
Визначення часу виконання MPI-програми
Реалізувати програму первісної обробки даних з використанням методу найменших квадратів для послідовності значень отриманих в результаті табуляції функції Таблиця 3.
Результатом роботи програми є знайдені коефіцієнти поліному а також графіки на яких повинно бути зображено наступні залежності:
Визначення часу виконання MPI-програми Отримати час поточного моменту виконання програми можна за допомогою функції: double MPI_Wtime (void), результатом виклику якої є кількість секунд, що минули від деякого певного моменту часу в минулому. Можлива схема застосування функції MPI_Wtime може полягати в наступному: double t1, t2, dt; t1 = MPI_Wtime(); … t2 = MPI_Wtime(); dt = t2 – t1; Точність вимірювання часу також може залежати від середовища виконання паралельної програми. Для визначення поточного значення точності може бути використана функція: double MPI_Wtick (void), що дозволяє визначити час у секундах між двома послідовними показниками часу апаратного таймера комп'ютерної системи, що використовується. 2. Передача даних від одного процесу всім процесам програми Досягнення ефективного виконання операції передачі даних від одного процесу всім процесам програми може бути забезпечено за допомогою функції MPI: int MPI_Bcast (void * buf, int count, MPI_Datatype type, int root, MPI_Comm comm). Функція MPI_Bcast здійснює розсилку даних з буфера buf, що містить count елементів типу type з процесу, що має номер root, всім процесам, що входять в комунікатор comm. 3. Передача даних від всіх процесів одному процесу. Операції редукції Для найкращого виконання дій, пов'язаних з редукцією даних, в MPI передбачена функція: int MPI_Reduce (void * sendbuf, void * recvbuf, int count, MPI_Datatype type, MPI_Op op, int root, MPI_Comm comm), де - Sendbuf - буфер пам'яті з повідомленням, що відправляється, - Recvbuf - буфер пам'яті для результуючого повідомлення (тільки для процесу з рангом root), - Count - кількість елементів у повідомленнях, - Type - тип елементів повідомлень, - Op - операція, яка повинна бути виконана над даними, - Root - ранг процесу, на якому повинен бути отриманий результат, - Comm - комунікатор, в рамках якого виконується операція.
4. Синхронізація обчислень Синхронізація процесів, тобто одночасне досягнення процесами тих чи інших точок процесу обчислень, забезпечується за допомогою функції MPI: int MPI_Barrier (MPI_Comm comm); Функція MPI_Barrier визначає колективну операцію і, тим самим, при використанні повинна викликатися всіма процесами комунікатора, що використовується. При виклику функції MPI_Barrier виконання процесу блокується, продовження обчислень процесу відбудеться тільки після виклику функції MPI_Barrier всіма процесами комунікатора. Приклад №4. Знайти суму елементів: Розробка паралельного алгоритму для рішення даної задачі не викликає труднощів – необхідно розділити дані на рівні блоки, передати ці блоки процесам, виконати в процесах підсумовування отриманих даних, зібрати значення обчислених часткових сум на одному з процесів і скласти значення часткових сум для отримання загального результату розв'язуваної задачі.
