
Зетта-наводнение
В 2008 году было создано около 5 экзабайт уникальной информации. Чтобы разместить такой объем данных, требуется 1 млрд DVD-дисков. Всего три года спустя размер уникальной информации возрос до 1,2 зеттабайта. Чтобы создать аналогичное количество данных в Твиттере, каждому жителю Земли пришлось бы размещать твиты в течение 100 лет. Если же пересчитать этот объем на размер файла длящегося один час телешоу, то такой видеозаписи хватило бы на непрерывное воспроизведение в течение 125 лет. В большей степени вся эта лавина информации – плод неуемной тяги людей к мультимедиа, особенно, к видео. К 2015 году свыше 90% данных во «всемирной паутине» будут приходиться на видеоконтент. Это создаст огромную нагрузку на сети и потребует оптимизации архитектуры безопасности, а также повышения качества услуг передачи данных.
К 2020 году треть всех данных будет храниться в облачных вычислительных средах или передаваться через них. Среднегодовой рост общемирового дохода от облачных сервисов составит 20%, а затраты на инновации и облачные вычисления к 2014 году могут достигнуть $1 трлн. Облачные сервисы уже способны переводить с одного языка на другой в реальном времени, обеспечивать доступ к мощным суперкомпьютерам вроде Wolfram Alpha и следить за состоянием нашего здоровья с помощью таких вычислительных платформ, как IBM Watson. Однако важно помнить, что вычислительные облака хороши настолько, насколько хороши используемые ими сети.
|
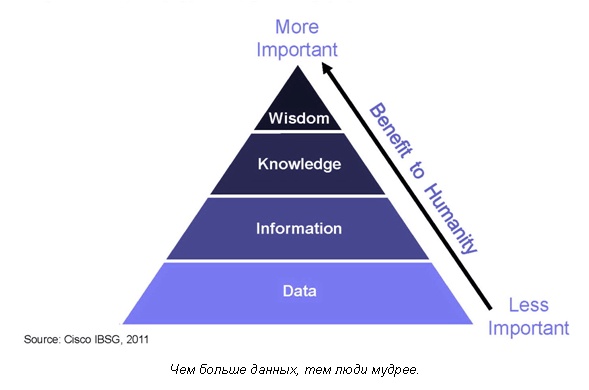 3. «Мудрые облака»
3. «Мудрые облака»


