Головна сторінка Випадкова сторінка
КАТЕГОРІЇ:
АвтомобіліБіологіяБудівництвоВідпочинок і туризмГеографіяДім і садЕкологіяЕкономікаЕлектронікаІноземні мовиІнформатикаІншеІсторіяКультураЛітератураМатематикаМедицинаМеталлургіяМеханікаОсвітаОхорона праціПедагогікаПолітикаПравоПсихологіяРелігіяСоціологіяСпортФізикаФілософіяФінансиХімія
Number these sentences from the message in the correct order. Use the flow chart in Exercise 7 to help you.
Дата добавления: 2015-10-18; просмотров: 514
|
|
В настоящее время применение концепции баз данных в распределенных системах является общепринятым. По мере развития таких систем постоянно возрастают сложность решаемых ими задач и объёмы обрабатываемой информации. При этом распределенные системы должны обладать средствами оперативной обработки больших объёмов информации. Современные тенденции развития информационной системы состоят в переходе от централизованных вычислительных систем к распределенным. Стратегии распределения данных по узлам сети диктуются как управленческими, так и производственными задачами конкретных химических производств.
Создание распределенных информационных систем является весьма актуальной задачей. Это связано с возрастающими потребностями в приложениях. Увеличиваются требования к оперативности и своевременности информации. Управление информацией происходит с помощью систем управления базами данных (СУБД). Для достижения высокой производительности распределенных приложений, работающих с базами данных, необходимы эффективные методы проектирования распределенных баз данных (РБД).
Для проектирования распределенных баз данных требуется решить следующие задачи:
1) состав хранимых данных;
2) перечень решаемых задач и необходимая для них условно-постоянная информация;
3) сведения о том, какие задачи, каким клиентом с ка- кой частотой используются.
Задача определения состава хранимых данных решается традиционными методами проектирования баз данных. Здесь необходимо определить все необходимые данные библиотеки. Определение перечня решаемых задач - это, по сути, первый этап жизненного цикла разработки программ согласно общепринятым методикам объектно-ориентированного анализа. Для решения третьей задачи необходима достоверная статистика частоты решения отдельных задач разными клиентами. По существу, решение третьей задачи - это известная в теории распределенных баз данных задача фрагментации и размещения данных [7, с.59].
Фрагментация данных допускает разбиение отношения на два или более сегмента или фрагмента. Каждый фрагмент может храниться на любом узле сети. Размещение данных представляет собой процесс принятия решения о месте хранения данных с целью минимизации целевой функции при выполнении запросов.
При возникновении изменений в инфраструктуре распределенной среды требуется репроектирование РБД для сохранения производительности приложений. Репроектирование приводит к возникновению новых схем фрагментации и размещения и влечет за собой необходимость материализации обновленного дизайна.
Проектирование баз данных происходит в четыре этапа.
На этапе формулирования и анализа требований устанавливаются цели организации, определяются требования к БД. Они состоят из общих требований, определенных в разделе 1, и специфических требований. Для формирования специфических требований обычно используется методика интервьюирования персонала различных уровней управления. Все требования документируются в форме, доступной конечному пользователю и проектировщику БД.
Этап концептуального проектирования заключается в описании и синтезе информационных требований пользователей в первоначальный проект БД. Исходными данными могут быть совокупность документов пользователя при классическом подходе или алгоритмы приложений (алгоритмы бизнеса) при современном подходе. Результатом этого этапа является высокоуровневое представление (в виде системы таблиц БД) информационных требований пользователей на основе различных подходов.
Сначала выбирается модель БД. Затем создается структура БД, которая заполняется данными с помощью систем меню, экранных форм или в режиме просмотра таблиц БД. Здесь же обеспечивается защита и целостность (в том числе ссылочная) данных с помощью СУБД или путем построения триггеров.
В процессе логического проектирования высокоуровневое представление данных преобразуется в структуру используемой СУБД. Основной целью этапа является устранение избыточности данных с использованием специальных правил нормализации. Цель нормализации – минимизировать повторения данных и возможные структурные изменения БД при процедурах обновления. Это достигается разделением (декомпозицией) одной таблицы в две или несколько с последующим использованием при запросах операции навигации. Заметим, что навигационный поиск снижает быстродействие БД, т.е. увеличивает время отклика на запрос. Полученная логическая структура БД может быть оценена количественно с помощью различных характеристик (число обращений к логическим записям, объем данных в каждом приложении, общий объем данных). На основе этих оценок логическая структура может быть усовершенствована с целью достижения большей эффективности.
