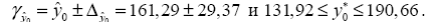Решение типовой задачи
Лабораторная работа "Построение эконометрической линейной модели уравнения парной регрессии "
1. Цель работы 2. Порядок выполнения работы 3. Содержание отчета 4. Контрольные вопросы 5. Варианты заданий
Цель работы 1) Изучить методику построения линейного уравнения парной регрессии способы оценки её адекватности и точности. 2) Рассчитать конкретный типовой пример. Порядок выполнения работы 1) Ознакомиться с методологией построения моделей парной регрессии и правилами оценки их точности и адекватности. 2) Получить исходные данные у преподавателя. 3) Выполнить расчет на ЭВМ (расчеты рекомендуется проводить при помощи ППП Microsoft Excel) 4) Оформить отчет, включающий выводы по проделанной работе. Содержание отчета 1) Исходные данные. 2) Результаты расчета с анализом полученных данных. 3) Выводы. Контрольные вопросы 1) Этапы построения модели регрессии. 2) Коэффициент линейной парной корреляции. 3) Сущность метода наименьших квадратов. 4) Объясните, чем вызвано появление в модели парной регрессии стохастической переменной ε? 5) Почему перед построением модели парной линейной регрессии необходимо рассчитывать коэффициент корреляции? 6) Объясните смысл понятия «число степеней свободы». 7) По каким вычислениям можно судить о значимости модели в целом? 8) Зачем необходимо рассчитывать t-критерий Стьюдента? 9) Зачем необходимо оценивать интервалы прогноза по линейному уравнению регрессии? 10) В каких пределах должна находиться ошибка аппроксимации, чтобы можно было сделать вывод о хорошем подборе модели к исходным данным?
Требуется: 1. Построить линейное уравнение парной регрессии y по x. 2. Рассчитать линейный коэффициент парной корреляции, коэффициент детерминации и среднюю ошибку аппроксимации. 3. Оценить статистическую значимость уравнения регрессии в целом и отдельных параметров регрессии и корреляции с помощью F критерия Фишера и t -критерия Стьюдента. 4. Выполнить прогноз заработной платы y при прогнозном значении среднедушевого прожиточного минимума x, составляющем 107% от среднего уровня. 5. Оценить точность прогноза, рассчитав ошибку прогноза и его доверительный интервал. 6. На одном графике отложить исходные данные и теоретическую прямую.
Построение уравнения регрессии сводится к оценке ее параметров. Для оценки параметров регрессий, линейных по параметрам, используют метод наименьших квадратов (МНК). МНК позволяет получить такие оценки параметров, при которых сумма квадратов отклонений фактических значений результативного признака y от теоретических y. x минимальна, т.е. Σ(y - ŷ)2 → min (2.3) Для линейных и нелинейных уравнений, приводимых к линейным, решается следующая система относительно a и b: .na + bΣx = Σ y, (2.4) a Σx + b Σ x2 = Σ xy. Можно воспользоваться готовыми формулами, которые вытекают непосредственно из решения этой системы:
(Ковариация – числовая характеристика совместного распределения двух случайных величин, равная математическому ожиданию произведения отклонений этих случайных величин от их математических ожиданий. Дисперсия – характеристика случайной величины, определяемая как математическое ожидание квадрата отклонения случайной величины от ее математического ожидания. Математическое ожидание – сумма произведений значений случайной величины на соответствующие вероятности.) Тесноту связи изучаемых явлений оценивает линейный коэффициент парной корреляции rxy для линейной регрессии (-1≤ rxy ≤1):
Оценку качества построенной модели даст коэффициент (индекс) детерминации rxy2 (для линейной регрессии) либо rxy 2 (для нелинейной регрессии), а также средняя ошибка аппроксимации. Средняя ошибка аппроксимации – среднее отклонение расчетных значений от фактических:
Допустимый предел значений Ā – не более 10%. Средний коэффициент эластичности
После того как найдено уравнение линейной регрессии, проводится оценка значимости как уравнения в целом, так и отдельных его параметров. Проверить значимость уравнения регрессии – значит установить, соответствует ли математическая модель, выражающая зависимость между переменными, экспериментальным данным и достаточно ли включенных в уравнение объясняющих переменных (одной или нескольких) для описания зависимой переменной. Оценка значимости уравнения регрессии в целом производится на основе
