
Значения, используемые для вычислений по уравнению регрессионной прямой
При линейной зависимости, т. е. такой, которая может быть представлена прямой линией, любое определенное изменение независимой переменной всегда вызывает определенное изменение значений зависимой переменной У. Более того, при таких зависимостях норма изменения постоянна, т. е. независимо от конкретных значений X и Y каждое изменение Х на единицу вызовет некоторое определенное изменение Y, размер которого определен степенью наклона линии регрессии. Зависимости, при которых небольшие изменения Х вызывают относительно [c.430] большие изменения Y, изображаются линиями, имеющими сравнительно крутой наклон (b 1). Зависимости, при которых большие изменения X вызывают меньшие изменения Y, изображаются прямыми с относительно пологим наклоном (b). Зависимости, при которых изменение Х на единицу вызывает изменение Y на единицу, изображаются прямыми, для которых b =1. Прямые, направленные вверх слева направо, как на рис. 15.4а и 15.4б, имеют положительный наклон и представляют зависимости, в которых увеличение Х вызывает увеличение Y. Прямые, направленные вниз слева направо, как на рис. 15.4г и 15.4д, имеют отрицательный наклон и представляют зависимости, в которых увеличение X вызывает уменьшение Y. Ясно, что угол наклона прямой – это просто норма изменения переменной Y на единицу изменения переменной X, т.е. в нашем примере, где b =0,12, линия регрессии будет направлена вниз слева направо и, если обе переменные изображены в одном масштабе, будет относительно пологой. Для того чтобы прийти к формуле, которую мы использовали для подсчета наклона линии регрессии, нам необходимо принять, что линия проходит через пересечение средних геометрических переменных и Y. Это – разумное допущение, поскольку средние геометрические представляют основную тенденцию этих переменных и поскольку мы, в сущности, ищем обобщенную или объединенную тенденцию. Если оба геометрических средних нам известны, а значение b определено, мы легко может найти значение а (точки, в которой линия регрессии пересекает ось Y) и решить уравнение. Общее уравнение регрессии таково: Y’ = a + bXi, а в точке, где линия регрессии проходит через пересечение двух средних геометрических, оно принимает вид:
Из этого следует, что a = Поскольку теперь мы знаем все нужные значения, мы можем определить, что [c.431] а = 12,88–(–0,12)(37,08)= 12,88+4,45= 17,33. Таким образом, уравнение регрессии, наилучшим образом подытоживающее распределение линии для данных, представленных на рис. 18.3, будет выглядеть так: Y’ = 17,33–0,12 Х. Используя это уравнение, мы можем вычислить значение Y для любого конкретного значения. Поскольку это уравнение решено, мы можем использовать коэффициент корреляции (r) для оценки репрезентативности линии регрессии. Формула rXY (коэффициента корреляции между X и Y) такова:
где Х – каждое значение независимой переменной (знак i применялся ранее для большей наглядности); Хотя это утверждение, безусловно, не так уж очевидно, а его алгебраическое доказательство лежит за рамками нашей книги, эта рабочая формула получена из сравнения первичной ошибки в предполагаемых значениях Y с использованием Таблица 15.7 Значения, используемые при определении коэффициента корреляции (r)
Мы подставляем итоговые значения в уравнение:
Это говорит нам о том, что наклон у линии регрессии отрицательный (что мы уже, собственно, знали) и что точки [c.433] группируются вокруг нее в ступени от слабой до умеренной (поскольку г изменяется в пределах от +1 до –1 с минимальной связью при r =0). К сожалению, сам коэффициент r интерпретировать нелегко. Можно, однако, интерпретировать r 2 как степень уменьшения ошибки в определении Y на основании значений X, т. е. доля значений Y, которые определяются (или могут быть объяснены) на основе Х. r 2обычно представляют как процентную долю объясненных значений, тогда как (1– r 2)– долю необьясненных значений. Так, в нашем примере r значением –0,38 означает, что для тех случаев, которые мы анализируем, разброс независимой переменной составляет (–0,38)2, или около 14%, значений зависимой переменной год обучения. По причинам, которые находятся за рамками настоящего разговора, определить статистическую значимость г можно только в том случае, если обе – и зависимая и независимая – переменные нормально распределены. Это можно сделать, используя табл. А.5 в Приложении А, для чего нужны следующие сведения. Во-первых, сам коэффициент г, который, конечно, известен. Во-вторых, аналогично подсчету χ2 количество степеней свободы линии регрессии. Поскольку прямую определяют любые две точки (в нашем случае пресечение
|
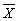 )
)
 )
)
 ,
,




