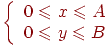Матричные ВС
Матричная ВС также является типичным представителем ОКМД, расширением принципа векторных ВС. Классическим примером, прототипом и эталоном стала ВС ILLIAC 1V, разработанная в 1971 г. в Иллинойском университете и в начале 1972 г. установленная в Эймском научно-исследовательском центре NASA (Калифорния). Одна последовательность команд программы управляет работой множества 64 ПЭ, одновременно выполняющих одну и ту же операцию над данными, которые могут быть различными и хранятся в ОП каждого ПЭ. (Производительность — до 200 млн. оп./с) В целом структура центральной части может быть представлена аналогичной векторной ВС (рис. 1.10).
УУ — фактически простая вычислительная машина небольшой производительности и может выполнять операции над скалярами одновременно с выполнением матрицей ПЭ операций над векторами или матрицами. Посылает команды в независимые ПЭ и передает адреса в их ОП. К центральной части подключена система ввода-вывода с управляющей машиной В-6500, устройство управления вводом-выводом, файловые диски, буферная память и коммутатор ввода-вывода. Операционная система, ассемблеры и трансляторы размещаются в памяти В-6500. Почему же ВС — матричная? ПЭ образуют матрицу, в которой информация от одного ПЭ к другому может быть передана через сеть пересылок данных при помощи специальных команд обмена. Регистры пересылок (рис. 1.11) каждого i-го ПЭ связаны высокоскоростными линиями обмена с регистрами пересылок ближайшего левого (i-1-го) и ближайшего правого (i+1)-го ПЭ, а также с регистрами пересылок ПЭ, отстоящего влево на 8 позиций от данного (i-8)-й и отстоящего вправо на 8 позиций от данного (i+8)-й, при этом нумерация ПЭ рассматривается как циклическая с переходом от 63 к 0 (нумерация возрастает по mod 64) слева направо и от 0 к 63 справа налево.
Расстояния между ПЭ в сети пересылок и соответствующие пути передачи информации задаются комбинациями из (-1, +1, -8, +8). Предусмотрено маскирование ПЭ. Каждый ПЭ может индексировать свою ОП независимо от других ПЭ, что важно для операций матричной алгебры, когда к двухмерному массиву данных требуется доступ как по строкам, так и по столбцам. Доступ к ОП имеют АУ соответствующего ПЭ, УУ системы и подсистема ввода-вывода. Управление доступом и разрешение конфликтов при доступе к ОП осуществляет УУ системы. Система эффективна при решении задач большой размерности, использующих исчисление конечных разностей, матричной арифметики, быстрого преобразования Фурье, обработки сигналов и изображений, линейного программирования и др. Например, приближенные методы решения задач математической физики и, прежде всего, — системы дифференциальных уравнений используют исчисление конечных разностей (конечно-разностные методы решения, "метод сеток").
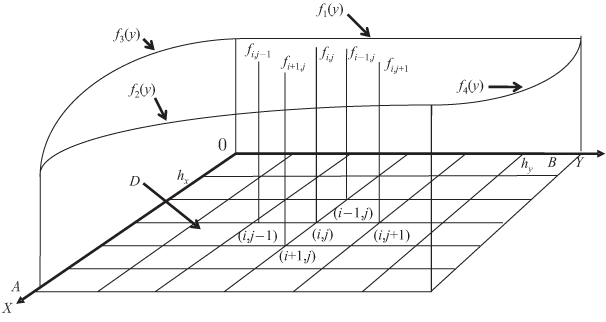
Кратко рассмотрим план решения подобной задачи на матричной ВС. Пусть необходимо решить уравнение с частных производных
на области B:
Граничные условия: f(0,y)= f1(y), f(A,y)= f2(y), f(x,0)= f3(x), f(x,B)= f4(x). Частные производные можно выразить через конечные разности несколькими способами, например:
Подставив полученные выражения в уравнение, получим основное рекуррентное соотношение для нахождения значения функции через ее значения в соседних четырех узлах: fi, j = 0,5 fi+1, j + 0,5 fi-1, j - 0,25 hx2/hy(fi, j+1 - fi, j-1). Распараллеливание вычислений и "прокатывание" матрицей ПЭ области B — многократные, до получения необходимой точности — очевидны. А именно: первоначально в одном цикле итерации 64 ПЭ по выведенной формуле рассчитывают 8 × 8 узловых значений функции близ вершины координат, "цепляя" при этом граничные значения. Затем производится смещение вправо на следующую группу узловых значений функции. По окончании обработки по горизонтали производится смещение по вертикали и т.