I.3. Лабораторная работа №3. Решение задач классификации методами Data Mining. Изменение и настройка набора данных
Для решения задач классификации не будем создавать отдельное хранилище данных, т.к. все необходимые данные находятся в одной таблице Диагноз файла базы данных Состояние пациентов.mdb.
Описание задачи Одной из основных задач, стоящих перед врачом, является диагностика заболевания. Для этого необходимо отнести пациента к одному из нескольких классов – например, " болен" и " здоров" – на основании данных о его текущем состоянии и истории болезни, т.е. решить задачу классификации. Построить систему, проводящую полную диагностику больного, достаточно сложно, поэтому, как правило, больного исследуют по определенному профилю, например, на предмет наличия отклонений в сердечно-сосудистой системе. Соответственно, количество факторов, на основании которых такой диагноз может быть вынесен, существенно снижается, что позволяет повысить скорость и точность работы алгоритма. Таблица Диагноз состоит из 150 записей, каждая из которых определяет 10 различных параметров больного и принадлежность его к классу.
1. Открыть новый проект. На панели «Сценарии» запустить Мастер импорта (кнопка 2. Изменить параметры исходного набора данных. (Это можно было сделать непосредственно при импорте данных). Выделить узел импорта, вызвать Мастер обработки – Настройка набора данных. Сделать изменения в настройках у полей: Пол – Строковый ТипГруднойБоли – Дискретный СахарВКрови – Дискретный Электрокардиограмма – Дискретный Стенокардия – Дискретный Талосемия – Дискретный Класс - Строковый
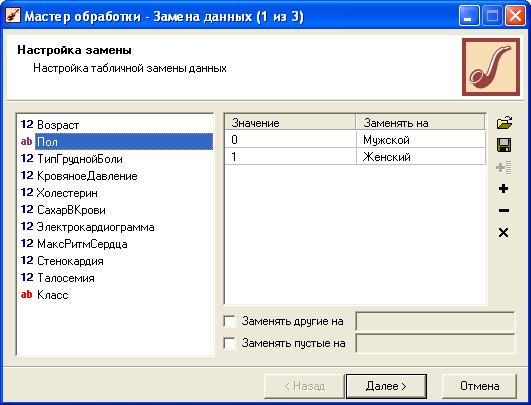
В качестве способа отображения выбрать Таблицу. Присвоить узлу метку Настройка набора данных. 3. Заменить значения (0; 1) в поле Пол на Мужской и Женский соответственно, а значения (1; 2) в поле Класс на Здоров и Болен. Выделить узел Настройка набора данных, вызвать Мастер обработки – Замена данных. Сделать изменения в настройках (добавлять новые изменяемые значения – кнопкой
Аналогичную процедуру произвести и для поля Класс. В качестве способа отображения выбрать Таблицу. Присвоить узлу метку Замена значений: Пол, Класс. 4. Решить поставленную задачу классификации с помощью Дерева решений. Выделить узел Замена значений: Пол, Класс, вызвать Мастер обработки – Дерево решений. В качестве выходного поля определить Класс, все остальные поля оставить входными. Настройку обучающего и тестового подмножеств оставить по-умолчанию заданной (95% и 5%). Построение дерева решений производится в процессе обучения. Настройки параметров обучения оставить следующими:
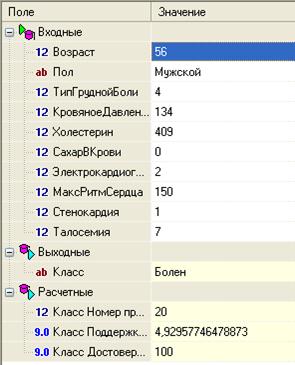
Далее следует запустить процесс построения дерева и выбрать в качестве визуализаторов: Дерево решений, Правила, Значимость атрибутов, Что-если, Таблица сопряженности. Присвоить узлу имя Дерево решений 1. Дерево решений состоит из узлов, где производится проверка условия, и листьев – конечных узлов дерева, указывающих на класс. Оценить качество построенного дерева по следующим параметрам: числу распознанных примеров (из таблицы сопряженности) по количеству узлов в дереве (чем больше узлов в дереве, тем сложнее проанализировать результат). По таблице Значимость атрибутов определить факторы, оказывающие наибольшее влияние на результат. Сделать прогноз о наличии или отсутствии заболевания при следующих значениях входных параметров:
