ПРАКТИЧЕСКАЯ ЧАСТЬ. Пример 1. Разработать библиотечную функцию для симметричного представления одномерного массива данных относительно первого значения
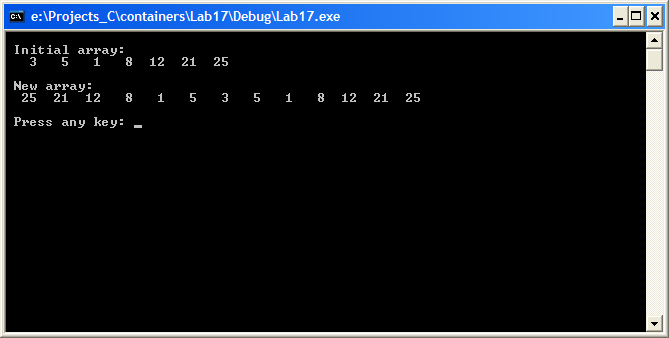
Пример 1. Разработать библиотечную функцию для симметричного представления одномерного массива данных относительно первого значения. Например, пусть дан исходный одномерный массив 3 5 1 8 12 21 25. Результат симметричного представления: 25 21 12 8 1 5 3 5 1 8 12 21 25. Программный код решения примера состоит из двух файлов
Рис. 20.17. Результат симметричного преобразования массива Задание 1 1. К проекту подключите статическую библиотеку с файлами xyx.h, xyx.c. Осуществите сборку проекта из приведенных файлов. 2. Предусмотрите ввод чисел массива с клавиатуры. 3. Напишите функцию типа xyx(), которая обрабатывает одномерные символьные массивы данных. 4. Видоизмените программу для преобразования массива с действительными числами, которые формируются случайным образом из данного интервала [–2X; 2X], где Х – номер компьютера, на котором выполняется лабораторная работа. 5. Разработайте функцию сортировки чисел массива, поместите ее в статическую библиотеку и используйте для сортировки заданного массива по убыванию в соответствии с предыдущим пунктом задания. После сортировки произведите преобразование массива с помощью созданной библиотечной функции xyx(). Пример 2. Разработать абстрактный тип данных – двоичное дерево поиска. Выполнить вставки узлов в двоичное дерево случайными числами и произвести обход дерева с порядковой выборкой [2]. Созданные функции заполнения и обхода двоичного дерева поместить в статическую библиотеку. Дерево – это нелинейная двухмерная структура данных с особыми свойствами. Узлы дерева – две или более связей. В двоичном дереве узлы содержат две связки. Первый узел дерева называется корневым, каждая его связь ссылается на потомка. Левый потомок – первый узел левого поддерева, правый потомок – первый узел правого поддерева. Потомки одного узла называются узлами-сиблингами. Узел, не имеющий потомков, называется листом. Двоичное дерево поиска (с неповторяющимися значениями в узлах) устроено так, что значения в любом левом поддереве меньше, а значения в любом правом поддереве больше, чем значение в родительском узле [2]. На рис. 20.18 изображена схема двоичного дерева поиска с 12 значениями.
Рис. 20.18. Пример двоичного дерева поиска В программах, реализующих стеки, очереди, деревья и т. д., используются автореферентные структуры (self-referential), которые содержат в качестве элемента указатель, ссылающийся на структуру того же типа. Например, определение struct node { int data; struct node *nextPtr; }; описывает тип struct node. Элемент nextPtr указывает на структуру типа struct node – структуру того же самого типа, что и объявленная, т. е. структура ссылается сама на себя. Для заданного примера используем целые случайные числа из интервала от 0 до 14. Программный код решения примера состоит из трех файлов
Функции insertNode(), inOrder() используются рекурсивно, т. е. вызывают сами себя из тела функции. В теле функции inOrder() нужно выполнить следующие шаги: 1) обойти вызовом inOrder() левое поддерево; 2) обработать значение в узле; 3) обойти вызовом inOrder() правое поддерево. Обход двоичного дерева поиска вызовом функции inOrder() выдает значения в узлах в возрастающем порядке. Процесс создания двоичного дерева поиска фактически сортирует данные, поэтому называется сортировкой двоичного дерева [2].
Рис. 20.19. Пример обхода двоичного дерева Задание 2 1. Функции заполнения и обхода двоичного дерева поместите в статическую библиотеку. Выполните настройки проекта с подключаемой статической библиотекой. 2. Напишите программу с использованием вещественных чисел, помещаемых в узлы двоичного дерева. Случайные числа (значения узлов дерева) задайте из интервала [–2X, 2X], где Х – номер компьютера, на котором выполняется лабораторная работа. 3. Увеличьте число узлов дерева до 11Х, где Х – номер компьютера, на котором выполняется лабораторная работа. Результат выполнения программы запишите в текстовый файл вида treeX.txt, где Х – первая буква фамилии пользователя.
Контрольные вопросы 1. Какая библиотека называется статически подключаемой? 2. Какую нотацию рекомендуется использовать для созданных пользователем библиотечных модулей? 3. Какое расширение используется для созданных пользовательских библиотечных модулей? 4. Применяется или нет функция main() в статически подключаемой библиотеке, созданной пользователем? 5. По какой дисциплине происходит обработка данных в такой структуре данных, как стек? 6. По какой дисциплине происходит обработка данных в такой структуре данных, как очередь?
|