Средства автономного использования
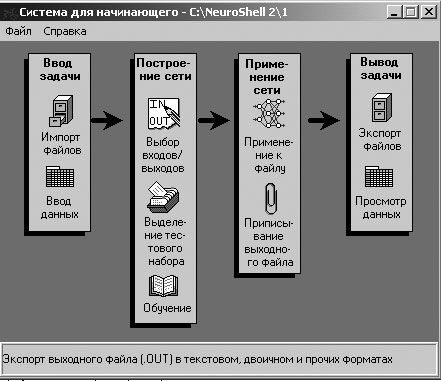
Средства автономного использования, входящие в состав пакета NeuroShell 2, позволяют использовать созданную нейронную сеть как динамическую библиотеку (DLL), которая может быть вызвана из других программ или из Microsoft Excel. Также можно осуществить генерацию программного кода на Си или Visual Basic для созданных сетей. Для использования нейронной сети вне NeuroShell 2 используется модуль Генератор автономных файлов. Генератор автономных файлов сохраняет сеть в файле таким образом, чтобы позднее можно было получить к ней доступ через динамическую библиотеку (DLL). Это наиболее удобный способ автономного использования сети из программ, работающих под Microsoft Windows. Например, если будет необходимость воспользоваться сетью позднее из программы, написанной на C, Pascal, Microsoft Visual Basic(TM), Visual C++(TM), Access и т.д., следует просто вызвать библиотечную функцию FireNet. Программа передаст этой функции значения входов, а FireNet вернет ответ сети. В Excel просто необходимо поместить функцию Predict в ячейку, указывая необходимые значения входов сети. В этой ячейке появится ответ сети. Генератор программного может представить натренированную сеть в виде программного кода самого общего вида на Си или Visual Basic. 1.1 Описание работы с «Системой для начинающего» Модуль Нейронные сети для начинающего представляет собой упрощенный набор процедур для построения и использования законченного, эффективного приложения на основе нейронной сети в рамках системы, работа с которой проще, чем работа с Системой для профессионала (рис.1). Система для начинающего использует трехслойную сеть с обратным распространением ошибки, универсальную архитектуру, обладающую способностью хорошо обобщать в широком диапазоне задач. Система для начинающих осуществляет предварительную установку параметров сети, таких, как скорость обучения, момент и количество скрытых нейронов. Вы вводите данные, указываете входы и выходы и тренируете сеть. Затем Вы можете применить натренированную сеть к новым данным и экспортировать результаты.
Рис.1 Экранная форма Системы для начинающего
Меню системы для начинающего состоит из четырех панелей: Ввод задачи 1. Импорт файлов - Этот модуль позволяет импортировать файлы из других систем во внутренний формат файлов NeuroShell 2. Этот внутренний формат совпадает с форматами Lotus 1-2-3.WK1 и Excel 4.XLS, поэтому при желании можно просматривать файл на любом этапе его обработки с помощью собственной программы электронных таблиц. (NeuroShell 2 работает с файлами.XLS электронных таблиц Excel по версию 4 включительно. Пользователи Excel версии 5.0 или выше могут сохранить файл как электронную таблицу Excel версии 4 или ниже, или воспользоваться модулем Импорт файлов электронных таблиц.) Поддерживается импорт файлов следующих форматов: - Импорт текстовых файлов - Импорт двоичных файлов - Импорт файлов электронных таблиц - Импорт файлов MetaStock - Импорт файлов Omega Downloader 2. Ввод данных - Для ввода данных непосредственно в формате NeuroShell 2 или для просмотра файлов после их обработки сетью используйте модуль Ввода данных. NeuroShell 2 позволяет использовать либо модуль Таблица NeuroShell 2, либо обычную программу электронных таблиц. Модуль Таблица ( установка по умолчанию). Это напоминающее программу электронных таблиц средство ввода данных, позволяющее вырезать, вставлять и перемещать данные, однако это не есть полностью функциональная программа электронных таблиц. Таблица была создана для работы только с небольшими файлами, и для больших файлов ее работа замедляется и становится менее эффективной. Программы электронных таблиц: Вы можете использовать подменю Установки Главного меню NeuroShell 2 для выбора программы электронных таблиц, которую бы хотели использовать в качестве альтернативного механизма ввода и просмотра данных в рамках NeuroShell 2. Когда используется программа электронных таблиц в качестве механизма ввода данных, необходимо сохранять файлы в формате.WK1 или Excel 4.XLS и добавлять в них информацию об интервалах, если в файле есть имена столбцов. Также существует возможность считывать в NeuroShell 2 файлы, созданные программами электронных таблиц, с помощью модуля Импорт файлов электронных таблиц. При использовании этого модуля информация об интервалах будет добавлена автоматически. Построение сети 1. Выбор входов/выходов - Этот модуль позволяет пользователю выбрать, какие переменные будут использоваться в качестве входов и выходов сети, а также указать либо вычислить значения минимума и максимума для каждой переменной. (Во внутреннем формате файлов NeuroShell 2 переменные являются столбцами, а примеры являются строками.) Этот модуль создает файл.MMX, который необходим как для тренировки сети, так и для обработки файла с помощью уже натренированной сети. - Выбор входов/выходов Этот модуль позволяет выбрать, какие переменные являются входами сети и какие - выходами. На