуру, описанную в предыдущем пункте. Если же они зависимы, то разыгрывать каждую последующую нужно на основе ее условного закона распределения при условии, что все предыдущие приняли те значения, которые дал розыгрыш (более подробно останавливаться на этом случае мы не будем).
Таким образом, мы рассмотрели все четыре варианта единичного жребия и убедились, что все они сводятся к розыгрышу (одно- или многократному) случайного числа R от 0 до 1.
Возникает вопрос: а как же разыгрывается это число R? Существует целый ряд разновидностей так называемых «датчиков случайных чисел», решающих эту задачу. Остановимся вкратце на некоторых из них.
Самый простой из датчиков случайных чисел — это вращающийся барабан, в котором перемешиваются перенумерованные шарики (или жетоны). Пусть, например, нам надо разыграть случайное число R от 0 до 1 c точностью до 0,001. Заложим в барабан 1000 перенумерованных шариков, приведем его во вращение и после остановки выберем первый попавшийся шарик, прочтем его номер и разделим на 1000.
Можно поступить и немного иначе: вместо 1000 шариков заложить в барабан только 10, с цифрами 0, 1, 2, ...,9. Вынув один шарик, прочтем первый десятичный знак дроби. Вернем его обратно, снова покрутим барабан и возьмем второй шарик — это будет второй десятичный знак и т. д. Легко доказать (мы этого делать не будем), что полученная таким образом десятичная дробь будет иметь равномерное распределение от 0 до 1. Преимущество этого способа в том, что он никак не связан с числом знаков, с которым мы хотим знать R.
Отсюда один шаг до рационализаторского предложения: не разыгрывать число R каждый раз, когда это понадобится, а сделать это заранее, т. е. составить достаточно обширную таблицу, в которой все цифры 0, 1, 2, ..9 встречаются случайным образом и с одинаковой вероятностью (частотой). До этого приема люди давно додумались: такие таблицы действительно составлены и применяются на практике. Они называются таблицами случайных чисел. Выдержки из таблиц случайных чисел приводятся во многих руководствах по теории вероятностей и математической статистике (например, [20]). Краткие выдержки из таблиц случайных чисел приведены и в популярной книжке автора [21], где, кстати, даны и примеры моделирования случайных процессов с помощью таблиц случайных чисел.
При ручном применении метода Монте-Карло таблицы случайных чисел — наилучший способ розыгрыша случайного числа R от 0 до 1. Если же моделирование осуществляется не вручную, а на ЭВМ, то пользование таблицами случайных чисел (как и вообще таблицами) нерационально — они слишком загрузили бы память. Для розыгрыша R на ЭВМ применяются специальные датчики, которыми оснащены многие вычислительные машины. Это могут быть как «физические датчики», основанные на преобразовании случайных шумов, так и вычислительные алгоритмы, по которым сама машина вычисляет так называемые «псевдослучайные числа». Приставка «псевдо» означает «как бы», «якобы». И в самом деле, числа, вычисляемые с помощью таких алгоритмов, фактически случайными не являются, но практически ведут себя как случайные; все значения от 0 до 1 встречаются в среднем одинаково часто и, кроме того, связь между последовательными значениями получаемых чисел практически отсутствует. Существует ряд алгоритмов вычисления псевдослучайных чисел, различающихся между собой по простоте, равномерности и другим признакам (см. [22]). Один из самых простых алгоритмов вычисления псевдослучайных чисел состоит в следующем. Берут два произвольных n-значных двоичных числа а1 и а2, перемножают их и в полученном произведении берут п средних знаков; это будет число а3. Затем перемножают а2 и а3, в произведении снова берут n средних знаков и т. д. Полученные таким образом числа рассматривают как последовательность двоичных дробей с п знаками после запятой. Такая последовательность дробей ведет себя практически как ряд значений случайного числа R от 0 до 1. Существуют и другие алгоритмы, основанные не на перемножении, а на «суммировании со сдвигом». Подробнее останавливаться на конкретных алгоритмах получения псевдослучайных чисел не имеет смысла: в настоящее время практически все ЭВМ cнабжены либо датчиками случайных чисел, либо проверенными алгоритмами вычисления псевдослучайных[3]).
§ 24. Определение характеристик стационарного случайного процесса по одной реализации
В исследовании операций нередко приходится встречаться с задачами, где случайный процесс продолжается достаточно долго в одинаковых условиях, и нас как раз интересуют характеристики этого процесса в предельном, установившемся режиме. Например, железнодорожная сортировочная станция работает круглосуточно, и интенсивность потока составов, прибывающих на нее, почти не зависит от времени. В качестве других примеров систем, в которых случайный процесс довольно быстро переходит в устойчивое состояние, можно назвать ЭВМ, линии связи, технические устройства, непрерывно эксплуатируемые и т. п.
