Кэширование в процессоре PentiumВ процессоре Pentium кэширование используется в следующих случаях.
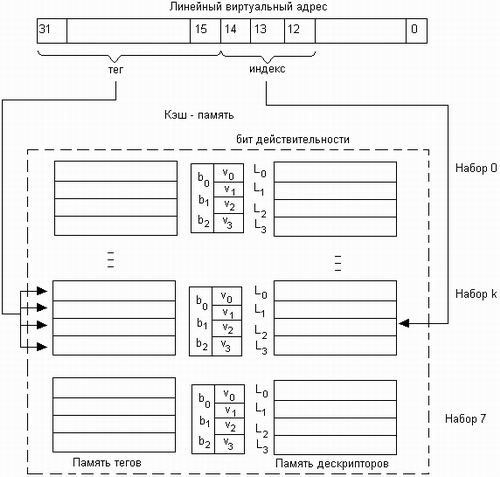
Рассмотрим более подробно принципы работы буфера ассоциативной трансляции и кэша первого уровня. Буфер ассоциативной трансляции В буфере TLB кэшируются дескрипторы страниц из таблицы страниц (рис. 6.17). Для хранения дескриптора в кэше отводится одна строка. Каждая строка дополнена тегом, в котором содержится номер соответствующей виртуальной страницы. Строки объединены по четыре в группы, называемые наборами. Таблица TLB, используемая для преобразования адресов инструкций, имеет 32 строки и соответственно 8 наборов. Номер набора называют индексом (index). Таким образом, путем кэширования может быть получен физический адрес для доступа к 32 страницам памяти, содержащим инструкции.
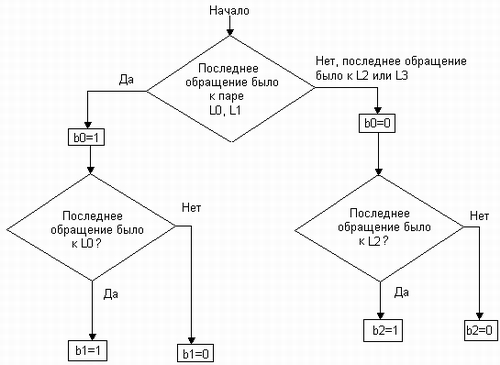
Рис. 6.17. Буфер ассоциативной трансляции После того как механизмом сегментации получен линейный адрес, он должен быть преобразован в физический адрес. Для этого прежде всего необходимо найти дескриптор страницы, к которой принадлежит данный адрес, и извлечь из него номер физической страницы. Обычная процедура предусматривает обращение к таблице разделов, а затем к таблице страниц. Однако физический адрес может быть получен гораздо быстрее благодаря тому, что в буфере TLB хранятся копии дескрипторов наиболее интенсивно используемых страниц. Поэтому перед тем, как начать сравнительно длительную процедуру преобразования адресов, делается попытка обнаружить нужный дескриптор страницы в быстрой ассоциативной памяти TLB. Затем на основании номера физической страницы, полученного из TLB, вычисляется физический адрес. При поиске данных в TLB используется линейный виртуальный адрес. Разряды 12-14 используются как индекс набора. Далее проверяются биты действительности v всех строк выбранного набора. В начале работы кэш-памяти биты действительности всех строк сбрасываются в нуль. Бит действительности принимает значение 1, когда в соответствующей строке содержится достоверная информация и сбрасывается в нуль, когда строка объявляется свободной, в результате работы алгоритма замещения. Для всех действительных строк выполняется ассоциативная процедура сравнения тегов со старшими разрядами (15-31 разряд) линейного виртуального адреса. Если произошло кэш-попадание, то номер физической страницы быстро поступает в схему формирования физического адреса. Если произошел промах и нужного дескриптора в TLB нет, то запускается многоэтапная процедура преобразования адреса, включающая обращения к таблицам разделов и страниц. Когда нужный дескриптор отыскивается в таблице страниц, он копируется в TLB. Номер набора, в который записывается кэшируемый дескриптор, определяется тремя младшими разрядами номера виртуальной страницы (разряды 12-14 линейного виртуального адреса). Однако поскольку в наборе имеется четыре строки, необходимо определить, в какую именно надо поместить кэшируемые данные. Дескриптор записывается либо в первую попавшуюся свободную строку, либо, если все строки заняты, в строку, к которой дольше всего не обращались. Признаком занятости строки служит бит действительности v, имеющийся у каждой строки. Если v=0, значит, строка свободна для записи в нее нового содержимого. Для определения строки, которая не использовалась дольше всех других в данном наборе, применяется упрощенный вариант алгоритма PseudoLRU (Pseudo Least Recently Used). Этот алгоритм основан на анализе трех бит: b0,b1, bЗ, называемых битами обращения. Биты обращения приписываются набору и устанавливаются в соответствии с алгоритмом, приведенном на рис. 6.18. Здесь L0, LI, L2, L3 обозначают последовательные строки набора. На замену выбирается одна из следующих строк: · L0, если b0=0 и b1=0; · L1, если b0=0 и b1=1; · L2, если b0=1 и b2=0; · L3, если b0=1 и b2=1.