экране появляется таблица, в которой в строке под названием Имя перечислены имена столбцов из файла данных. Чтобы увидеть возможные варианты использования столбцов, щелкните по стрелке в поле Выбор типа переменной. Щелчком мыши выберите тип переменной, который хотите устанавливать, из следующего списка: I Вход (Input) - Это переменные, используемые для осуществления предсказания или классификации (независимые переменные). A Выход (Actual output) - Результаты, которые сеть пытается обучиться предсказывать (зависимые переменные). Если Вы осуществляете классификацию данных, должны существовать по одному выходу для каждой возможной категории. Помечайте столбцы как A только при использовании типов сети, обучаемых с учителем (сети с обратным распространением ошибки, ВНС, НСОР и МГУА). (Пусто) Не используется - Значения, содержащиеся в столбце, поле типа для которого оставлено пустым, не будут использоваться для построения сети. Выбрав тип переменной, щелкните по ячейке в строке Тип, расположенной в столбце, назначение которого хотите задать. Если хотите пометить как переменные одного и того же типа более одного столбца, перемещением мыши подсветите (выберите) соответствующие ячейки в строке Тип переменной. Чтобы подсветить всю строку, щелкните по имени строки Тип. Если не пометите буквами I или A ни один из столбцов, сеть будет использовать весь файл. Сеть определит количества входов и выходов, основываясь на количествах нейронов во входном и выходном блоках, которые задаете в модуле Проектирование. Если метки I и A расставлены, но их расстановка не соответствует количествам нейронов во входном и выходном блоках, то при тренировке будут использоваться столбцы, помеченные буквами I и A, а не значения, заданные в блоках. - Установка минимумов/максимумов Поскольку нейронные сети требуют перевода переменных путем масштабирования в диапазоны от 0 до 1 или от -1 до 1, сети необходимо знать реальный диапазон изменения переменной. Воспользуйтесь этим модулем, чтобы ввести минимальное и максимальное значения для каждой переменной, которая должна использоваться сетью, или же можете вычислить искомый диапазон из данных автоматически, выбирая соответствующие пункты из меню Установки. В общем случае, используйте диапазон, границы которого вплотную примыкают к данным. (Вы можете захотеть указать значения минимума и максимума, которые будут меньше и больше соответствующих значений в файле данных, чтобы предусмотреть более широкий диапазон для будущих предсказаний, или можете предпочесть выбрать диапазон более узкий, чтобы исключить выбросы, которые могут повлиять на точность работы сети.) Если не установитm значения минимума и максимума вплотную к данным, сеть может потерять способность отслеживать мелкие различия в данных. Используйте меню Установки, чтобы автоматически установить значения минимумов и максимумов для переменных. Выбор пункта Задание минимумов или Задание максимумов позволяет ввести подходящее значение в появляющемся поле правки и записать это значение сразу во все выбранные ячейки. Выбор пункта Расчет мин/макс вызывает автоматическое вычисление минимальных и максимальных значений, а также средних и стандартных отклонений. При выборе пункта Расчет мин/макс по стандартному отклонению произойдет расчет минимальных и максимальных значений, отстоящих на указанное количество (N) стандартных отклонений от среднего значения для данной переменной. (Стандартное отклонение = квадратный корень из дисперсии, являющейся средним квадратичным отклонением от среднего. Это статистическая мера разброса в данных.) Появится диалоговое окно, в котором следует ввести в поле правки количество стандартных отклонений от 1 до 5, которое хотите использовать для расчета минимальных и максимальных значений. Минимальное значение будет установлено равным Среднее N * Стандартное_отклонение. Максимум будет установлен равным Среднее + N * Стандартное_отклонение. При задании N Вы можете использовать дробные значения, например, 1,75. При выборе пункта Изменение диапазона мин/макс появится диалоговое окно, в котором Вас попросят ввести процентное значение, на которое должен быть расширен диапазон между минимумом и максимумом. Заметим, что, прежде чем будет позволено воспользоваться этим пунктом меню, в таблицу Выбора входов и выходов уже должны быть введены минимальные и максимальные значения. 2. Выделение тестового набора - Этот модуль позволяет выделить тестовый и тренировочный наборы из файла данных. Воспользуйтесь этим модулем для выделения тестового набора и/или экзаменационного набора данных из числа тренировочных примеров. Тестовый набор может использоваться с Калибровкой, которая предотвращает перетренировку сетей, обеспечивая хорошее обобщение на новых данных. Калибровка используется сетями с обратным распространением ошибки, ВНС, НСОР и сетями МГУА. Экзаменационный набор может использоваться для проверки результатов работы сети на данных, которые сеть никогда не "видела" раньше. Исходный файл, обычно это.PAT-файл, остается без изменений. Методы выделения Этот модуль предлагает пять различных способов выделения данных из тренировочного набора. Выберите один из них, нажав на соответствующую кнопку переключателя. Все эти способы оставляют.PAT-файл нетронутым. 