
Мережні структури даних
Комітет CODASYL DBTG запропонував свій варіант структури СКБД, який схематично представлений на рис. 3.5. З цього рисунка видно, що кінцеві користувачі здійснюють доступ до бази даних за допомогою прикладної програми на базовій мові (звичайно це COBOL). Для того, щоб здійснити доступ до інформації в базі даних, кожна прикладна програма повинна використовувати деяку підсхему, яка є обмеженим представленням структури всієїбази даних. Декілька програм можуть паралельно виокнувати одну й ту ж підсхему. Більш того, підсхема визначається тільки на одній схемі, але вона може перекривати іншу підсхему. CODASYL-сумісна СКБД може підтримувати декілька різних баз даних, структура кожної з яких визначається власною схемою.
Рис. 3.5. Схема і підсхеми визначаються за допомогою різних DDL-мов (мова SSDDL є декларативним розширенням мови програмування). Визначивши схему за допомогою мови SDDL, перш ніж вона зможе використати прикладну програму. Звичайно всередині прикладної програми повинно міститись тимчасове сховище, що призначено або для зберігання даних, що забираються з допоміжного джерела, або для розміщення даних перед їх зберіганням. В програмі на мові COBOL це досягається за рахунок вказания відповідних типівзаписіву розділі оперативного запам’ятовуючого пристрою (working storage section) розділу даних (data vision). Тимчасове сховище необхідно й в тих випадках, коли програма працює з СКБД, оскільки тут також має місце обмін даними між прикладною програмою та базою даних. Використання підсистеми прикладною програмою викликає неявне оголошення елементів цієї підсхеми у тимчасовому сховищі. Простір, зарезервований для елементів цієї підсхеми, нахивається робочою областю користувача (User Work Area - UWA), чи UWA-областю (в термінології DBLTG). В додатках групи DBLTG (Database Language Task Group) цей термін пропущений, хоча він як і раніше використовується на практиці. Тип зв'язку визначається для двох типів запису: предка і нащадка. Екземпляр типу зв'язку складається з одного екземпляра типу запису предка й упорядкованого набору екземплярів типу запису нащадка. Для даного типу зв'язку L з типом запису предка P і типом запису нащадка C повинні виконуватися наступні дві умови: · Кожен екземпляр типу P є предком тільки в одному екземплярі L; · Кожен екземпляр C є нащадком не більш, ніж в одному екземплярі L. На формування типів зв'язки не накладаються особливі обмеження; можливі, наприклад, що випливають ситуації: § Тип запису нащадка в одному типі зв'язку L1 може бути типом запису предка в іншому типі зв'язку L2 (як в ієрархії). § Даний тип запису P може бути типом запису предка в будь-якому числі типів зв'язку. § Даний тип запису P може бути типом запису нащадка в будь-якому числі типів зв'язку. § Може існувати будь-як число типів зв'язку з тим самим типом запису предка і тим самим типом запису нащадка; і якщо L1 і L2 - два типи зв'язку з тим самим типом запису предка P і тим самим типом запису нащадка C, то правила, по яких утвориться споріднення, у різних зв'язках можуть розрізнятися. § Типи запису X і Y можуть бути предком і нащадком в одному зв'язку і нащадком і предком - в іншій. § Предок і нащадок можуть бути одного типу запису.
Простий приклад мережної схеми БД:
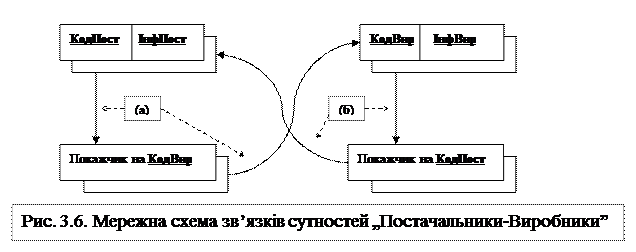
