
ИЗМЕРЕНИЕ СВЯЗИ И ЗНАЧИМОСТИ ДЛЯ НОМИНАЛЬНЫХ ПЕРЕМЕННЫХ
Широко используемым коэффициентом связи для номинальных переменных, из которых одна считается зависимой, а другая – независимой, является λ; (лямбда) 3. Лямбда измеряет процентную долю того, насколько возможно угадывание значений зависимой переменной на основе знаний независимой переменной, если обе переменные представлены категориями, не содержащими ранга, интервала или направления. Представьте, например, что мы определяем партийную принадлежность 100 респондентов и выясняем, что частотное распределение выглядит следующим образом:
Представьте также, что мы хотим установить партийную принадлежность каждого отдельного респондента и сделать подобные предположения для всех лиц и что мы хотим при этом совершить минимум ошибок. Наиболее очевидный путь – определить моду (самую распространенную категорию); мы предполагаем, что это будут демократы. Мы окажемся правы в 50 случаях (для 50 демократов) и не правы в 50 случаях (для 30 республиканцев и 1 независимых); это не просто стоящее внимания замечание, но самое лучшее, что мы можем сделать, поскольку ни мы выберем республиканцев, то окажемся не правы 170 случаях, а если выберем независимых, то это приведет к 80 неверным предположениям. Таким образом, данная [c.417] мода обеспечивает наилучший уровень предположений для имеющейся в распоряжении информации. Но мы можем располагать еще одним набором данных, партийной принадлежности отца каждого респондента, представленным следующим распределением:
Если эти две переменные связаны друг с другом, т. е. если каждый отдельный респондент вероятнее всего принадлежит к той же партии, что и ее (или его) отец, то знание партийных предпочтений отца каждого респондента может помочь нам в определении партийных предпочтений самих респондентов. Это будет так в том случае, если, определяя для каждого респондента не моду всего распределения, как мы делали прежде, а просто партийную принадлежность его (или ее) отца, мы сможем снизить количество неверных предположений до уровня более низкого, чем 50 неверно определенных нами случаев. Чтобы это проверить, нужно построить таблицу сопряженности, подытоживающую распределение признаков по этим двум переменным. В табл. 15.1 независимая, или определяющая, переменная (партийная принадлежность отца) дана по рядам, ее итоговое распределение находится в правой части таблицы. Зависимая переменная (партийная принадлежность респондента) расположена по колонкам, и ее итоговое распределение находится в низу таблицы. Значения в таблице даны произвольно, и в действительности они, конечно, должны пересчитываться самим исследователем. Таблица 15.1. Определение партийности на основании партийной принадлежности отца (1)
[c.418] По этой таблице мы можем партийные предпочтения родителей использовать для определения партийных предпочтений респондентов. Для этого мы, как и раньше, определим моду, но только внутри каждой категории независимой переменной, а не по всему набору признаков. Таким образом, получится, что для тех респондентов, чьи отцы зафиксированы как демократы, мы прослеживаем предпочтение той же партии. Мы будем правы 45 раз и не правы 15 (для 5 республиканцев и 10 независимых). Для тех, чьи отцы зафиксированы республиканцами, мы предполагаем принадлежность к республиканской партии, при этом в 23 случаях мы окажемся правы и в 7 – не правы. Тех, чьи отцы зафиксированы независимыми, отнесем к независимым и будем правы в 5 из 10 случаев. Сравнив эти результаты, увидим, что теперь мы в состоянии верно предположить 73 раза и все еще ошибаемся 27 раз. Иными словами, наличие второй переменной существенно улучшило наши шансы. Для того чтобы точно определить процентную долю этого улучшения, используем общую формулу коэффициента связи.