1. N процентов (тестовый набор), M процентов (экзаменационный набор), случайный выбор - Этот метод выделит N процентов.PAT-файла в тестовый набор (.TST) и/или M процентов.PAT-файла в экзаменационный набор (.PRO). Оставшаяся часть файла данных станет тренировочным набором (.TRN). По умолчанию, 20 процентов.PAT-файла выделяется в тестовый набор. Вы можете изменить процентные соотношения между наборами, вводя новые значения процентов в поля правки. 2. Каждый N-й пример (тестовый набор), каждый M-й пример (экзаменационный набор) - Этот метод выделит каждый N-й пример из.PAT-файла в тестовый набор (.TST) и/или каждый M-й пример из.PAT-файла в экзаменационный набор (.PRO). Оставшаяся часть файла данных станет тренировочным набором (.TRN). 3. Все примеры после N по M (тестовый набор), все после M (экзаменационный набор) - Используйте этот метод, если примеры, которые хотите включить в тестовый набор, находятся в конце файла. Этот метод выделит из.PAT-файла в тестовый набор (.TST) все примеры после N-го примера (с N+1-го) по M-й. Все примеры после M-го будут выделены в экзаменационный набор (.PRO). Оставшаяся часть файла данных станет тренировочным набором (.TRN). 4. Последние M примеров (экзаменационный набор), N процентов (тестовый набор), случайный выбор - Используйте этот метод для выделения экзаменационного набора от конца файла и случайного выбора тестового набора из оставшихся данных. Этот метод выделит последние M примеров.PAT-файла в экзаменационный набор (.PRO) и случайным образом выберет N процентов.PAT-файла из его оставшейся части в тестовый набор (.TST). Оставшаяся часть файла данных станет тренировочным набором (.TRN). 5. По метке строки - Используйте этот метод, если в файле данных есть столбец, содержащий символы (слова) или числа, которые могут быть использованы как ключевые слова при поиске для выделения примеров из файла. Необходимо задать один ключ для тестового набора, один ключ для тренировочного набора и, возможно, ключ для экзаменационного (.PRO) набора. Начало случайной последовательности - Если хотите изменить начало случайной последовательности, используемой для случайного выбора примеров, введите в текстовое поле другое число. По умолчанию это поле устанавливается равным 0, и, в случае использования установки по умолчанию, при каждом запуске процедуры извлечения в тестовый набор будут выделяться одни и те же примеры. Если измените начало случайной последовательности (оно может лежать в диапазоне от 0 до 32767), то примеры, выделяемые в тестовый набор, будут другими. Метка тренировочного набора - Используйте это текстовое поле для ввода буквенно-цифрового текста или числа, который (-ое) будет использоваться модулем при поиске в качестве ключевого слова для выделения тренировочного набора примеров при использовании метода метки строки. Все примеры с этой меткой попадут в тренировочный набор. Ключевой текст может включать пробелы. По умолчанию для обозначения строк файла данных, которые будут выделены в тренировочный набор, используется латинское "T". Метка тестового набора - Используйте это текстовое поле для ввода буквенно-цифрового текста или числа, который (-ое) будет использоваться модулем при поиске в качестве ключевого слова для выделения тестового набора примеров при использовании метода метки строки. Все примеры с этой меткой попадут в тестовый набор. Ключевой текст может включать пробелы. По умолчанию для обозначения строк файла данных, которые будут выделены в тестовый набор, используется латинское "P". Метка экзаменационного набора-Используйте это текстовое поле для ввода буквенно-цифрового текста или числа, который (-ое) будет использоваться модулем при поиске в качестве ключевого слова для выделения экзаменационного набора примеров при использовании метода метки строки. Все примеры с этой меткой попадут в экзаменационный набор. Вы можете захотеть создать экзаменационный набор, чтобы проверять результаты работы сети на данных, которые сеть никогда не "видела" раньше. Ключевой текст может включать пробелы. По умолчанию для обозначения строк файла данных, которые будут выделены в экзаменационный набор, используется латинское "V". Столбец для поиска- Выдается список столбцов в файле данных. При использовании метода метки строки щелчком мыши выберите столбец, содержащий ключевые метки для тренировочного, тестового и экзаменационного наборов.
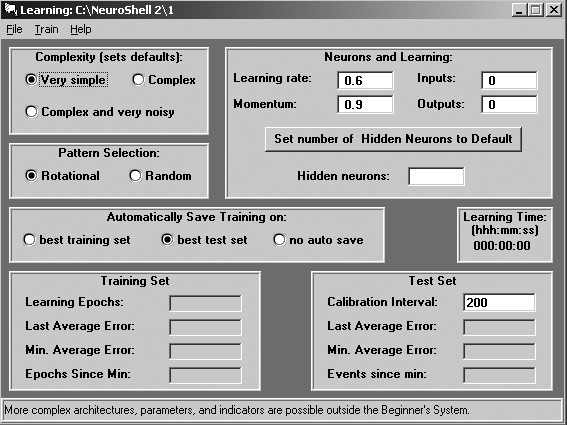
3. Обучение - Этот модуль позволяет выбрать параметры тренировки сети и осуществляет тренировку (рис.2). Это модуль, в котором сеть учит примеры данных из тренировочного набора. Тренировка продолжается, пока не будут выполнены условия, установленные в модуле Параметры тренировки и критерии остановки.
