
Метод случайного распределения
http://www.tecsun.com.cn Схема контроля
А теперь самое весёлое, то что все просили объяснить!!!
Есть эффект последовательности. Предыдущие оценки влияют на последующие. Нужно сделать, чтоб позиция предъявления в ряду в последовательности проб у каждого объекта была одинаковая – позиционное уравнивание.
С помощью таблицы случайных чисел с равномерным распределением делаем. Таблица есть в яндексе и на почте. Каждой паре фамилии присваиваем число, взятое из таблице. Я брала 1- и 2х- значные числа подряд. В табличке ниже это 2 колонка.
Далее ранжируем. Это можно сделать вручную, я делала в программе Access. Он есть в винде. Жмём там создать новую базу данных, потом создание таблице в режиме конструктора. В первую колонку вбиваем пару фамилий, во вторую случайные числа. Можно сохраниться на всякий случай. Потом жмём по колонке с числами правой кнопкой мыши и выбираем сортировку по возрастанию. Вуаля! Самая левая колонка – код – это и есть порядковые номера, они у меня в третьей колонке ниже. Собственно порядковые номера это и есть порядок предъявления карточек!
Есть только проблема. Я не знаю как переносить данные из ворда в аксес и эксель, поэтому вбивала вручную всё каждый раз=(
Метод случайного распределения
Считаем среднюю позицию каждой фамилии. В идеале – 23, но это практически невозможно, не пугайтесь =) Числа в числители - сумма всех позиций(3 колонка), на которых находится фамилия данного человека.
Средние позиции:
Калинина 7+6+34+12+14+35+23+1+16 = 16.4
Сравнив самую большую среднюю позицию и самую маленькую, чтобы узнать существуют ли между ними значимые отличия. Используем критерий Стъюдента для сравнения двух средних. («несвязанных» совокупностей). Кстати, мы это на матметодах проходили, может у кого есть в тетради алгоритм, но я распишу.
Гипотезы H0 – Между средними позициями объектов есть незначимые различия H1 – Между средними позициями объектов есть значимые различия
t=
(в знаменателе под корнем ВСЁ!)
В числители собственно средние, полученные выше. n – везде 9, это количество S-это дисперсия. Её можно посчитать в экселе, как я и сделала, потому что это быстро или по формуле:
Итоговый результат:
|

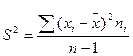
 =596,1 (Ламекина)
=596,1 (Ламекина) =144,7 (Калинина)
=144,7 (Калинина)


