
Методические указания. Таможенная инспекция провела 1%-ю проверку после выпуска товаров
Таможенная инспекция провела 1%-ю проверку после выпуска товаров. В результате получен следующий дискретный ряд распределения числа нарушений, выявленных в каждой проверке (табл. 22). Проведем анализ этого ряда распределения. Таблица 22. Ряд распределения числа нарушений, выявленных таможенной инспекцией
Этап 1. Данный в табл. 22 ряд распределения уже ранжирован в порядке возрастания числа нарушений, поэтому переходим сразу к расчету основного обобщающего показателя – среднего числа нарушений. Сначала рассчитаем среднее число нарушений в выборке, а также его дисперсию, для чего построим вспомогательную таблицу 23. Таблица 23. Ряд распределения числа нарушений, выявленных таможенной инспекцией
Среднее число нарушений в выборке по формуле (11), приняв за X число нарушений, а за N – численность выборки n: Дисперсию определим по формуле (46):
Затем определим среднюю ошибку выборки по формуле (33), так как число величин в генеральной совокупности N неизвестно: Предельная ошибка выборки при вероятности 0,95 по формуле (32): Доверительный интервал среднего числа нарушений в генеральной совокупности по формуле (35): Найдем еще обобщающий показатель – долю выпущенных товаров без нарушений d (т.е. с числом нарушений X =0). Доля таких товаров в выборке по формуле (6) составила: Дисперсия этой доли по формуле (66) [28] составила:
Средняя ошибка выборки по формуле (33): Предельная ошибка выборки при вероятности 0,95 по формуле (32): Доверительный интервал доли выпущенных товаров без нарушений в генеральной совокупности по формуле (36): d = 0,774 ± 0,147 или 0,627 Этап 2. Данный ряд распределения не имеет смысла превращать в интервальный в виду очень малой вариации значений признака. Построив график этого распределения (полигон) – рис. 15, видно, что данное распределение не похоже на нормальное. Рис. 15. Кривая распределения числа нарушений, выявленных таможенной инспекцией Этап 3. Из структурных характеристик ряда распределения можно определить только моду: Мо = 0, так как по данным табл. 23 такое число нарушений чаще всего встречается (f =24). Этап 4. По формуле (42) определим размах вариации: H = 3 – 0 = 3, что характеризует вариацию в 3 нарушения. По формуле (44) найдем среднее линейное отклонение:
Это означает, что в среднем число нарушений в выборке отклоняется от среднего числа нарушений на 0,55. Среднее квадратическое отклонение рассчитаем не по формуле (46), а как корень из дисперсии, которая уже была рассчитана нами на 1-м этапе: Поскольку квартили на предыдущем этапе не определялись, на данном этапе расчет среднего квартильного расстояния пропускаем. Теперь рассчитаем относительные показатели вариации: – относительный размах вариации по формуле (50): – линейный коэффициент вариации по формуле (51): – квадратический коэффициент вариации по формуле(52): Все расчеты на данном этапе свидетельствуют о значительных размере и интенсивности вариации нарушений, выявленных таможенной инспекцией. Этап 5. Не имеет практического смысла расчет моментов распределения, так как видно из рис. 15, что в изучаемом распределении симметрия отсутствует вовсе, поэтому и расчет эксцесса также бесполезен. Этап 6. Выдвинем гипотезу о соответствии изучаемого распределения распределению Пуассона[29], которое описывается формулой (67):
где P(X) – вероятность того, что признак примет то или иное значение X; e = 2,7182 – основание натурального логарифма; X! – факториал числа X (т.е. произведение всех целых чисел от 1 до X включительно); a = Из формулы (67) видно, что единственным параметром распределения Пуассона является средняя арифметическая величина. Порядок определения теоретических частот этого распределения следующий: 1) рассчитать среднюю арифметическую ряда, т.е. = a; 2) рассчитать e – a ; 3) для каждого значения X рассчитать теоретическую частоту по формуле (68):
Поскольку a = m0 = m2 = Полученные теоретические частоты занесем в 5-й столбец табл. 23 и построим график эмпирического и теоретического распределений (рис. 16), из которого видна близость эмпирического и теоретического распределений. Рис. 16. Эмпирическая и теоретическая (распределение Пуассона) кривые распределения Проверим выдвинутую гипотезу о соответствии изучаемого распределения закону Пуассона с помощью критериев согласия. Рассчитаем значение критерия Пирсона χ2 по формуле (62) в 6-м столбце табл. 23: χ2 =5,479, что меньше табличного (Приложение 7) значения χ2 табл=5,9915 при уровне значимости α; = 0,05 и числе степеней свободы ν= 4–1–1=2, значит с вероятностью 0,95 можно говорить, что в основе эмпирического распределения лежит закон распределения Пуассона, т.е. выдвинутая гипотеза не отвергается, а расхождения объясняются случайными факторами. Определим значение критерия Романовского по формуле (64):
Для расчета критерия Колмогорова в последних трех столбцах таблицы 23 приведены расчеты накопленных частот и разностей между ними, откуда видно, что в 1-ой группе наблюдается максимальное расхождение (разность) D = 2,3. Тогда по формуле (65):
|
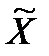 ) 2 f
) 2 f

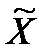 =
= 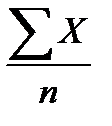 = 11/31 = 0,355 (нарушений).