Специального обсуждения заслуживает процедура управления БД. Она наиболее проста в однопользовательском режиме. В многопользовательском режиме и в распределенных БД процедура сильно усложняется. При одновременном доступе нескольких пользователей без принятия специальных мер возможно нарушение целостности. Для устранения этого явления используют систему транзакций и режим блокировки таблиц или отдельных записей.
Транзакция - процесс изменения файла, записи или базы данных, вызванный передачей одного входного сообщения. Особенности блокирования и варианты блокировки далее будут рассмотрены отдельно.
На этапе физического проектирования решаются вопросы, связанные с производительностью системы, определяются структуры хранения данных и методы доступа.
Взаимодействие между этапами проектирования и словарной системой необходимо рассматривать отдельно. Процедуры проектирования могут использоваться независимо в случае отсутствия словарной системы. Сама словарная система может рассматриваться как элемент автоматизации проектирования.
Средства проектирования и оценочные критерии используются на всех стадиях разработки. В настоящее время неопределенность при выборе критериев является наиболее слабым местом в проектировании БД. Это связано с трудностью описания и идентификации большого числа альтернативных решений.
Проще обстоит дело при работе с количественными критериями, к которым относятся время ответа на запрос, стоимость модификации, стоимость памяти, время на создание, стоимость на реорганизацию. Затруднение может вызывать противоречие критериев друг другу.
В то же время существует много критериев оптимальности, являющихся неизмеримыми свойствами, трудно выразимыми в количественном представлении или в виде целевой функции.
К качественным критериям могут относиться гибкость, адаптивность, доступность для новых пользователей, совместимость с другими системами, возможность конвертирования в другую вычислительную среду, возможность восстановления, возможность распределения и расширения.
Следует отметить, что проектирование распределенных баз данных является сложным процессом, в реализации которого можно выделить четыре основные проблемы:
1) проблему дезагрегации, состоящую в необходимости рационального, в соответствии с системой расчетов (решаемых задач), распределения учетной информации по уровням обработки и участкам учета с обеспечением их взаимосвязи;
2) проблему, связанную с созданием инфологической структуры информационного фонда распределенной базы данных, ориентированного на решение всего комплекса задач избранной системы расчетов;
3) технологическую проблему, состоящую в удовлетворении требований рационализации вычислительного процесса на основе распределенной базы данных и распределенного комплекса технических средств;
4) организационно-правовую проблему, состоящую в обеспечении защиты данных н соблюдении юридических норм доступа к базам данных, их заполнения, изменения и уничтожения.
Кроме этих четырех проблем при создании программного обеспечения интегрированной распределенной обработки учетных данных важным вопросом является распределение данных в логических узлах обработки информации.
Определение и размещение фрагментов БД на узлах сети должно проводиться с учетом особенностей использования БД. Установлено, что в большинстве БД 20% запросов создают 80% нагрузки на БД. Эти запросы и нужно анализировать для того, чтобы определить целесообразное разбиение БД на фрагменты и размещение этих фрагментов.
При анализе БД с целью определения схемы размещения по узлам учитывают:
1) количественные показатели (в первую очередь, объем данных): они влияют на размещение данных;
2) качественные показатели: они определяют схему фрагментации. При этом, обычно, учитываются следующие параметры:
· частота запуска приложений;
· узел, на котором запускается приложение;
· требования к производительности транзакций и приложений;
· требования к времени реакции системы за запросы и т.д.
Критерии, по которым производится определение и размещение фрагментов БД:
1) локальность ссылок;
2) повышение надежности и доступности (репликация);
3) производительность (наличие «узких» мест или неэффективное использование ресурсов системы);
4) баланс между ёмкостью и стоимостью внешней памяти;
5) минимизация расходов на передачу данных.
Стратегия распределения данных по узлам сети ЭВМ могут классифицироваться в зависимости от количества узлов, содержащих данные, и наличия дублирования информации, а также архитектурой системы и программным обеспечением СУБД. Рассмотрим четыре основные стратегии распределения данных:
1. Централизация баз данных. Централизованный, или метод извлечения данных вручную (рис. 1), является самым простым для реализации способом. На одном сервере находится единственная копия базы данных. Все операции с базой данных обеспечиваются этим сервером. Доступ к данным выполняется с помощью удаленного запроса или удаленной транзакции. Достоинством такого способа является легкая поддержка базы данных в актуальном состоянии. Недостатком является то, что размер базы ограничен размером внешней памяти, все запросы направляются к единственному серверу с соответствующими затратами на стоимость связи и временную задержку. Отсюда – ограничение на параллельную обработку. База может быть недоступной для удаленных пользователей при появлении ошибок связи и полностью выходит из строя при отказе центрального сервера.