Тут відображено ситуацію, коли один виріб може постачатися кількома постачальниками, а постачальники можуть постачати різні вироби. Тому атрибут Вартість не може бути асоційований тільки з записом Виріб або з записом Постачальник, а мае бути асоційованим одночасно з двома названими записами. На рис. 3.6 показано схему реалізації таких зв’язків.
На рис. прийняті такі позначення: КодПост – код постачальника (ключовий атрибут); КодВир – код виробника (ключовий атрибут); ІнфПост – неключові атрибути (інформація) об’єкту Постачальник; ІнфВир – неключові атрибути (інформація) об’єкту Виробник. На рис. 3.7 показано приклад наборів даних разом з посиланнями, що забезпечують реалізацію схеми рис. 3.6. Тут показано тільки зв’язок по одному зі зв’язувальних ланцюжків (а) з рис. 3.6. Інший є квазісиметрією першого і тому не наводиться.
На рис. 3.7 прийняті такі позначення: AdrS – гіпотетична адреса набору даних „Постачальники”. AdrP – гіпотетична адреса набору даних „Вироби”. IdS – ідентифікатор (код) постачальника. InfS – інформація про постачальника, що представлена одним або кількома атрибутами. IndSP – покажчик на запис у зв’язувальному наборі даних, з якого починається перший елемент списку покажчиків на вироби, що постачаються даним виробником; AdrSP – гіпотетична адреса зв’язувального набору даних „Постачальники” → „Вироби” NxtSP – адреса наступного елементу (запису) у списку покажчиків на предмети, що постачаються цим же постачальником. Якщо цей елемент є останнім у списку, то в полі NxtSP вказується або адреса голови списку, яким є адреса постачальника, з якого починався список, або системна константа типу Null, що свідчить про досягнення кінця списку. PriceSP – ціна виробу у виробника, заданого посиланням в полі IndP; IndP – покажчик на виріб, що постачається постачальником, що є головою списку. IdP – ідентифікатор (код) виробу. InfР – інформація про виріб, що представлена одним або кількома атрибутами. Як бачимо, крім безпосередньої своєї функції, зв’язувальний набір даних дозволяє задавати й властивості зв’язку. В наведеному прикладі такою властивістю є ціна виробу у даного виробника Price. У табл. 3.2 наведено звичайну таблицю (ліворуч), яку можна отримати з рис. 3.7 стосовно цін постачальників на вироби, а якщо використали б схему зв’язків (б) на рис. 3.6, то отримали б ціни виробів по постачальниках. Таблиця 3.2. Ціни постачальників на вироби та ціни виробів по постачальниках
Крім способу зв’язування наборів даних, що представлено на рис. 3.6, існує й другий, схема якого представлено на рис. 3.8.
Останній варіант схеми є більш складним в реалізації. Як бачимо, мережні моделі можуть більш адекватно відображати зв’язки між інформаційними об’єктами. Крім зв’язків кардинальності M:N мережна структура може відображати цикли та петлі.
3.3.2. Маніпулювання даними Зразковий набір операцій може бути наступної: · Знайти конкретний запис у наборі однотипних записів (виріб P2); · Перейти від предка до першого нащадка по деякому зв'язку (до першого предмету постачальника S1); · Перейти до наступного нащадка в деякому зв'язку (від P1 до P3, якщо ми знаходимося у вузлі S1); · Перейти від нащадка до предка по деякому зв'язку (знайти постачальника предмета Р5); · Створити новий запис; · Видалити запис; · Модифікувати запис; · Включити в зв'язок; · Виключити зі зв'язку; · Переставити в інший зв'язок і т.д.
|


 3000
3000
 3000
3000

 6000
6000
 3100
3100
 6200
6200
 3240
3240
 3340
3340
 3140
3140

 6300
6300
 6500
6500
 6100
6100
 102,34
102,34

 Рис. 3.7. Приклад можливої реалізації мережного зв’язку
Рис. 3.7. Приклад можливої реалізації мережного зв’язку