где
Схема дисперсионного анализа имеет вид, представленный в таблице
Определение дисперсии на одну степень свободы приводит дисперсии к сравнимому виду (напомним, что степени свободы – это числа, показывающие количество элементов варьирования, которые могут принимать произвольные значения, не изменяющие заданных характеристик). Сопоставляя факторную и остаточную дисперсии в расчете на одну степень свободы, получим величину F -критерия Фишера:
Фактическое значение F -критерия Фишера сравнивается с табличным значением Для парной линейной регрессии m = 1, поэтому
Величина F -критерия связана с коэффициентом детерминации r2xy, и её можно рассчитать по формуле:
Для оценки статистической значимости параметров регрессии и корреляции рассчитываются t-критерий Стьюдента и доверительные интервалы каждого из показателей. Оценка значимости коэффициентов регрессии и корреляции с помощью t -критерия Стьюдента проводится путем сопоставления их значений с величиной случайной ошибки:
Стандартные ошибки параметров линейной регрессии и коэффициента корреляции определяются по формулам:
Сравнивая фактическое и критическое (табличное) значения t статистики – tтабл и tфакт – делаем вывод о значимости параметров регрессии и корреляции. Если tтабл < tфакт то параметры a, b и rxy не случайно отличаются от нуля и сформировались под влиянием систематически действующего фактора x. Если tтабл > tфакт , то признается случайная природа формирования a, b или rxy. Для расчета доверительного интервала определяем предельную ошибку Δ для каждого показателя: Δa = tтаблma, Δb = tтаблmb. Формулы для расчета доверительных интервалов имеют следующий вид: γa = a ± Δa; γamin = a - Δa; γamax = a + Δa; γb = a ± Δb; γbmin = a - Δb; γbmax = a + Δb; Если в границы доверительного интервала попадает ноль, т.е. нижняя граница отрицательна, а верхняя положительна, то оцениваемый параметр принимается нулевым, так как он не может одновременно принимать и положительное, и отрицательное значения. Существует связь между t -критерием Стьюдента и F –критерием Фишера:
В прогнозных расчетах по уравнению регрессии определяется предсказываемое индивидуальное значение y0 как точечный прогноз при x = x0, т.е. путем подстановки в линейное уравнение ŷx = a + b.x соответствующего значения x. Однако точечный прогноз явно нереален, поэтому он дополняется расчетом стандартной ошибки
где
Решение типовой задачи Пример. По территориям региона приводятся данные за 199X г. Таблица 2.2
Требуется: 1. Построить линейное уравнение парной регрессии y по x. 2. Рассчитать линейный коэффициент парной корреляции, коэффициент детерминации и среднюю ошибку аппроксимации. 3. Оценить статистическую значимость уравнения регрессии в целом и отдельных параметров регрессии и корреляции с помощью F критерия Фишера и t -критерия Стьюдента. 4. Выполнить прогноз заработной платы y при прогнозном значении среднедушевого прожиточного минимума x, составляющем 107% от среднего уровня. 5. Оценить точность прогноза, рассчитав ошибку прогноза и его доверительный интервал. 6. На одном графике отложить исходные данные и теоретическую прямую. Решение 1. Для расчёта параметров уравнения регрессии заполняем столбцы 7–10 таблицы 2.3.
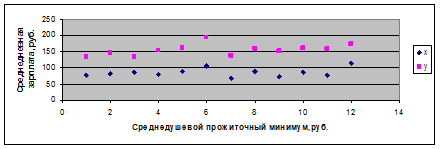
1.Для определения эмпирических коэффициентов регрессии вызываем функции aа=ОТРЕЗОК b=НАКЛОН. эмпирические коэффициенты регрессии соответственно равны: a = 76,976 b = 0,9204 Находим уравнение парной линейной регрессии, связывающей величину ежемесячной пенсии y с величиной прожиточного минимума x, которое имеет вид .yx = 76,9765 + 0,9204 x. Параметр регрессии позволяет сделать вывод, что с увеличением среднедушевого прожиточного минимума на 1 руб. среднедневная заработная плата возрастает в среднем на 0,92 руб.(или 92 коп.). 2. Расчёт тесноты статистической связи между результатом и фактором Тесноту линейной связи оценит коэффициент корреляции r xy : Коэффициент корреляции: rxy = b*σ x /σ y= 0,92 *12,952 / 6,533 =0,721; Т.к. значение коэффициента корреляции больше 0,7, то это говорит о наличии весьма тесной линейной связи между признаками.