д. При следующей итерации процесс повторяется. От итерации к итерации распространяется влияние граничных условий на рассчитываемые значения функции. Процесс сходится для определения значений функции-решения в узлах сетки с требуемой точностью. Вернемся к отечественной разработке ПС-2000 (ПС-2100) — векторной ВС. В ней предусмотрена возможность сегментации процессоров, при которой последний процессор в сегменте связывается регулярным каналом (аналог высокоскоростной линии) с первым. Все 64 процессора могут составить один сегмент, могут быть сформированы два сегмента по 32 ПЭ, четыре по 16, 8 по 8 ПЭ. Итак, получается идеальная схема для "покрытия" двумерной подобласти обсчитываемой области. Правда, отсутствуют быстрые связи по вертикали, что должно быть возмещено хранением всей информации по столбцам в ОП каждого ПЭ. Зато, при смещении процессоров на смежную подобласть по горизонтали, последний ПЭ предыдущей подобласти остается "левым" для первого в новой подобласти. Т.е. при таком смещении сохраняется регулярность фактических связей между узлами сетки. В ILLIAC-1V такая регулярность сохранялась бы, если бы существовали быстрые связи между ПЭ7 и ПЭ0, ПЭ15 и ПЭ8 и т.д., то есть циклически по строкам матрицы. Как видим, такие связи учтены при более поздних разработках матричных ВС. ВС Крей-1 ("Электроника ССБИС") ВС Cray-1, несмотря на последующие разработки, остается эталоном типа МКОД. В России разработан аналог — векторно-конвейерная ЭВМ "Электроника ССБИС", отличающаяся некоторыми увеличенными параметрами комплектации. Структура ВС показана на рис. 1.13.
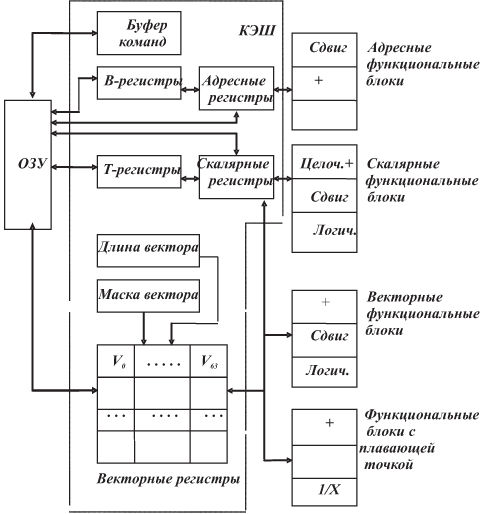
Предназначена для выполнения как векторных, так и скалярных операций, Имеет 64 буферных (выравнивающих) регистра для 24-битовых адресов (B-регистры), 64 буферных (выравнивающих) регистров для 64-битовых слов данных (T-регистры). B-регистры в свою очередь пополняют буфер для одной из основных групп регистров машины — 8 адресных регистров, а T-регистры — для группы 8 скалярных регистров. Адресные регистры используются и как индексные. Третья основная группа регистров — 8 векторных регистров по 64 64-битовых слов. Регистр длины вектора определяет число операций, выполняемых по векторным командам, т.е. действительную длину вектора. Маска вектора определяет элементы, над которыми выполняется операция. Буфер команд состоит из четырех ЗУ, каждое из которых — из 64 16-разрядных регистров. Представляет 4 программы, выполняемые в мультипрограммном режиме. (В "Э-ССБИС" — 16 таких ЗУ.) 12 специализированных функциональных блоков-конвейеров (в "Э-ССБИС" 16 блоков) выполняют арифметические, логические операции и сдвиг. Уровней конвейера — от 2 до 14. Блоки являются независимыми. Несколько функциональных блоков могут работать одновременно. Возможно "зацепление" векторов при выполнении операций вида A × B + C, когда два или более конвейеров выстраиваются в один и результат с одного немедленно поступает как операнд на другой. Таким образом, параллелизм в обработке данных организуется с помощью: 1. одновременного использования различных функциональных блоков и различных векторных регистров; 2. применения режима "зацепления" векторов. (Нас интересует архитектура, но не катастрофически стареющие характеристики. Однако для справки: такт машины 12{,}5 нс, цикл обращения к ОЗУ 50 нс, производительность считается: 38 млн. скалярных оп/с и 80 млн. векторных оп/с.) МВК "Эльбрус-2" Представляет тип МКМД. Имеет общую оперативную память и перекрестный коммутатор. Является основой сложных автоматизированных систем управления, работающих в реальном времени, использовался в космических исследованиях, а также в области ядерной физики.