Рис.2. Экранная форма Параметры тренировки и критерии остановки Выбор примеров (Pattern Selection) Поочередный (Rotational) - Этот метод обеспечивает выбор тренировочных примеров в том порядке, в котором они появляются в.PAT-файле или в.TRN-файле, если используется Калибровка. Используйте его, если схожие тренировочные примеры равномерно распределены по тренировочному набору. Случайный (Random) - Этот метод обеспечивает случайный выбор тренировочных примеров, хотя он не гарантирует, что каждый пример будет выбран одинаковое количество раз. Используйте его, если тренировочный набор содержит примеры, чередующиеся циклически (например, данные об объеме продаж, подверженные сезонным изменениям), а Вы хотите, чтобы сеть давала ответы, не зависящие от этих изменений и от группировки примеров в файле. Рекуррентные сети должны тренироваться с поочередным выбором, поскольку для них порядок предъявления примеров важен. Сохранение сетей (Automatically Save Training) Для задания момента автоматической записи сети щелкните по одной из следующих кнопок переключателя: На тренировочном наборе (best training set) - сеть сохраняется каждый раз при достижении нового минимального значения средней ошибки на тренировочном наборе. Данный метод можно использовать, если НЕ используете Калибровку. (При использовании этого метода вычисление средней ошибки производится по окончании каждой эпохи.) На тестовом наборе (best test set) - сеть сохраняется каждый раз при достижении нового минимального значения средней ошибки на тестовом наборе. Если используете Калибровку, выберите этот метод. (Вычисления для тестового набора производятся по окончании указанного количества событий.) Не нужно (no auto save) - сеть не сохраняется. Вы можете захотеть использовать этот режим для ускорения тренировки в начале, когда сеть все время находит новые значения минимальной ошибки, но необходимо сохранить сеть, прежде чем закрыть модуль. Когда новые значения минимальной ошибки будут попадаться уже не так часто, Вы можете захотеть включить автоматическую запись сети, выбирая На тренировочном наборе или На тестовом наборе. Вы можете изменять метод автоматической записи сети в процессе тренировки. Чтобы автоматически остановить тренировку, установите соответствующие флажки и укажите числа, соответствующие выбранным критериям остановки на тестовом и/или на тренировочном наборе. Если выбрано более одного критерия, тренировка будет прекращена, как только будет выполнен любой из них: Критерии на тренировочном наборе (Training Set)- Вычисляются в конце каждой эпохи Средняя ошибка меньше указанного уровня. Количество эпох после достижения минимальной средней ошибки превышает указанное. Наибольшая ошибка меньше указанного уровня. Количество эпох обучения превысило указанное значение. Критерии на тестовом наборе (Test Set) - Вычисляются в конце интервала Калибровки Средняя ошибка меньше указанного уровня. Количество событий после достижения минимальной средней ошибки превышает указанное. Наибольшая ошибка меньше указанного уровня. Нейроны и скорость обучения (Neurons and Learning) Скорость обучения (Learning Rate) Всякий раз, когда сети в процессе тренировки предъявляется тренировочный пример, веса, ведущие к выходам, слегка изменяются в направлении, необходимом для уменьшения ошибки при следующем предъявлении того же примера. Величина подстройки весов равна произведению скорости обучения на ошибку. Например, если скорость обучения равна 0,5, изменение весов равно половине ошибки. Чем больше скорость обучения, тем больше изменения весов, и тем быстрее будет происходить обучение. Если скорость обучения слишком велика, могут возникать колебания и процесс может "не сойтись". Момент (Momentum) Большие значения скорости обучения часто приводят к колебаниям изменений весов, и обучение либо никогда не кончается, либо модель сходится к не оптимальному решению. Одним из способов обеспечить возможность более быстрого обучения без колебаний состоит в том, чтобы сделать изменение весов функцией от предыдущего изменения весов, что имеет эффект сглаживания. Момент определяет долю последнего изменения весов, которая добавляется к новому изменению весов. Вход (Input) Вход - это переменная, используемая сетью для классификации или предсказания. Ученые называют ее независимой переменной. Выход (Actual Output) Выход - это переменная в тренировочных примерах, значение которой сеть должна предсказать или которая содержит желаемый результат классификации. Применение сети 1. Применение к файлу - Этот модуль пропускает файл данных через натренированную сеть, создавая новый файл, содержащий предсказания или классификации, сделанные сетью. Воспользуйтесь этим модулем для обработки файла данных натренированной нейронной сетью, чтобы получить классификацию или предсказания сети для каждого примера в файле. Будет получен выходной файл (.OUT-файл). 2. Приписывание выходного файла - Этот модуль объединяет новый файл, содержащий ответы сети, с исходным файлом данных. Вы также можете использовать этот модуль для объединения любых двух файлов во внутреннем формате (файлов электронных таблиц). Воспользуйтесь этим модулем, чтобы приписать два существующих файла один к другому сбоку или снизу. Приписывание файла сбоку Этот модуль обычно используют, когда хотят сравнить результаты классификации или предсказания сети с данными, использованными для тренировки сети. Этот модуль объединяет файлы, «приклеивая» результаты классификации или предсказания сети к файлу данных справа. Приписывание файлов снизу Используйте этот модуль, чтобы объединить два файла в один, например, когда хотите добавить дополнительные данные в существующий файл. Оба файла должны содержать одни и те же переменные в одних и тех же столбцах. Вывод задачи 1. Экспорт файлов - Этот модуль позволяет экспортировать файлы из внутреннего формата файлов NeuroShell 2. Этот внутренний формат совпадает с форматами электронных таблиц Lotus 1-2-3.WK1 и Excel 4.XLS, поэтому можете просматривать файл на любом этапе его обработки с помощью программы электронных таблиц. Поддерживается экспорт файлов следующих форматов: - Экспорт текстовых файлов - Экспорт двоичных файлов - Экспорт файлов электронных таблиц 2. Просмотр данных - Этот модуль(известныq также как Таблица) позволяет просматривать файлы после их обработки сетью. По умолчанию в Таблицу передается.OUT-файл. Таблица - это напоминающее программу электронных таблиц средство ввода и просмотра данных, позволяющее вырезать, вставлять и перемещать данные, однако это не есть полностью функциональная программа электронных таблиц. Таблица была создана для работы только с небольшими файлами, и для больших файлов ее работа замедляется и становится менее эффективной.