= 11/31 = 0,355 (нарушений). =
=  = 0,552 (нарушений2).
= 0,552 (нарушений2). =
= 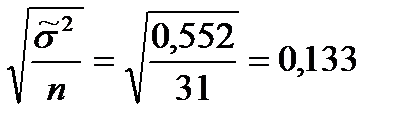 .
. = 1,96*0,133 = 0,261.
= 1,96*0,133 = 0,261.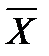 = 0,355 ± 0,261 или 0,094
= 0,355 ± 0,261 или 0,094 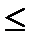
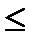 0,616 (нарушений), то есть среднее число нарушений по всей совокупности товаров, прошедших через таможенную границу, с вероятностью 0,95 лежит в пределах от 0,094 до 0,616 нарушений в 1 партии.
0,616 (нарушений), то есть среднее число нарушений по всей совокупности товаров, прошедших через таможенную границу, с вероятностью 0,95 лежит в пределах от 0,094 до 0,616 нарушений в 1 партии.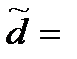 24/31 = 0,774, или 77,4%.
24/31 = 0,774, или 77,4%. = 0,774*(1–0,774) = 0,175. (66)
= 0,774*(1–0,774) = 0,175. (66)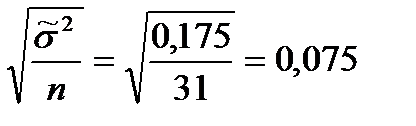 .
. .
.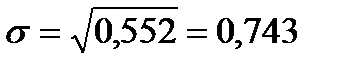 , тогда
, тогда  , т.е. в изучаемом распределении наблюдается некоторое число выделяющихся нарушений (с большим числом нарушений, выявленных в одной проверке).
, т.е. в изучаемом распределении наблюдается некоторое число выделяющихся нарушений (с большим числом нарушений, выявленных в одной проверке).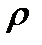 = 3/0,355 = 8,45;
= 3/0,355 = 8,45; = 0,550/0,355 = 1,55;
= 0,550/0,355 = 1,55;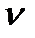 = 0,743/0,355 = 2,09.
= 0,743/0,355 = 2,09. , (67)
, (67)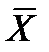 – средняя арифметическая ряда распределения.
– средняя арифметическая ряда распределения.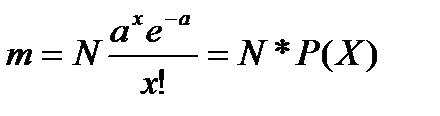 . (68)
. (68) = 0,355 найдем значение e – 0,355 =0,7012. Затем, подставив в формулу (68) значения X от 0 до 3, вычислим теоретические частоты:
= 0,355 найдем значение e – 0,355 =0,7012. Затем, подставив в формулу (68) значения X от 0 до 3, вычислим теоретические частоты: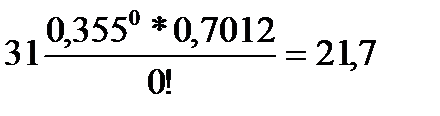 (т.к. 0! = 1); m1 =
(т.к. 0! = 1); m1 = 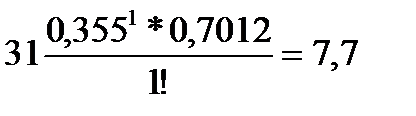 ;
; ; m3 =
; m3 =  .
.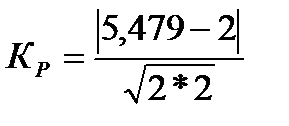 = 1,74 < 3, что подтверждает несущественность расхождений между эмпирическими и теоретическими частотами.
= 1,74 < 3, что подтверждает несущественность расхождений между эмпирическими и теоретическими частотами.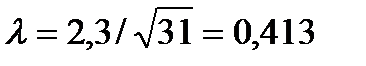 . По таблице Приложения 6 находим значение вероятности при λ = 0,4: P = 0,9972 (наиболее близкое значение к 0,413), т.е. с вероятностью, близкой к единице, можно говорить, что в основе эмпирического распределения величины нарушений, выявленных таможенной инспекцией, лежит закон распределения Пуассона, а расхождения эмпирического и теоретического распределений носят случайный характер.
. По таблице Приложения 6 находим значение вероятности при λ = 0,4: P = 0,9972 (наиболее близкое значение к 0,413), т.е. с вероятностью, близкой к единице, можно говорить, что в основе эмпирического распределения величины нарушений, выявленных таможенной инспекцией, лежит закон распределения Пуассона, а расхождения эмпирического и теоретического распределений носят случайный характер.