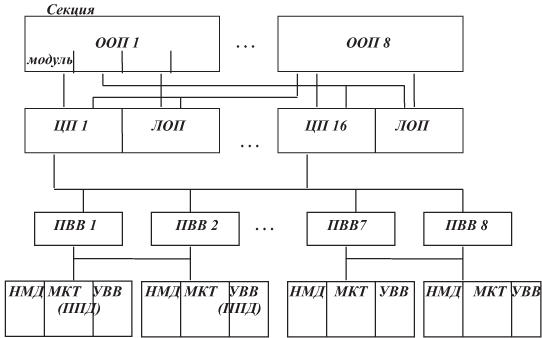
Производительность (информация имеет историческую ценность) в 10-процессорном варианте — до 120 млн. оп/с (12,5 млн оп/с на одном процессоре). Максимальный объем ОП — 16 млн 72-разрядных слов (144 Мбайт), максимальная пропускная способность каналов ввода-вывода — 120 Мбайт/с. Эти характеристики позволили решить многие проблемы применения супер-ЭВМ, но сегодня не впечатляют. Принципиальные предпосылки разработки: 1. Аппаратная поддержка ЯВУ. 2. Параллелизм на двух уровнях — мультипроцессорная обработка (распределение процессов между процессорами), конвейерная обработка команд и параллельная обработка данных в многофункциональном АЛУ (10 ИУ). В МВК могут входить от 1 до 10 ЦП, от 1 до 32 модулей ОП и от 1 до 4 ПВВ. Каждый ПВВ имеет 40 каналов связи: 8 быстрых (аналог селекторных) каналов (БК) для магнитных барабанов и дисков и 32 стандартных (СК) для прочих устройств ввода-вывода. Работа с удаленными объектами по линиям связи осуществляется с помощью процессоров передачи данных (их — до 16), которые являются самостоятельными модулями с собственной системой команд и внутренней памятью. Все компоненты системы работают параллельно и независимо друг от друга и динамически распределяются операционной системой между задачами. ЦП МВК "Эльбрус" имеет безадресную систему команд, основанную на ПОЛИЗ и выполняемую на стеке. Обрабатывает числовые данные в 32 разряда (полслова), 64 разряда (слово), 128 разрядов (двойное слово). Нечисловая информация может быть представлена в виде битовых, цифровых или байтовых наборов. Каждое слово сопровождается 6-разрядным тегом, определяющим его тип. Два разряда используются в аппаратном контроле. Проект МВК "Эльбрус-3" Так как ассемблерный язык исключен из интерфейса пользователя, то аппаратная реализация (она отражена в системе команд — в машинном языке) МВК "Эльбрус-3" значительно отличается от "Эльбрус-2". Структура МВК представлена на рис. 1.15.
Здесь ООП — общая оперативная память (8 секций (блоков) по 4 модуля; модуль — 32 Мбайт); МКТ — модульные комплексы телеобработки (аналог ППД — в "Эльбрус-2"); ЛОП — локальная оперативная память, 4 — 16 Мбайт. Принципы, лежащие в основе разработки: 1. Программная совместимость на уровне ЯВУ (Эль-76 — ЯВУ-ассемблер) с другими моделями "Эльбрус". 2. Теговая архитектура. 3. Дальнейшее развитие многопроцессорности на общей ОП, что повышает производительность и структурную надежность. Пиковая производительность одного (из 16) процессора достигает 700 млн. оп/с при такте машины 10 нс. 4. Архитектура с длинным командным словом обеспечивает микрораспараллеливание между 7 ИУ АЛУ на уровне операций (2 ИУ сложения, 2 — умножения, одно — деления, 2 — логических), а также параллельное обращение по 8 каналам в ЛОП или ОП. 5. Семь конвейерных и независимых ИУ обеспечивают загрузку процессора работами в каждый такт. 6. Управление машиной позволяет контролировать каждый такт. Т.е. "длинная" команда выдается каждый такт, непосредственно запуская устройства без дополнительного динамического аппаратного планирования их загрузки. 7. Оптимизация распределения ресурсов возлагается на высокооптимизирующий транслятор с ЯВУ Эль-76 и с других языков высокого уровня. 8. Функционально разделенное СОЗУ снижает конфликты при обращении и отражает типы хранимых данных. Оно состоит из ассоциативного буфера команд в 2 тыс. слов, буфера стека в 1 тыс. слов для хранения верхних уровней локальных данных выполняемых процедур, буфера массивов в 512 слов и ассоциативной памяти глобалов (общих данных процедур) в 512 слов.
|