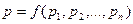Матричное объединение многослойных НС
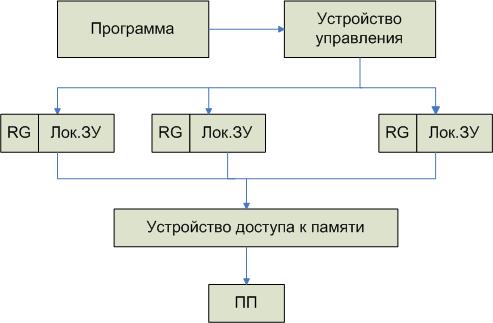
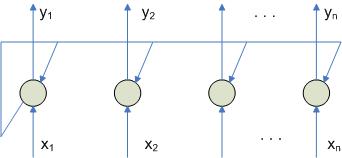
Матричное объединение многослойных НС Эта архитектура реализуется, если несколько линейных процессоров объединить в системы более высокого порядка. Схема будет выглядеть следующим образом:
В результате такой схемы отдельных линеек отдельных системных процессоров получается систолический массив, с помощью которого можно решать задачи. При этом атомарные элементы образуются на основе линейных массивов.
Реализация релаксационных НС на основе систолических массивов К этим типам сетей относятся сети Хопфилда, Хэмминга и т.д.
Для таких сетей необходимо соблюдение следующих условий: 1. 2. 3. для всех нейронов Следовательно, для окончания процедуры необходимо в систолическом массиве зафиксировать состояние равновесия.
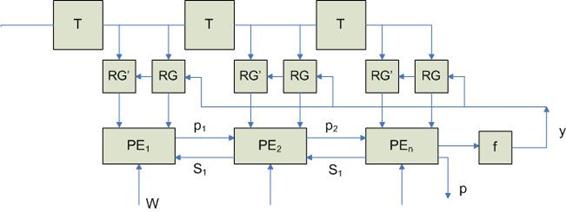
p – сигнал, определяющий состояние равновесия. Первые n тактов работы сети Хопфилда в регистры RG заносятся компоненты неизвестного образа, которые поступают извне. Затем – поступают данные с выхода. Основная задача – определить момент равновесия. Если p=1, то процедура обучения продолжается. Реализация процессорного элемента PE:
RG хранит текущее значение
Когда значение p какой-то схемы становится равным 1, то возникает прерывание и из регистра RG выделяется соответствующий компонент образа.
Теоретическое исследование параллельных структур вычислительных систем Чисто пользовательская архитектура – RAM (Random Access Machine). Машина параллельного типа – PRAM. Основные характеристики RAM: 1. последовательный доступ к памяти; 2. последовательная работа всех устройств (чтение, вычисление, запись); 3. время выполнения алгоритма зависит: - от объема; - от выполняемых действий; - от необходимости сохранения результата. Основные характеристики PRAM: 1. независимость от способа организации связей между процессорами, что обеспечивает концентрацию параллелизма в задаче; 2. архитектура состоит из процессорных элементов, связанных с глобальной памятью. Поэтому доступ в PRAM аналогичен доступу в однопроцессорной системе. Особенности PRAM: 1. состоит из отдельных процессорных элементов, каждый из которых является RAM; 2. каждый процессор имеет одно и то же время доступа к любой ячейке памяти; 3. связь между процессорами осуществляется через «доску объявлений»; 4. время выполнения – один шаг алгоритма.
Способы реализации PRAM PRAM – память с произвольным доступом, который не зависит от типа связи, что позволяет концентрироваться на алгоритмах решения задач.
Это теоретическая модель, в которой не учитываются нюансы реализации, предназначена для обработки параллельных алгоритмов. Работа модели осуществляется в 3 этапа: 1. чтение, которое одновременно может выполняться всеми процессорами; 2. выполнение программы процессорами; 3. запись. Вводятся различные типы команд: 1. ER (Exclusive Read) – выполнение чтения осуществляется только одним процессором; 2. CR (Concurrent Read) – выполнение чтения осуществляется одновременно всеми процессорами; 3. EW (Exclusive Write) – выполнение записи осуществляется только одним процессором; 4. CW (Concurrent Write) – выполнение записи осуществляется одновременно всеми процессорами;
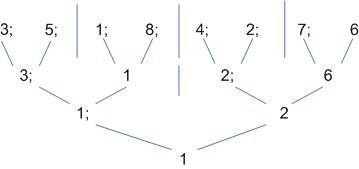
Разрешение конфликтов Разрешение конфликтов осуществляется при использовании различных вариантов записи и чтения. Схема разрешения конфликтов следующая: 1. CW с приоритетом – у каждого процессора свой приоритет; 2. общее CW – все процессоры должны записать свои значения в одну и ту же ячейку памяти; 3. произвольная запись одного из процессоров в заданную ячейку памяти. Если одновременно есть несколько процессоров, готовых к записи, то записывается значение одного из них. 4. объединяющая CW – если несколько процессоров хотят записать в ячейку памяти свой результат, то происходит объединение результатов. 4 наиболее распространенных модели для разрешения конфликтов записи/чтения: 1. CR EW – разрешается одновременное чтение, запрещена одновременная запись; 2. ER EW – более строгая модель, одновременная запись и чтение запрещены; 3. CR CW – одновременная запись и чтение разрешены; 4. ER CW. Таким образом, PRAM – модель параллельного вычислителя, который позволяет добиться оптимальной организации вычислительного процесса при выполнении некоторых фундаментальных алгоритмов. Выполнение алгоритма поиска минимума в массиве на параллельных системах Более эффективная процедура – использование метода сдваивания. Время реализации алгоритма пропорционально размерности массива.