Параметр R-квадрат, представляет собой квадрат коэффициента корреляции rxy2 и называется коэффициентом детерминации. Величина данного коэффициента характеризует долю дисперсии зависимой переменной y, объясненную регрессией (объясняющей переменной x). Соответственно величина 1 - rxy2 характеризует долю дисперсии переменной y, вызванную влиянием всех остальных, неучтенных в эконометрической модели объясняющих переменных Коэффициент детерминации: r2xy = 0,5199. Это означает, что 52% вариации заработной платы (y) объясняется вариацией фактора x – среднедушевого прожиточного минимума. Качество модели определяет средняя ошибка аппроксимации (2,7): Ā =(1/n)*Σ Ā i *100%=(1/12)* 69,02%= 5,752% Качество построенной модели оценивается как хорошее, так как A не превышает 10%. 3. Оценку статистической значимости уравнения регрессии в целом проведем с помощью F -критерия Фишера. Фактическое значение F критерия по формуле (2.9) составит
Табличное значение критерия при пятипроцентном уровне значимости и степенях свободы k1 = 1 и k2 = 12 - 2 = 10 составляет Fтабл = 4,96. (cм. Критерий Стьюдента). Так как Fфакт =10,41 > Fтабл = 4,96, то уравнение регрессии признается статистически значимым. Оценку статистической значимости параметров регрессии и корреляции проведем с помощью t -статистики Стьюдента и путем расчета доверительного интервала каждого из параметров. Табличное значение t -критерия для числа степеней свободы df = n - 2 = 12 - 2 = 10 и уровня значимости a= 0,05 составит tтабл = 2,23. Определим стандартные ошибки ma, mb, mr xy (остаточная дисперсия на одну степень свободы S2ост = 157,49): Фактические значения t -статистики превосходят табличное значение: ta = 3,17 > tтабл = 2,3; tb = 3,28 > tтабл = 2,3; trxy = 3,29 > tтабл = 2,3, поэтому параметры a, b и rxy не случайно отличаются от нуля, а статистически значимы. Рассчитаем доверительные интервалы для параметров регрессии a и b. Для этого определим предельную ошибку для каждого показателя: Δa=tтабл*ma=54,14583 Δb=tтабл*mb=0,625545 Доверительные интервалы γa =a ±Δa=76,98±24,21 23,03≤a*≤130,92 γb = b±Δb=0,92±4,17 = -3,24≤b*≤5,09 Анализ верхней и нижней границ доверительных интервалов приводит к выводу о том, что с вероятностью p = 1-a = 0,95 параметры a и b, находясь в указанных границах, не принимают нулевых значений, т.е. являются статистически значимыми и существенно отличны от нуля. 4. Полученные оценки уравнения регрессии позволяют использовать его для прогноза. Если прогнозное значение прожиточного минимума составит:
5. Ошибка прогноза составит:
Предельная ошибка прогноза, которая в 95% случаев не будет превышена, составит:
Доверительный интервал прогноза:
Выполненный прогноз среднемесячной заработной платы является надежным 6. В заключение решения задачи построим на одном графике исходные данные (рис. 2.1):
|
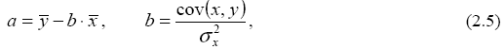


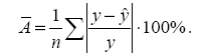 (2.7)
(2.7) показывает, на сколько процентов в среднем по совокупности изменится результат у от своей средней величины при изменении фактора x на 1% от своего среднего значения:
показывает, на сколько процентов в среднем по совокупности изменится результат у от своей средней величины при изменении фактора x на 1% от своего среднего значения:
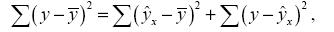
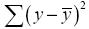 общая сумма квадратов отклонений;
общая сумма квадратов отклонений; 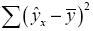 – сумма квадратов отклонений, объясненная регрессией (или факторная сумма квадратов отклонений);
– сумма квадратов отклонений, объясненная регрессией (или факторная сумма квадратов отклонений);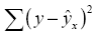 – остаточная сумма квадратов отклонений, характеризующая влияние неучтенных в модели факторов.
– остаточная сумма квадратов отклонений, характеризующая влияние неучтенных в модели факторов.
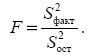
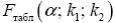 при уровне значимости α и степенях свободы k1= m и k2 = n - m -1. При этом, если фактическое значение F- критерия больше табличного, то признается статистическая значимость уравнения в целом.
при уровне значимости α и степенях свободы k1= m и k2 = n - m -1. При этом, если фактическое значение F- критерия больше табличного, то признается статистическая значимость уравнения в целом.
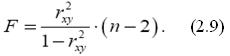
 b ar
b ar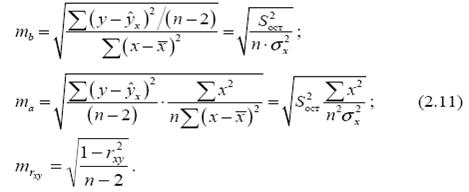


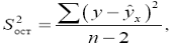 , и построением доверительного интервала прогнозного значения y*0:
, и построением доверительного интервала прогнозного значения y*0: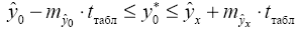
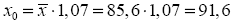 руб., тогда. индивидуальное прогнозное значение заработной платы составит:
руб., тогда. индивидуальное прогнозное значение заработной платы составит:
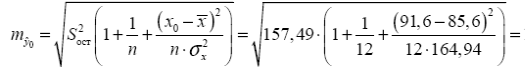 13,56
13,56 30,2
30,2