Рис. 6.18. Алгоритм установки битов обращения Можно легко показать, что данная процедура не всегда приводит к выбору действительно дольше всех не вызывавшейся строки. Пусть, например, обращения к строкам выполнялись в следующей хронологической последовательности: L0, L2, L3, L1, то есть ближайшее по времени обращение было к строке L1, дольше же всего не было обращений к строке LO. Биты обращения в данном случае примут следующие значения. Поскольку последнее по времени обращение было к строке из пары (LO, L1), значит, Ь0=1. А в паре (L2, L3) последнее обращение было к L3, следовательно, Ь2=0. Отсюда, по правилу, приведенному выше, на замену выбирается строка L2, вместо строки L0, к которой на самом деле дольше всего не было обращений. Однако в большинстве случаев этот алгоритм дает результат, совпадающий с оптимальным. Например, для последовательности L0, L3, LI, L2 биты обращения имеют значения b0=0, b1=0, отсюда точное решение — L0. Даже в случае ошибки (вероятность которой составляет 33 %) решения, найденные по алгоритму PseudoLRU, близки к оптимальным. Так, в первом примере вместо строки L0, являющейся правильным решением, алгоритм дал ближайшую к ней по времени обращения строку L2. Несмотря на то что алгоритм PseudoLRU дает в общем случае приближенные решения, он широко применяется при кэшировании, так как является быстрым и экономичным, что чрезвычайно важно для кэш-памяти. Таким образом, в буфере TLB процессора Pentium используется комбинированный способ отображения кэшируемых данных на кэш-память: прямое отображение дескрипторов на наборы и случайное отображение на строки в пределах набора. Наличие TLB позволяет в подавляющем числе случаев заменить сравнительно долгую процедуру преобразования адресов, связанную с несколькими обращениями к оперативной памяти, быстрым поиском в ассоциативной памяти. Кэш первого уровня Кэш первого уровня используется на этапе обработки запроса к основной памяти по физическому адресу. Работа кэш-памяти первого уровня имеет много общего с работой буфера TLB. В TLB единицей хранения является дескриптор, а в кэше первого уровня — байт данных. Обновление данных в кэше происходит блоками по 16 байт. Таким образом, младшие 4 бита физического адреса байта могут интерпретироваться как смещение в блоке, а старшие разряды — как номер блока. Для хранения блоков данных в кэше отводятся строки, также имеющие объем 16 байт. Строки объединены в наборы по четыре. При объеме кэша 16 Кбайт в него входят 256 (28) наборов. При копировании данных в кэш номера блоков основной памяти прямо отображаются на номера наборов. Для этого в адресе основной памяти, относящегося к одному из байтов, входящих в блик, значение 8 битов, находящихся перед битами смещения, интерпретируется как номер набора в кэш-памяти (рис. 6.19). Остальные старшие биты адреса в дальнейшем используются в качестве тега.
Рис. 6.19. Кэш первого уровня процессора Pentium Так же как в TLB, выбор строки в наборе осуществляется на основе анализа битов действительности и битов обращения по алгоритму PseudoLRU. Блок данных заносится в строку кэш-памяти вместе со своим тегом — старшими разрядами адреса основной памяти. Бит действительности строки устанавливается в 1. При возникновении запроса на чтение из основной памяти вначале делается попытка найти данные в кэше (либо поиск в кэше совмещается с выполнением запроса к основной памяти). По индексу, извлеченному из адреса запроса, определяется набор, в котором могут находиться искомые данные. Затем для строк данного набора, содержимое которых действительно (установлены биты действительности), выполняется ассоциативный поиск: старшие разряды адреса из запроса сравниваются с тегами всех строк набора. Если для какой-нибудь строки фиксируется совпадение, это означает, что произошло кэш-попадание, и из соответствующей строки извлекается байт, смещение которого относительно начала строки определяется четырьмя младшими разрядами из адреса запроса. Для согласования данных в кэше первого уровня используется метод сквозной записи, то есть при возникновении запроса на запись обновляется не только содержимое соответствующей ячейки основной памяти, но и его копия в кэш-памяти. Заметим также, что запрос на запись при промахе не вызывает обновления кэша.