#include <stdio.h> #include "mpi.h" #include <stdlib.h>
int main(int argc, char *argv[]) { int my_rank; int numprocs; int n,i,sum; int a; int result; double wtime;
MPI_Init(&argc, &argv); MPI_Comm_rank(MPI_COMM_WORLD, &my_rank); MPI_Comm_size(MPI_COMM_WORLD, &numprocs); if (my_rank == 0) { printf("Input n:"); fflush(stdout); scanf("%d",&n); }
MPI_Bcast(&n,1,MPI_INT,0,MPI_COMM_WORLD); MPI_Barrier(MPI_COMM_WORLD); wtime=MPI_Wtime();
sum=0; for (i= my_rank; i<=n; i+=numprocs) { a=rand()%n+1; sum=sum+a; }
MPI_Reduce(&sum, &result,1,MPI_INT,MPI_SUM,0,MPI_COMM_WORLD); MPI_Barrier(MPI_COMM_WORLD); wtime=MPI_Wtime()-wtime; if (my_rank == 0) {
printf("suma=%d",result); printf("Working time: %.8lf seconds\n",wtime);
} MPI_Finalize(); return 0; }
Математичні функції на С++:
ІІ. Практична частина Інструкції до виконання Застосовуючи технологію паралельного програмування МРІ, написати програму для обчислення значення визначеного інтеграла, використовуючи метод трапеції. Завдання згідно варіанту (Додаток №1). Скласти порівняльнутаблицю часу виконання програми при різних характеристиках. Для роботи з програмою на двох комп’ютерах потрібно створити спільний ресурс. Додаток №1
Поточні контрольні питання: 7. Яка загальна будова МРІ-програм? 8. Які виділяють види обмінів повідомленнями? 9. Які основні складові повідомлення? 10. Яка функція дає можливість визначити ранг (кількість) процесів? 11. Яка функція дає можливість передати повідомлення від одного процесу іншому? 12. Яка функція дає можливість отримати повідомлення від одного процесу до іншого? Рекомендована література: 6. Антонов А.С. Параллельное программирование с использованием технологии МРІ. 7. Воеводин В. В., Воеводин Вл. В. Параллельные вычисления. – СПб.: БХВ-Петербург, 2002. – 608. 8. Гергель В.П. Теория и практика параллельных вычислений/Гергель В. П. – М.: ИНТУИР.РУ Интернет-Университет Информационных технологий, 2007. 9. Гергель В. П., Фурсов В.А. Лекции по параллельным вычислениям: учебное пособие – Самара: Изд-во Самар. гос.аерокосм. ун-та, 2009. – 164с. 10. Корнеев В. Д. Параллельное программирование в МРІ. – 2-е изд., испр. – Новосисбирск: Изд-во ИВМиМГ СО РАН 2002. – 215с.
Лабораторна робота №5 Мета: ознайомити студентів з паралельним алгоритмом Флойда-Уоршела. Професійна спрямованість: сприяє формуванню інтересу і схильності до професії. І. Теоретичні відомості 1. Колективні операції передачі даних 1.1. Узагальнена передача даних від одного процесу всім процесам Виконання даної операції може бути забезпечено за допомогою функції: int MPI_Scatter (void * sbuf, int scount, MPI_Datatype stype, void * rbuf, int rcount, MPI_Datatype rtype, int root, MPI_Comm comm), де · sbuf, scount, stype - параметри повідомлення, що передається (scount визначає кількість елементів, що передаються на кожен процес), · rbuf, rcount, rtype - параметри повідомлення, що приймається в процесах, · root - ранг процесу, що виконує розсилку даних, · comm - комунікатор, в рамках якого виконується передача даних. 1.2. Узагальнена передача даних від всіх процесів одному процесу Для виконання цієї операції в MPI призначена функція: int MPI_Gather (void * sbuf, int scount, MPI_Datatype stype, void * rbuf, int rcount, MPI_Datatype rtype, int root, MPI_Comm comm), де · sbuf, scount, stype - параметри повідомлення, що передається, · rbuf, rcount, rtype - параметри повідомлення, що приймається, · root - ранг процесу, що виконує збір даних, · comm - комунікатор, у рамках якого виконується передача даних.
|
 на інтервалі
на інтервалі  з кроком 0.1, де
з кроком 0.1, де  випадкове число з рівномірним розподілом на інтервалі
випадкове число з рівномірним розподілом на інтервалі  . Функція
. Функція  відповідає номеру студента в журналі обліку і вибирається з таблиці 3. Вважаючи, що функціональна залежність між
відповідає номеру студента в журналі обліку і вибирається з таблиці 3. Вважаючи, що функціональна залежність між  та
та  ─ квадратична. Необхідно визначити коефіцієнти
─ квадратична. Необхідно визначити коефіцієнти 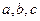 емпіричної формули
емпіричної формули  .
.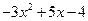

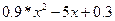



























 або
або  (згідно завдання)
(згідно завдання) .
.





