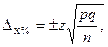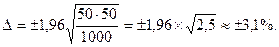Общие параметры выборки
Определение общих параметров выборки осуществляется после завершения полевых работ (когда собраны все анкеты). Данный этап состоит из ряда взаимосвязанных шагов. Это: ■ определение реального количества опрошенных респондентов; ■ определение структуры выборки; ■ распределение по месту опроса; ■ установление доверительного уровня статистической надежности выборки; ■ расчет статистической ошибки и определение репрезентативности выборки. Первое, что должно интересовать исследователя после получения заполненных анкет, — это количество респондентов. Оно может быть либо больше, либо меньше запланированного количества анкет. При этом первый вариант лучше с точки зрения статистического анализа, но хуже с точки зрения руководства фирмы, так как дополнительные анкеты являются незапланированными расходами на оплату работы интервьюеров. Второй вариант обычно хуже и с точки зрения анализа (выборка менее представительна), и с точки зрения руководства (заказчик будет недоволен несоблюдением требований, оговоренных в ТЗ). При оценке разницы между реальным и плановым размером выборки следует принимать в расчет разницу в статистической ошибке (см. ниже). Если она невелика (в ту или другую сторону), репрезентативность всей выборки существенно не страдает. Но если разница достаточно значима, выборка может оказаться непредставительной. Кроме того, при определении общего размера выборки необходимо иметь в виду, что статистическая ошибка всей выборки относится только к общим распределениям. Разрезы существенно увеличивают статистическую ошибку. Поэтому еще до начала опроса следует определить, какая численность каждой из интересующих целевых групп респондентов является достаточной для построения статистически значимых заключений и выводов. Структура выборки может быть случайной (респонденты отбирались в случайном порядке) или неслучайной (респонденты отбирались на основании заранее известных критериев, например методом квотирования). Эта информация важна при интерпретации результатов статистического анализа. Случайные выборки априори являются репрезентативными, так как на попадание/непопадание каждого респондента в выборку не влияют никакие факторы, кроме случайных. Представительность неслучайных выборок не следует из их определения. Иногда они специально делаются нерепрезентативными относительно генеральной совокупности, однако могут являться весьма представительными относительно какой-либо одной интересующей целевой группы (например, исследуется только мнение мужчин в возрасте после 40 лет). При анализе структуры выборки необходимо также изучить фильтрационные вопросы анкеты, то есть вопросы, специально предназначенные для отсеивания не подходящих под требования выборки респондентов. Несмотря на то, что такие вопросы позволяют исключить не нужные для конкретного исследования целевые группы, знание доли исключенных категорий позволит впоследствии составить общее представление о параметрах всей генеральной совокупности. Приведем пример. Методом телефонного опроса исследуется потребительский спрос на московском рынке творожной массы. При этом опрашиваются только лица, покупающие данный продукт, — для чего в анкету добавлен соответствующий фильтрационный вопрос. Однако в дальнейшем потребуется рассчитать емкость рынка исследуемого продукта. Решением данной задачи будет подсчет количества отсеянных респондентов (лиц, не покупающих творожную массу). Таким образом, впоследствии мы сможем определить долю покупателей творожной массы от общей численности населения Москвы. Еще одна важная для исследователя характеристика выборки — это распределение респондентов по месту опроса (личные интервью). Позже эти данные могут помочь при определении различий между респондентами, опрошенными в разных местах. (Очевидна разница в доходах между посетителями рынков и бутиков.) Имея в своем распоряжении указанную выше информацию, можно приступать к определению представительности (или репрезентативности) выборки. Прежде всего необходимо установить уровень доверия к результатам опроса. Обычно в маркетинговых исследованиях используется уровень доверия 95 % и 99 %. Мы рекомендуем остановиться именно на первом варианте как на наиболее релевантном по отношению к маркетинговым исследованиям. В зависимости от выбранного доверительного уровня определяется специфическая константа г, участвующая в формуле расчета статистической ошибки выборки. Константы доверительных уровней, наиболее часто используемых в маркетинговых исследованиях, представлены в табл. 1.1.
Таблица 1.1. Константы доверительных уровней
Максимальная статистическая ошибка выборки рассчитывается по следующей формуле:
где — статистическая константа для соответствующего доверительного уровня; p= q = 50 % — вероятность наступления/ненаступления исследуемого события (то есть попадания/непопадания респондента в выборку); для случайных выборок данная вероятность равна 1/2 или 50 %; n — размер выборки (общее количество опрошенных). Таким образом, для выборки в 1000 респондентов и при уровне доверия к результатам опроса 95 % статистическая ошибка выборки будет равна:
Эта же статистическая ошибка используется для характеристики всех значений в выборке, выраженных в относительных величинах. То есть если в дальнейшем при построении линейных распределений по вопросам анкеты мы выясним, что 32 % респондентов покупают газеты в киосках на улице, — это будет означать, что данное значение варьируется в пределах от 28,9 % (32 % - 3,1 %) до 35,1 % (32 % + 3,1 %). Для расчета статистической ошибки значений переменных, выраженных в абсолютных величинах, применяется другая формула. При этом ошибка варьируется в зависимости от конкретной анализируемой величины. Ее расчет основан на построении линейных распределений и показан в разделе 2.1.
|