Совместная работа кэшей разного уровня Разные виды кэш-памяти вступают «в игру» на разных этапах обработки запроса к основной памяти. В зависимости от того, насколько удачно для запроса сложилась ситуация с попаданиями в кэш-память разного типа, время его выполнения может измениться в десятки раз. На рис. 6.20 показана схема выполнения запроса к памяти с сегментно-страничной организацией. Рассмотрим операцию считывания операнда из оперативной памяти по его виртуальному адресу — номеру виртуального сегмента и смещения в этом сегменте. Первое обращение к кэш-памяти происходит на этапе работы сегментного механизма, когда необходимо вычислить линейный виртуальный адрес, используя информацию дескриптора сегмента. Все дескрипторы сегментов, входящих в виртуальное адресное пространство процесса, хранятся в оперативной памяти, в таблицах GDT и LDT. Однако реального обращения к оперативной памяти может и не быть, если нужный сегмент является одним из активных сегментов процесса — в этом случае его дескриптор находится в соответствующем скрытом регистре. Кэширование дескрипторов сегментов предоставляет первую возможность сокращения времени доступа к оперативной памяти. Следующую возможность предоставляет буфер ассоциативной трансляции TLB, в котором кэшируются дескрипторы страниц, что позволяет сэкономить время при вычислении физического адреса. Вероятность кэш-попадания в данном случае очень велика — в среднем она составляет 98 %, и только 2 % обращений требуют действительного чтения таблиц разделов и страниц из оперативной памяти. При известном физическом адресе и известной степени везения искомый операнд может быть обнаружен в кэше первого уровня. Если же повезет немного меньше, то операнд найдется в кэше второго уровня.
Рис. 6.20. Использование кэширования на разных этапах обработки запроса (наиболее благоприятный путь выполнения запроса выделен утолщенной линией) Таким образом, наличие разнообразных кэшей в процессоре Pentium позволяет во многих случаях существенно сократить время обработки запроса к оперативной памяти.
Выводы
· набором привилегированных команд; · средствами защиты сегментов кодов и данных, обеспечивающими четыре уровня привилегий; · сегментным и сегментно-страничным механизмами виртуальной памяти; · механизмом быстрого переключения процессов с сохранением контекста; · встроенным кэшем оперативной памяти; · векторной системой прерываний.
· кэширование дескрипторов сегментов в скрытых регистрах процессора; · кэширование дескрипторов страниц в буфере ассоциативной трансляции TLB; · кэширование данных и инструкций в кэш-памяти первого уровня; · кэширование данных и инструкций в кэш-памяти второго уровня. Задачи и упражнения 1. Существует ли защищенный режим в большинстве современных процессоров или это специфический режим процессоров Pentium? 2. Значения каких системных регистров процессора должен использовать программный модуль ОС, чтобы произвести обращение к индивидуальной части памяти текущего процесса? 3. Представьте, что для задач всех уровней привилегий используется один общий стек. К каким последствиям это может привести? 4. Почему в сегменте состояния задачи TSS хранятся значения селекторов стека для уровней привилегий О, 1 и 2, но нет значения для селектора уровня 3? 5. В какой памяти — физической или виртуальной — задает положение сегмента при выключенном страничном механизме базовый адрес, хранимый в дескрипторе сегмента? 6. Зачем нужны шлюзы вызовов процедур и задач, если существует возможность непосредственного вызова? 7. Заполните следующую таблицу, в которой укажите возможность или невозможность непосредственного вызова процедуры со сменой кодового сегмента для различных сочетаний уровней привилегий вызывающего и вызываемого сегментов и типов сегментов.
8. Можно ли на базе процессора Pentium реализовать систему управления памятью с фиксированными разделами? 9. Можно ли выгружать страницы, которые хранят разделы таблицы страниц? 10. По каким соображениям в процессорах Pentium запрещено вызвать менее привилегированные процедуры, но разрешено вызывать менее привилегированные задачи? 11. В чем принципиальное отличие использования шлюза прерываний от использования шлюза задачи? 12. Поддерживает ли процессор Pentium приоритезацию запросов прерывания между несколькими внешними устройствами?
|