В приведенном примере это выглядит так:
Используя партийную принадлежность отца в качестве определителя партийной принадлежности респондента, мы можем улучшить (ограничить количество ошибок) наши предположения примерно на 46%. Формула подсчета λ;, которая приведет нас к тем же результатам, хотя и несколько другим путем, такова:
[c.419] где fi – максимальная частота внутри каждой категории или градации независимой переменной; N – количество признаков. Лямбда изменяется в пределах от 0 до 1, где высшие (близкие к 1) значения обозначают сильную связь. Поскольку номинальные переменные не имеют направления, λ; всегда будет положительной. Следующий наш шаг – определить, чем вызваны взаимосвязи, выраженные λ;, – истинными параметрами совокупности или просто случаем, т.е. мы должны определить, являются ли эти взаимосвязи статистически значимыми. Для номинальных переменных тест на статистическую значимость проводится путем подсчета критерия χ2 (хи-квадрат). Этот коэффициент говорит нам о том, насколько вероятно, что номинальный тип связей, который мы только что наблюдали, является результатом случая. Это делается путем сравнения тех результатов, которые мы реально имеем, с теми, которые ожидаются тогда, когда между переменными нет никакой связи. Подсчет χ2 также начинается с таблицы взаимной сопряженности признаков, хотя и несколько отличающейся от табл. 15.1. Рассмотрим табл. 15.2. Таблица 15.2. Определение партийности на основании партийной принадлежности отца (2)
Эта таблица напоминает табл. 15.1 тем, что категории переменных те же самые, но табл. 15.2 не содержит никаких распределений в своих графах. Определение χ2 начинается с того, что мы задаем себе вопрос: какое значение мы ожидаем в каждой графе при [c.420] имеющихся итоговых распределениях, если между переменными нет связи? Для 60 респондентов, чьи отцы были демократами, например, мы можем ожидать, что половина (50/100) будут демократами, около трети (30/100) будут республиканцами и один из 5 (20/100) – независимым, или, другими словами, 30 демократов, 18 республиканцев и 12 независимых. Точно так же мы можем прикинуть ожидаемые значения для тех, у кого отцы были республиканцами или независимыми. Эти ожидаемые значения собраны в табл. 15.3. Таблица 15.3. Определение партийности на основании партийной принадлежности отца (3)
Тогда встает вопрос: действительно ли значения табл. 15.1 настолько отличаются от тех значений, которые можно предположить в табл. 15.3, что мы можем быть решительно уверены в надежности наших результатов? Хи-квадрат и является тем инструментом, который посредством сравнения двух таблиц даст ответ на наш вопрос. Уравнение для χ2 выглядит следующим образом:
где f0 – частота, наблюдаемая в каждой графе (см. табл. 15.1); Подсчитывается χ2 путем внесения значений в каждую графу табл. 15.4. [c.421] Таблица 15.4. Значения, используемые для получения χ2
Порядок граф таблицы не имеет значения, но f0 из табл. 15.1 и fe из табл. 15.3 в каждой определенной строке должны относиться к одному и тому же случаю. Причина того, что разность между f0 и fe сначала возводится в квадрат и лишь потом делится на fe, та же, что в случае колебаний вокруг среднего геометрического при определении стандартного отклонения. Хи-квадрат определяется путем сложения всех цифр в последней колонке. В нашем примере он получает значение 56,07. Прежде чем мы интерпретируем эту цифру, нам необходимо сделать еще одно вычисление – подсчитать так называемые степени свободы (degrees of freedom – df). Степени свободы в таблице – это количество ячеек таблицы, которые могут быть заполнены цифрами, прежде чем содержание всех остальных ячеек станет фиксированным и постоянным. Формула для определения степеней свободы в любой определенной таблице такова: df = (r – 1) (c – 1), где r = количество категорий переменной в ряду; Теперь мы готовы оценить статистическую значимость наших данных. Таблица А.4 в приложении содержит [c.422] значимые величины χ2 для различных степеней свободы на уровнях 0,001; 0,01; 0,05. Если значение χ2, которое мы подсчитали (56,07), превышает то, что указано в таблице на любом из этих уровней для таблицы с определенными степенями свободы (4), то можно сказать, что те взаимосвязи, которые мы наблюдали, на данном уровне статистически значимы. В настоящем случае, например, для того чтобы связь была значимой на уровне 0,001 (т.е. если мы допускаем, что наблюдаемая связь отражает характеристики всей совокупности, то мы рискуем ошибиться один раз из 1000), наблюдаемый χ2 должен превышать 18,467. Если это так, то мы можем быть абсолютно уверены в своих результатах. [c.423]
|

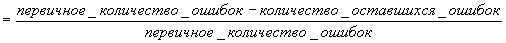

 ,
, ,
,