О предельном, стационарном режиме и предельных (финальных) вероятностях состояний мы уже говорили в главе 5 (§ 17) в связи с марковскими случайными процессами. Существуют ли они для немарковских процессов? Да, в известных случаях существуют и не зависят от начальных условий. При решении вопроса о том, существуют ли они для данной задачи, можно в первом приближении поступать так: заменить мысленно все потоки событий простейшими; если для этого случая окажется, что финальные вероятности существуют, то они будут существовать и для немарковского процесса. Если это так, то для предельного, стационарного режима все вероятностные характеристики можно определить методом Монте-Карло не по множеству реализаций, а всего по одной, но достаточно длинной реализации. В этом случае одна длинная реализация дает такую же информацию о свойствах процесса, что и множество реализаций той же общей продолжительности.
 Пусть в нашем распоряжении — одна длинная реализация стационарного случайного процесса общей продолжительности Т. Тогда интересующие нас вероятности состояний можно найти, как долю
Пусть в нашем распоряжении — одна длинная реализация стационарного случайного процесса общей продолжительности Т. Тогда интересующие нас вероятности состояний можно найти, как долю
времени, которую система проводит в этих состояниях, а средние значения случайных величин получить усреднением не по множеству реализаций, а по времени, вдоль реализации.
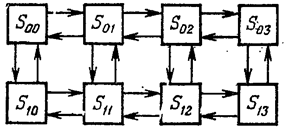
Рассмотрим пример. Моделируется методом Монте- Карло работа немарковской одноканальной СМО с очередью. Число мест в очереди ограничено двумя. Заявка, пришедшая в момент, когда оба места в очереди заняты, покидает СМО необслуженной (получает отказ). Время от времени канал может выходить из строя. Если канал вышел из строя, находившиеся в СМО заявки (как под обслуживанием, так и в очереди), не покидают СМО, а ожидают конца ремонта. Все потоки событий не простейшие, а произвольные рекуррентные. Возможные состояния СМО:
Soi — канал исправлен, в системе i заявок,
S1i — канал ремонтируется, в системе i заявок (i = 0, 1, 2, 3).
Граф состояний СМО показан на рис. 24.1. Из вида графа заключаем, что финальные вероятности существуют. Предположим, что моделирование работы СМО методом Монте-Карло на большом промежутке времени Т произведено. Требуется найти характеристики эффективности СМО: Рoтк — вероятность того, что заявка покинет СМО необслуженной, Риспр — вероятность того, что канал исправен, А — абсолютную пропускную способность СМО, Lсист — среднее число заявок в СМО, Lоч — среднее число заявок в очереди, Wсист и Wоч — среднее время пребывания заявки в системе и в очереди.
Сначала найдем финальные вероятности состояний p00, p01, p02, p03, p10, p11, p12, p13. Для этого нужно вдоль реализации подсчитать суммарное время, которое система находится в каждом из состояний: T00, T01, T02, T03, Т10, T11, Т12, T13, и разделить каждое из них на время Т. Получим:
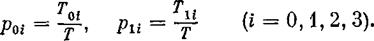
|
|
|
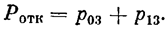 Вероятность отказа равна вероятности того, что заявка придет в момент, когда в СМО уже находятся три заявки:
Вероятность отказа равна вероятности того, что заявка придет в момент, когда в СМО уже находятся три заявки:
Абсолютная пропускная способность равна
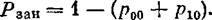
где λ — интенсивность потока заявок.
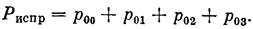 Вероятность того, что канал исправен, получим, суммируя все вероятности, у которых первый индекс равен нулю:
Вероятность того, что канал исправен, получим, суммируя все вероятности, у которых первый индекс равен нулю:
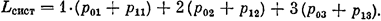 Среднее число заявок в СМО подсчитаем, умножая возможные числа заявок в СМО на соответствующие вероятности и складывая:
Среднее число заявок в СМО подсчитаем, умножая возможные числа заявок в СМО на соответствующие вероятности и складывая:
Это равносильно тому, как если бы мы отметили на оси времени отрезки, на которых в СМО находится 0, 1, 2, 3 заявки и суммарную длительность участков умножили соответственно на 1, 2, 3, сложили и разделили на T.
Среднее число заявок в очереди Loч получим, вычитая из Lсист среднее число заявок под обслуживанием (для одноканальной СМО это вероятность того, что канал занят):
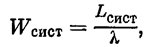
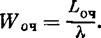
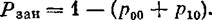
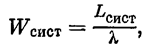 Среднее время пребывания заявки в системе и в очереди получим по формуле Литтла:
Среднее время пребывания заявки в системе и в очереди получим по формуле Литтла:
| |
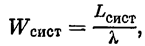 |
На этом мы заканчиваем краткое изложение метода Монте-Карло, отсылая интересующегося читателя к руководствам [6,22], где он изложен более полно и где, в частности, рассматривается вопрос о точности статистического моделирования.
ГЛАВА 8
| <== предыдущая лекция | | | следующая лекция ==> |
| Порядок виконання практичної роботи | | | Мета роботи |