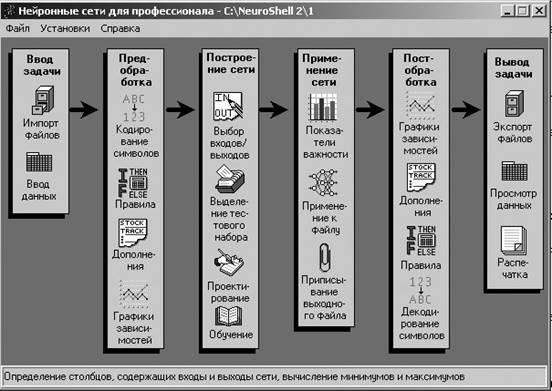
1.2 Описание работы с «Системой для профессионала» Система для профессионала (рис.3) предоставляет опытному пользователю нейронных сетей возможность создавать и применять нейронные сети множества разнообразных архитектур при более тщательном контроле за процессом со стороны пользователя по сравнению с Системой для начинающего. Система для профессионала может работать в двух разных режимах, которые можно переключать с помощью пунктов меню Установки: Проектирование и применение: Используется для создания сети и проверки результатов ее работы. Только применение: Используется для применения натренированной сети к новым файлам данных. Когда выбран этот режим, некоторые из значков модулей Системы для профессионала окрашиваются в серый цвет, так как эти модули не нужны и их использование в этом режиме заблокировано. По умолчанию в этом режиме модули Системы для профессионала будут использовать.PRO-файл, а не.PAT-файл.
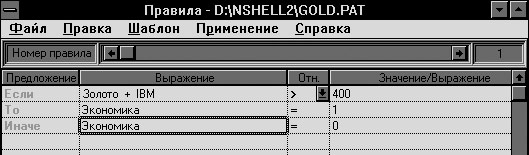
Рис. 3 Экранная форма Системы для профессионала Ввод задачи 1. Импорт файлов - Этот модуль позволяет импортировать файлы из других систем во внутренний формат файлов NeuroShell 2. Этот внутренний формат совпадает с форматами Lotus 1-2-3.WK1 и Excel 4.XLS, поэтому при желании можно просматривать файл на любом этапе его обработки с помощью собственной программы электронных таблиц. (NeuroShell 2 работает с файлами.XLS электронных таблиц Excel по версию 4 включительно. Пользователи Excel версии 5.0 или выше могут сохранить файл как электронную таблицу Excel версии 4 или ниже, или воспользоваться модулем Импорт файлов электронных таблиц.) Поддерживается импорт файлов следующих форматов: - Импорт текстовых файлов - Импорт двоичных файлов - Импорт файлов электронных таблиц - Импорт файлов MetaStock - Импорт файлов Omega Downloader 2. Ввод данных - Для ввода данных непосредственно в формате NeuroShell 2 или для просмотра файлов после их обработки сетью используйте модуль Ввода данных. NeuroShell 2 позволяет использовать либо модуль Таблица NeuroShell 2, либо обычную программу электронных таблиц. Модуль Таблица ( установка по умолчанию). Это напоминающее программу электронных таблиц средство ввода данных, позволяющее вырезать, вставлять и перемещать данные, однако это не есть полностью функциональная программа электронных таблиц. Таблица была создана для работы только с небольшими файлами, и для больших файлов ее работа замедляется и становится менее эффективной. Программы электронных таблиц: Вы можете использовать подменю Установки Главного меню NeuroShell 2 для выбора программы электронных таблиц, которую бы хотели использовать в качестве альтернативного механизма ввода и просмотра данных в рамках NeuroShell 2. Когда используется программа электронных таблиц в качестве механизма ввода данных, необходимо сохранять файлы в формате.WK1 или Excel 4.XLS и добавлять в них информацию об интервалах, если в файле есть имена столбцов. Также существует возможность считывать в NeuroShell 2 файлы, созданные программами электронных таблиц, с помощью модуля Импорт файлов электронных таблиц. При использовании этого модуля информация об интервалах будет добавлена автоматически. Предобработка 1. Кодирование символов - Этот модуль используется для легкого перекодирования текста (буквенно-цифровых строк или символов) в числовые значения, которые сеть способна обрабатывать. Например, с помощью этого модуля Вы можете преобразовать "холодно" в 0, "тепло" в 1 и "жарко" в 2. Для получения наилучших результатов преобразуйте символы в числа таким образом, чтобы сохранять относительный смысловой порядок значений, принимаемых переменными. Другими словами, не перекодируйте "тепло" в 0, "холодно" в 1 и "жарко" в 2, потому что при этом будет нарушен естественный порядок, существующий между значениями. Если отношений порядка между переменными не существует, эти переменные следует использовать как отдельные входные переменные. Например, если у Вас есть переменные Север, Юг, Восток и Запад, то не стоит перекодировать их в 1, 2, 3 и 4, так как нельзя сказать, что север сильнее (или слабее), чем запад. Вам следует создать четыре переменных, по одной для каждого региона (стороны света), и закодировать 1 присутствие в этом регионе и 0 отсутствие в нем. Чтобы кодировать символы: 1. Щелчком мыши поместите курсор в столбец Найти текст:.Введите текст (буквенно-цифровые данные), который хотите закодировать. Нажмите Еnter для завершения редактирования. 2. Щелчком мыши поместите курсор в столбец Закодировать значением: Введите числовое значение, которому должен соответствовать символ, и нажмите Enter. 3. Еще раз щелкните мышью, чтобы поместить курсор в столбец Преобразовать в следующих переменных: Выберите столбцы, где необходимо осуществить кодирование, щелкая по соответствующим переменным в поле Список переменных/столбцов. 4. Повторите описанную процедуру для каждого текстового символа, который желаете закодировать в данном файле. Модуль Кодирования символов позволяет Вам кодировать до 10 столбцов в одном файле данных. Заполнив таблицу кодирования, запустите обработку файла из меню Преобразование. В этом же меню есть пункт, позволяющий прервать преобразование. Перед выходом из модуля будет задан вопрос, хотите ли Вы сохранить таблицу кодирования символов. Если сохраните ее и позднее вернетесь в этот модуль для данной задачи, введенная информация останется на месте. 2. Правила - Этот модуль позволяет создавать правила типа "если/то/иначе" для предобработки данных. Используйте модуль Правила, чтобы применить правила для преобразования или предобработки данных перед тем, как они будут обрабатываться нейронной сетью. Например, Вы можете использовать две входные переменные для расчета значений третьей входной переменной. Допустим, Вы считаете, что, если сложить цену на золото и цену акций IBM и сумма будет больше 400, то экономическая ситуация улучшается. Вы можете преобразовать эту информацию в новый вход нейросети следующим образом:
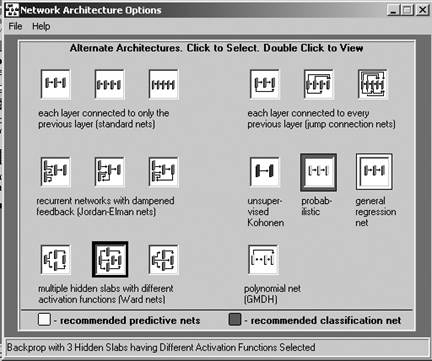
Рис.4. Экранная форма модуля Правила Вы можете также использовать модуль Правила для постобработки предсказаний и классификаций, сделанных сетью. Например, если выходы являются категориями и лежат в диапазоне от нуля до единицы, и Вы хотите, чтобы все значения в столбце 1, превышающие 0,5, преобразовывались в «истина» или в 1, то правило может иметь следующий вид: Если столбец 1 >= 0,5, то столбец 1 = 1, иначе столбец 1 = 0. Таким образом Вы можете установить Ваше собственное пороговое значение, в данном случае 0,5, для определения того, включать ли данный пример в выходную категорию. Существуют и множество других применений для правил, применяемых к выходным данным. 3. Дополнения - Этот модуль включает в себя три отдельно оплачиваемых дополнения, которые содержат средства предобработки данных фондового рынка и данных по срочным контрактам (фьючерсных), предобработки данных по результатам скачек, а также предобработки данных социологических опросов для прогнозирования результатов выборов. Пакет Рыночных индикаторов. Этот модуль позволяет построить сложный набор индикаторов, пользуясь необработанными данными фондового рынка или рынка ценных бумаг, такими, как high (наивысшая цена), low (наинизшая цена), close (цена закрытия) и volume (объем торгов). Пакет предсказания результатов скачек. Этот модуль позволяет осуществить предобработку данных о скачках, преобразуя их в форму, в которой сети легче их выучить. Пакет прогнозирования результатов выборов. Этот модуль позволяет осуществить предобработку данных социологических опросов, преобразуя их в форму, в которой сети легче их выучить. 4. Графики зависимостей - Этот модуль позволяет многими разнообразными способами строить графики зависимостей для одной или нескольких переменных сети. Подавая данные на вход сети, можете захотеть построить корреляционную диаграмму для двух переменных, чтобы убедиться, что примеры тренировочного набора являются представительными для всей области определения задачи. После обработки данных сетью можете построить график для сравнения предсказаний сети с реальными ответами. 1. График зависимостей по всем примерам. Позволяет построить зависимость одной или нескольких переменных по всем примерам в файле, даже если переменные имеют различные типы. Этот тип графиков полезен для анализа временных зависимостей. Так же есть возможность строить зависимости по выбранному количеству примеров. 2. График зависимостей внутри примера. Используйте этот тип графика, если все переменные в примере - одного типа, например, 100 точек в физиологическом сигнале, таком, как электрокардиограмма. На графике увидите, как выглядит эта кардиограмма. 3. Корреляционная точечная диаграмма. Позволяет построить зависимость одной переменной от другой для всех примеров, что демонстрирует корреляцию между ними. На этом графике отображается также линейный коэффициент корреляции между этими двумя переменными. 4. График High Low Close. Построение графика в переменных максимальная цена (high) - минимальная цена (low) - цена закрытия (close), используемых для рыночных предсказаний. Построение сети 1. Выбор входов/выходов - Выбор входов/выходов - Этот модуль позволяет пользователю выбрать, какие переменные будут использоваться в качестве входов и выходов сети, а также указать либо вычислить значения минимума и максимума для каждой переменной. (Во внутреннем формате файлов NeuroShell 2 переменные являются столбцами, а примеры являются строками.) Этот модуль создает файл.MMX, который необходим как для тренировки сети, так и для обработки файла с помощью уже натренированной сети. - Выбор входов/выходов Этот модуль позволяет выбрать, какие переменные являются входами сети и какие - выходами. На экране появляется таблица, в которой в строке под названием Имя перечислены имена столбцов из файла данных. Чтобы увидеть возможные варианты использования столбцов, щелкните по стрелке в поле Выбор типа переменной. Щелчком мыши выберите тип переменной, который хотите устанавливать, из следующего списка: I Вход (Input) - Это переменные, используемые для осуществления предсказания или классификации (независимые переменные). A Выход (Actual output) - Результаты, которые сеть пытается обучиться предсказывать (зависимые переменные). Если Вы осуществляете классификацию данных, должны существовать по одному выходу для каждой возможной категории. Помечайте столбцы как A только при использовании