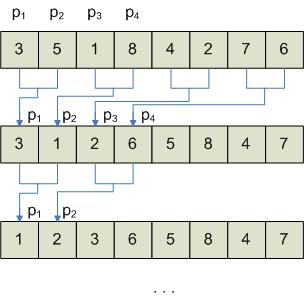
Таким образом – всего 3 шага. Для реализации алгоритма необходимо обрабатываемые данные поместить в горизонтальный массив. Каждый элемент – в отдельном регистре.
Число процессоров избыточно. Для более эффективной реализации возможны варианты: 1. сократить число процессоров; 2. понизить время реализации; 3. сократить число процессоров и понизить время реализации.
Улучшенный алгоритм поиска минимума: Пусть имеется P процессоров и D данных. Тогда для повышения эффективности каждому из процессоров поставим в соответствие D данных. На каждом этапе каждому процессору доступно D данных. Количество процессоров можно значительно понизить. Повышение эффективности работы алгоритма осуществляется за счет двухэтапной процедуры обработки элементов. Второй способ – поиск элемента в массиве. Весь массив разделяется на подмассивы, в которых каждый из процессоров ищет нужный элемент.
Ключевые понятия для организации вычислений в PRAM: разделяемая и распределенная память.
В первом случае каждый из процессоров имеет доступ ко всей памяти. Во втором случае процессор может обратиться к другому процессору только через механизм NUMA. Основные критерии оценки сети процессоров, которые используются для реализации параллельных алгоритмов: 1. степень сети – это количество двунаправленных каналов связи, подключенных к процессору. Показывает, со сколькими процессорами связан текущий процессор, т.е. фактически это максимальное число; 2. диаметр сети – максимум из минимальных расстояний между всеми процессорами в сети; 3. пропускная способность – минимальное количество связей между процессорами, которое надо удалить, чтобы получить две равные по размеру подсети; 4. время выполнения операций в сети процессора (фундаментальные операции: префиксное вычисление, сортировка и т.д.). Для снижения стоимости сети процессоров необходимо: 1. уменьшить время пересылки данных от одного процессора к другому; 2. для снижения количества конфликтов требуется максимальная пропускная способность; 3. минимальная степень сети.
Структуры сетей процессоров Различные модели сетей процессоров характеризуются следующими параметрами: 1. схемы взаимодействия процессоров между собой; 2. память должна быть распределена; 3. особенность архитектуры сети; 4. диаметр сети; и др. Два процессора являются соседями, если они связаны между собой каналом связи.
Линейная сеть процессоров
Каждый элемент связан с двумя соседями. Степень сети равна 2 для внутренних элементов и 1 – для крайних. Диаметр сети = n. Пропускная способность = 1.
Пример: Найти минимум в массиве: 3; 4; 2; 6; 15.
Повышение эффектив
|



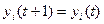
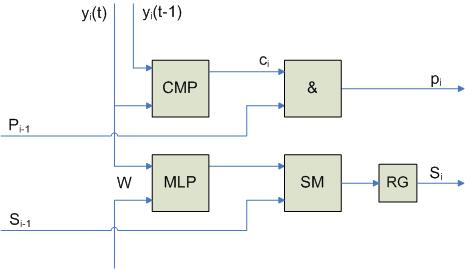

 , а RG’ – текущее значение
, а RG’ – текущее значение 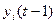 . В схеме сравнения используется суммирование по модулю 2. Общий сигнал p формируется как функция от всех выходов pi:
. В схеме сравнения используется суммирование по модулю 2. Общий сигнал p формируется как функция от всех выходов pi: