Построение иерархии диаграмм потоков данных
Первым шагом при построении иерархии DFD является построение контекстных диаграмм. Обычно при проектировании относительно простых ИС строится единственная контекстная диаграмма со звездообразной топологией, в центре которой находится так называемый главный процесс, соединенный с приемниками и источниками информации, посредством которых с системой взаимодействуют пользователи и другие внешние системы. Если же для сложной системы ограничиться единственной контекстной диаграммой, то она будет содержать слишком большое количество источников и приемников информации, которые трудно расположить на листе бумаги нормального формата, и кроме того, единственный главный процесс не раскрывает структуры распределенной системы. Признаками сложности (в смысле контекста) могут быть: - наличие большого количества внешних сущностей (десять и более); - распределенная природа системы; - многофункциональность системы с уже сложившейся или выявленной группировкой функций в отдельные подсистемы. Для сложных ИС строится иерархия контекстных диаграмм. При этом контекстная диаграмма верхнего уровня содержит не единственный главный процесс, а набор подсистем, соединенных потоками данных. Контекстные диаграммы следующего уровня детализируют контекст и структуру подсистем. Иерархия контекстных диаграмм определяет взаимодействие основных функциональных подсистем проектируемой ИС как между собой, так и с внешними входными и выходными потоками данных и внешними объектами (источниками и приемниками информации), с которыми взаимодействует ИС. Разработка контекстных диаграмм решает проблему строгого определения функциональной структуры ИС на самой ранней стадии ее проектирования, что особенно важно для сложных многофункциональных систем, в разработке которых участвуют разные организации и коллективы разработчиков. Пример контекстной диаграммы для системы сбора данных о деятельности учебных заведений показан на рисунке
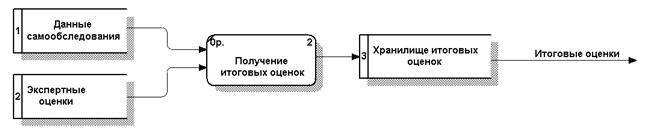
После построения контекстных диаграмм полученную модель следует проверить на полноту исходных данных об объектах системы и изолированность объектов (отсутствие информационных связей с другими объектами). Для каждой подсистемы, присутствующей на контекстных диаграммах, выполняется ее детализация при помощи DFD. Каждый процесс на DFD, в свою очередь, может быть детализирован при помощи DFD или миниспецификации. При детализации должны выполняться следующие правила: - правило балансировки - означает, что при детализации подсистемы или процесса детализирующая диаграмма в качестве внешних источников/приемников данных может иметь только те компоненты (подсистемы, процессы, внешние сущности, накопители данных), с которыми имеет информационную связь детализируемая подсистема или процесс на родительской диаграмме; - правило нумерации - означает, что при детализации процессов должна поддерживаться их иерархическая нумерация. Например, процессы, детализирующие процесс с номером 12, получают номера 12.1, 12.2, 12.3 и т.д. Миниспецификация (описание логики процесса) должна формулировать его основные функции таким образом, чтобы в дальнейшем специалист, выполняющий реализацию проекта, смог выполнить их или разработать соответствующую программу. Миниспецификация является конечной вершиной иерархии ДПД. Решение о завершении детализации процесса и использовании миниспецификации принимается аналитиком исходя из следующих критериев: - наличия у процесса относительно небольшого количества входных и выходных потоков данных (2-3 потока); - возможности описания преобразования данных процессом в виде последовательного алгоритма; - выполнения процессом единственной логической функции преобразования входной информации в выходную; - возможности описания логики процесса при помощи миниспецификации небольшого объема (не более 20-30 строк). При построении иерархии DFD переходить к детализации процессов следует только после определения содержания всех потоков и накопителей данных, которое описывается при помощи структур данных. Логика иерархии диаграмм описана в п. 3.2.3, она полностью применима и к DFD диаграммам. Структуры данных конструируются из элементов данных и могут содержать альтернативы, условные вхождения и итерации. Условное вхождение означает, что данный компонент может отсутствовать в структуре. Альтернатива означает, что в структуру может входить один из перечисленных элементов. Итерация означает вхождение любого числа элементов в указанном диапазоне. Для каждого элемента данных может указываться его тип (непрерывные или дискретные данные). Для непрерывных данных может указываться единица измерения (кг, см и т.п.), диапазон значений, точность представления и форма физического кодирования. Для дискретных данных может указываться таблица допустимых значений. После построения законченной модели системы ее необходимо верифицировать (проверить на полноту и согласованность). В полной модели все ее объекты (подсистемы, процессы, потоки данных) должны быть подробно описаны и детализированы. Выявленные недетализированные объекты следует детализировать, вернувшись на предыдущие шаги разработки. В согласованной модели для всех потоков данных и накопителей данных должно выполняться правило сохранения информации: все поступающие куда-либо данные должны быть считаны, а все считываемые данные должны быть записаны. Модель DFD являются одними из первых, которые строятся на этапе разработки системного проекта. Если далее будет строиться более детальная модель процессов стандарта IDEF0, то одной из основных задач модели DFD является выделение всех накопителей данных и основных информационных потоков. Пример диаграммы детализации показан на рис. 4.7.
Рис. 4.7 – Диаграмма детализации
Отметим, что на уровнях детализации, соответствующих основным и вспомогательным процессам, функциям и операциям, большая часть информационных потоков извлекается из накопителей данных и после обработки вновь поступает в накопители данных. Два процесса связывают непосредственно только те информационные потоки, которые не требуется сохранять в системе (немедленно обрабатываемое сообщение, вызов, команда и т.п.). Все данные, которые сохраняются в системе и могут быть использованы позднее, должны поступать в накопитель.
|
 Рис. 4.6 – Пример контекстной диаграммы потоков данных
Рис. 4.6 – Пример контекстной диаграммы потоков данных