типов сети, обучаемых с учителем (сети с обратным распространением ошибки, ВНС, НСОР и МГУА). (Пусто) Не используется - Значения, содержащиеся в столбце, поле типа для которого оставлено пустым, не будут использоваться для построения сети. Выбрав тип переменной, щелкните по ячейке в строке Тип, расположенной в столбце, назначение которого хотите задать. Если хотите пометить как переменные одного и того же типа более одного столбца, перемещением мыши подсветите (выберите) соответствующие ячейки в строке Тип переменной. Чтобы подсветить всю строку, щелкните по имени строки Тип. Если не пометите буквами I или A ни один из столбцов, сеть будет использовать весь файл. Сеть определит количества входов и выходов, основываясь на количествах нейронов во входном и выходном блоках, которые задаете в модуле Проектирование. Если метки I и A расставлены, но их расстановка не соответствует количествам нейронов во входном и выходном блоках, то при тренировке будут использоваться столбцы, помеченные буквами I и A, а не значения, заданные в блоках. - Установка минимумов/максимумов Поскольку нейронные сети требуют перевода переменных путем масштабирования в диапазоны от 0 до 1 или от -1 до 1, сети необходимо знать реальный диапазон изменения переменной. Воспользуйтесь этим модулем, чтобы ввести минимальное и максимальное значения для каждой переменной, которая должна использоваться сетью, или же можете вычислить искомый диапазон из данных автоматически, выбирая соответствующие пункты из меню Установки. В общем случае, используйте диапазон, границы которого вплотную примыкают к данным. (Вы можете захотеть указать значения минимума и максимума, которые будут меньше и больше соответствующих значений в файле данных, чтобы предусмотреть более широкий диапазон для будущих предсказаний, или можете предпочесть выбрать диапазон более узкий, чтобы исключить выбросы, которые могут повлиять на точность работы сети.) Если не установитm значения минимума и максимума вплотную к данным, сеть может потерять способность отслеживать мелкие различия в данных. Используйте меню Установки, чтобы автоматически установить значения минимумов и максимумов для переменных. Выбор пункта Задание минимумов или Задание максимумов позволяет ввести подходящее значение в появляющемся поле правки и записать это значение сразу во все выбранные ячейки. Выбор пункта Расчет мин/макс вызывает автоматическое вычисление минимальных и максимальных значений, а также средних и стандартных отклонений. При выборе пункта Расчет мин/макс по стандартному отклонению произойдет расчет минимальных и максимальных значений, отстоящих на указанное количество (N) стандартных отклонений от среднего значения для данной переменной. (Стандартное отклонение = квадратный корень из дисперсии, являющейся средним квадратичным отклонением от среднего. Это статистическая мера разброса в данных.) Появится диалоговое окно, в котором следует ввести в поле правки количество стандартных отклонений от 1 до 5, которое хотите использовать для расчета минимальных и максимальных значений. Минимальное значение будет установлено равным Среднее N * Стандартное_отклонение. Максимум будет установлен равным Среднее + N * Стандартное_отклонение. При задании N Вы можете использовать дробные значения, например, 1,75. При выборе пункта Изменение диапазона мин/макс появится диалоговое окно, в котором Вас попросят ввести процентное значение, на которое должен быть расширен диапазон между минимумом и максимумом. Заметим, что, прежде чем будет позволено воспользоваться этим пунктом меню, в таблицу Выбора входов и выходов уже должны быть введены минимальные и максимальные значения. 2. Выделение тестового набора - Этот модуль позволяет выделить тестовый и тренировочный наборы из файла данных. Воспользуйтесь этим модулем для выделения тестового набора и/или экзаменационного набора данных из числа тренировочных примеров. Тестовый набор может использоваться с Калибровкой, которая предотвращает перетренировку сетей, обеспечивая хорошее обобщение на новых данных. Калибровка используется сетями с обратным распространением ошибки, ВНС, НСОР и сетями МГУА. Экзаменационный набор может использоваться для проверки результатов работы сети на данных, которые сеть никогда не "видела" раньше. Исходный файл, обычно это.PAT-файл, остается без изменений. Методы выделения Этот модуль предлагает пять различных способов выделения данных из тренировочного набора. Выберите один из них, нажав на соответствующую кнопку переключателя. Все эти способы оставляют.PAT-файл нетронутым. 1. N процентов (тестовый набор), M процентов (экзаменационный набор), случайный выбор - Этот метод выделит N процентов.PAT-файла в тестовый набор (.TST) и/или M процентов.PAT-файла в экзаменационный набор (.PRO). Оставшаяся часть файла данных станет тренировочным набором (.TRN). По умолчанию, 20 процентов.PAT-файла выделяется в тестовый набор. Вы можете изменить процентные соотношения между наборами, вводя новые значения процентов в поля правки. 2. Каждый N-й пример (тестовый набор), каждый M-й пример (экзаменационный набор) - Этот метод выделит каждый N-й пример из.PAT-файла в тестовый набор (.TST) и/или каждый M-й пример из.PAT-файла в экзаменационный набор (.PRO). Оставшаяся часть файла данных станет тренировочным набором (.TRN). 