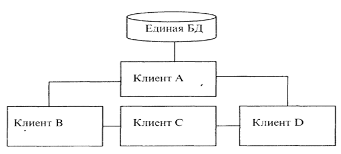
Рис. 1 – Централизованное распределение
2. Расчленение распределенной базы данных. При этой стратегии существует единственная копия базы данных, а локальные базы данных распределены по отдельным узлам. Объем распределенной базы данных ограничивается необходимым объемом вторичной памяти, имеющейся уже во всей информационно-вычислительной сети. Эффективность стратегии расчленения тем выше, чем выше степень локализации ссылок, то есть чем больше число запросов пользователей реализуется в базах данных соответствующих локальных информационных систем (рис.2).
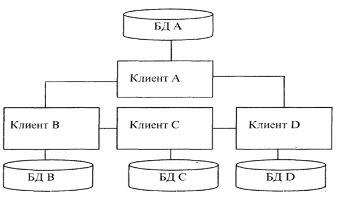
Рис. 2 – Метод расчленения
Достоинствами данного метода являются увеличение объема базы данных; большинство запросов удовлетворяется локальными базами, что сокращает время ответа; увеличение доступности и надежности; снижение стоимости запросов на выборку и обновление по сравнению с централизованным распределением; система останется частично работоспособной, если выйдет из строя один сервер.
К недостаткам метода относится то, что часть удаленных запросов или транзакций могут потребовать доступ ко всем серверам, что увеличивает время ожидания и цену; необходимо иметь сведения о размещении данных в БД. Однако доступность и надежность увеличиваются. Расчлененные базы данных наиболее подходят к случаю совместного использования локальных и глобальных сетей ЭВМ.
3. Дублирование распределенных баз данных. При использовании метода дублирования (рис. 3) в каждом сервере сети ЭВМ размещается полная база данных. При этой стратегии организуется несколько копий базы данных; полная копия всех данных располагается в каждом логическом узле. Основное преимущество данной стратегии заключаются в высокой надежности информационной базы к простоте ее восстановления. Этот метод дает наиболее надежный способ хранения данных.
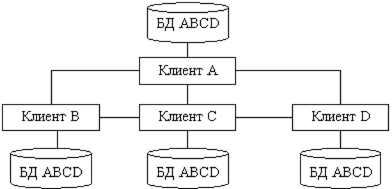
Рис. 3 – Метод дублирования
Недостатками метода являются повышенные требования к объему внешней памяти; усложнение корректировки баз, так как требуется синхронизация с целью согласования копий. К достоинствам метода относится то, что все запросы выполняются локально, благодаря чему обеспечивается быстрый доступ. Этот метод используется, когда фактор надежности является критическим, база – небольшой, а интенсивность обновления невелика.
4. Смешанная стратегия. В методе смешанного распределения объединены два способа распределения данных: дублирование и расчленение (рис. 4). При этом приобретены как преимущества, так и недостатки обоих способов. Появилась необходимость хранить информацию о том, где находятся данные в сети. Главноепреимущество метода – гибкость этой системы, так как можно установить компромисс между объемом памяти под базу в целом и под базу в каждом сервере, чтобы обеспечить надежность и эффективность работы. В этой стратегии легко реализуется параллельная обработка, т. е. обслуживание распределенного запроса или транзакции. Недостаткиметода: остается проблема взаимозависимости факторов, влияющих на производительность системы, ее надежность, повышаются требования к памяти. Смешанную стратегию используют при наличии сетевойСУБД, которая обеспечивает реализацию распределенной базы данных.
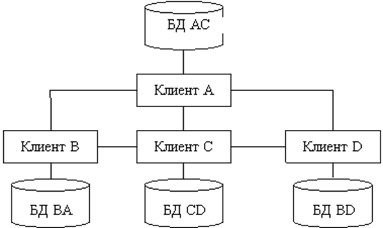
Рис. 4 – Смешанное распределение
Процесс проектирования является длительным и трудоемким и обычно продолжается несколько месяцев. Основными ресурсами проектировщика БД являются его собственная интуиция и опыт, поэтому качество решения во многих случаях может оказаться низким.
| <== предыдущая лекция | | | следующая лекция ==> |
| Work in pairs. Practise making arrangements on the phone. Use the diagram and 5-8 useful phrases to help you. Take turns to be A and B. | | | WRITING |