
Последовательный (линейный) поиск
Последовательный (линейный) поиск – это простейший вид поиска заданного элемента на некотором множестве, осуществляемый путем последовательного сравнения очередного рассматриваемого значения с искомым до тех пор, пока эти значения не совпадут. Идея этого метода заключается в следующем. Множество элементов просматривается последовательно в некотором порядке, гарантирующем, что будут просмотрены все элементы множества (например, слева направо). Если в ходе просмотра множества будет найден искомый элемент, просмотр прекращается с положительным результатом; если же будет просмотрено все множество, а элемент не будет найден, алгоритм должен выдать отрицательный результат. Алгоритм последовательного поиска Шаг 1. Полагаем, что значение переменной цикла i=0. Шаг 2. Если значение элемента массива x[i] равно значению ключа key, то возвращаем значение, равное номеру искомого элемента, и алгоритм завершает работу. В противном случае значение переменной цикла увеличивается на единицу i=i+1. Шаг 3. Если i<k, где k – число элементов массива x, то выполняется Шаг 2, в противном случае – работа алгоритма завершена и возвращается значение равное -1. При наличии в массиве нескольких элементов со значением key данный алгоритм находит только первый из них (с наименьшим индексом). int LinearSearch(int *x, int k, int key){ int i = 0; for (i = 0; i < k; i++) if (x[i] == key) break; return i < k? i: -1;}Время выполнения данного алгоритма поиска для вещественных чисел Недостатком рассматриваемого алгоритма поиска является то, что в худшем случае осуществляется просмотр всего массива. Поэтому данный алгоритм используется, если множество содержит небольшое количество элементов. Достоинства последовательного поиска заключаются в том, что он прост в реализации, не требует сортировки значений множества, дополнительной памяти и дополнительного анализа функций. Следовательно, может работать в потоковом режиме при непосредственном получении данных из любого источника. Существует модификация алгоритма последовательного поиска, которая ускоряет поиск. Эта модификация является небольшим усовершенствованием рассмотренного алгоритма поиска. Идея поиска с барьером состоит в том, чтобы не проверять каждый раз в цикле условие, связанное с границами множества. Это можно обеспечить, установив в данном множестве так называемый барьер. Под барьером понимается любой элемент, который удовлетворяет условию поиска. Тем самым будет ограничено изменение индекса. Выход из цикла, в котором теперь остается только условие поиска, может произойти либо на найденном элементе, либо на барьере. Существует два способа установки барьера: дополнительным элементом или вместо крайнего элемента массива. //описание функции последовательного поиска с барьеромint LinearSearchWithBarrier(int *x, int k, int key){ x = (int *)realloc(x,(k+1)*sizeof(int)); x[k] = key; int i = 0; while (x[i]!= key) i++; return i < k? i: -1;}Заметим, что поиск с барьером работает быстрее, но временная сложность алгоритма остается такой же O(n), где n – количество элементов множества. Гораздо больший интерес представляют методы, не только работающие быстро, но и реализующие алгоритмы с меньшей сложностью.
|
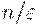 , где n – количество элементов множества, а
, где n – количество элементов множества, а 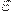 – точность. Поиск на дискретном множестве из n элементов осуществляется в худшем случае за n итераций, а в среднем этот алгоритм требует n/2 итераций цикла. Следовательно, временная сложность последовательного поиска пропорциональна O(n). Никаких ограничений на порядок элементов в массиве данный алгоритм не накладывает.
– точность. Поиск на дискретном множестве из n элементов осуществляется в худшем случае за n итераций, а в среднем этот алгоритм требует n/2 итераций цикла. Следовательно, временная сложность последовательного поиска пропорциональна O(n). Никаких ограничений на порядок элементов в массиве данный алгоритм не накладывает.