5. Решить эту же задачу классификации с помощью Нейронной сети. Выделить узел Замена значений: Пол, Класс, вызвать Мастер обработки – Нейросеть. В качестве выходного поля определить Класс, все остальные - входные. Оставить все предложенные по-умолчанию настройки, запустить процесс обучения сети и выбрать в качестве визуализаторов: Граф неросети, Что-если, Таблица сопряженности. Присвоить узлу имя Нейросеть 1. Сделать прогноз о наличии или отсутствии заболевания при тех же значениях входных параметров, что и в п.4. Сравнить результаты. По Таблицам сопряженности для Дерева решений и Нейросети сделать вывод о более «качественной» модели классификации. Ответить на вопрос: совпадают ли выводы о наиболее значимых факторах, влияющих на состояние здоровья пациента (по Значимости атрибутов у Дерева решений и Графу нейросети)? 6. Разбить поле Возраст на интервалы (квантование значений числовых рядов). Выделить узел Замена значений: Пол, Класс, вызвать Мастер обработки – Квантование. Произвести настройку параметров квантования для поля Возраст:
Определить границы и метки интервалов следующим образом:
Выбрать в качестве способа визуализации выбрать Таблицу. Присвоить узлу метку Квантование по возрасту. 7. Выполнить для узла Квантование по возрасту п.4 и п.5. Узлы назвать Дерево решений 2 и Нейросеть 2 соответственно. Улучшилось или нет качество полученных моделей? Объяснить свой ответ.
II. Вопросы к зачету 1. В чем заключается итерационный характер процесса моделирования? 2. Основные этапы построения моделей. 3. Оценка адекватности модели. 4. Основные части аналитической платформы Deductor. 5. Понятие обработчика данных. Классификация обработчиков. 6. Способы визуализации данных. 7. Понятие сценария. Создание сценариев обработки и визуализации данных. 8. Мастера создания сценариев: мастер импорта, мастер экспорта, мастер обработки и мастер отображения (визуализации). 9 Понятие хранилища данных. Отличие хранилища данных от обычной базы данных. 10. Особенности работы с хранилищами данных. Преимущества хранилища данных. 11. Структура хранилища данных. Понятие измерения, факта и процесса. Свойства измерений. 12. Методика создания хранилища данных. Загрузка измерений. Загрузка процесса. 13. Подключение хранилища данных. 14. Определение OLAP. Аналитическая отчетность и многомерное представление данных. 15. Создание OLAP-кубов. Изменение макета OLAP-кубов. 16. Способы агрегирования данных. Детальный просмотр агрегированных данных. Фильтрация данных. Настройка кросс-диаграммы. 17. Преобразование даты и время в OLAP-кубах. 18. Создание пользовательских выражений в OLAP-кубах. 19. Создание OLAP-кубов на основе данных из разных процессов или источников. 20. Описание технологий Data Mining и KDD – Knowledge Discovery in Databases. Основные стадии технологии KDD. 21. Типы задач, решаемые методами Data Mining. 22. Примеры задач из области здравоохранения, решаемые методами Data Mining. 23. Метод Data Mining: Автокорреляция. 24. Метод Data Mining: Линейная регрессия. 25. Метод Data Mining: Логистическая регрессия. 26. Метод Data Mining: Нейронные сети. 27. Метод Data Mining: Деревья решений. 28. Метод Data Mining: Карты Кохонена. 29. Метод Data Mining: Ассоциативные правила. III. Список литературы
1. Аналитическая платформа Deductor 5. Руководство аналитика. (файл Руководство аналитика.pdf, поставляемый вместе с демо-версией Deductor 5.) – BaseGroup Labs, 1998-2007. -152 с. 2. Аналитическая платформа Deductor 5. Описание демонстрационного примера. (файл Описание демопримера.pdf, поставляемый вместе с демо-версией Deductor 5.) – BaseGroup Labs, 1998-2006. -91 с.
|

 или клавиша F6). На первом шаге мастера выбрать в качестве источника данных MS Access. На втором шаге – указать путь доступа к файлу базы данных Состояние пациентов.mdb и выбрать таблицу Диагноз. Указать имя узла – Импорт данных по заболеваниям.
или клавиша F6). На первом шаге мастера выбрать в качестве источника данных MS Access. На втором шаге – указать путь доступа к файлу базы данных Состояние пациентов.mdb и выбрать таблицу Диагноз. Указать имя узла – Импорт данных по заболеваниям.
 ):
):