3. Все примеры после N по M (тестовый набор), все после M (экзаменационный набор) - Используйте этот метод, если примеры, которые хотите включить в тестовый набор, находятся в конце файла. Этот метод выделит из.PAT-файла в тестовый набор (.TST) все примеры после N-го примера (с N+1-го) по M-й. Все примеры после M-го будут выделены в экзаменационный набор (.PRO). Оставшаяся часть файла данных станет тренировочным набором (.TRN). 4. Последние M примеров (экзаменационный набор), N процентов (тестовый набор), случайный выбор - Используйте этот метод для выделения экзаменационного набора от конца файла и случайного выбора тестового набора из оставшихся данных. Этот метод выделит последние M примеров.PAT-файла в экзаменационный набор (.PRO) и случайным образом выберет N процентов.PAT-файла из его оставшейся части в тестовый набор (.TST). Оставшаяся часть файла данных станет тренировочным набором (.TRN). 5. По метке строки - Используйте этот метод, если в файле данных есть столбец, содержащий символы (слова) или числа, которые могут быть использованы как ключевые слова при поиске для выделения примеров из файла. Необходимо задать один ключ для тестового набора, один ключ для тренировочного набора и, возможно, ключ для экзаменационного (.PRO) набора. Начало случайной последовательности - Если хотите изменить начало случайной последовательности, используемой для случайного выбора примеров, введите в текстовое поле другое число. По умолчанию это поле устанавливается равным 0, и, в случае использования установки по умолчанию, при каждом запуске процедуры извлечения в тестовый набор будут выделяться одни и те же примеры. Если измените начало случайной последовательности (оно может лежать в диапазоне от 0 до 32767), то примеры, выделяемые в тестовый набор, будут другими. Метка тренировочного набора - Используйте это текстовое поле для ввода буквенно-цифрового текста или числа, который (-ое) будет использоваться модулем при поиске в качестве ключевого слова для выделения тренировочного набора примеров при использовании метода метки строки. Все примеры с этой меткой попадут в тренировочный набор. Ключевой текст может включать пробелы. По умолчанию для обозначения строк файла данных, которые будут выделены в тренировочный набор, используется латинское "T". Метка тестового набора- Используйте это текстовое поле для ввода буквенно-цифрового текста или числа, который (-ое) будет использоваться модулем при поиске в качестве ключевого слова для выделения тестового набора примеров при использовании метода метки строки. Все примеры с этой меткой попадут в тестовый набор. Ключевой текст может включать пробелы. По умолчанию для обозначения строк файла данных, которые будут выделены в тестовый набор, используется латинское "P". Метка экзаменационного набора-Используйте это текстовое поле для ввода буквенно-цифрового текста или числа, который (-ое) будет использоваться модулем при поиске в качестве ключевого слова для выделения экзаменационного набора примеров при использовании метода метки строки. Все примеры с этой меткой попадут в экзаменационный набор. Вы можете захотеть создать экзаменационный набор, чтобы проверять результаты работы сети на данных, которые сеть никогда не "видела" раньше. Ключевой текст может включать пробелы. По умолчанию для обозначения строк файла данных, которые будут выделены в экзаменационный набор, используется латинское "V". Столбец для поиска- Выдается список столбцов в файле данных. При использовании метода метки строки щелчком мыши выберите столбец, содержащий ключевые метки для тренировочного, тестового и экзаменационного наборов. 3. Проектирование - Этот модуль обеспечивает значительную гибкость при проектировании сети. Процесс проектирования состоит из выбора архитектуры сети и задания параметров тренировки сети. После того, как это сделано, создается файл конфигураций (.FIG). - Архитектура и параметры Воспользуйтесь этим модулем, чтобы выбрать один из пяти различных типов моделей обучения:
Рис.5. Экранная форма Архитектуры и параметры сети
1. Нейронные сети с обратным распространением ошибки Сети с обратным распространением ошибки известны своей способностью хорошо обобщать в широком диапазоне разнообразных задач. Вот почему они используются в громадном большинстве работающих нейросетевых приложений. Сети с обратным распространением ошибки обучаются «с учителем», т.е. при тренировке используются и входы, и выходы. В зависимости от количества примеров, тренировка таких сетей может быть более медленной, чем для других моделей. При использовании сетей с обратным распространением есть возможность увеличить точность работы сети, создавая отдельную сеть для каждого выхода, если выходы не являются категориями. NeuroShell 2 предлагает несколько различных вариантов сетей с обратным распространением: а. Каждый слой соединен только с непосредственно предшествующим ему слоем (сети с 3, 4 либо 5 слоями). Использование более чем 3 слоев редко бывает необходимо, если используете Калибровку. Использовать более 5 слоев не следует, так как не известно никаких преимуществ подобной архитектуры. б. Каждый слой соединен с каждым предшествующим слоем (сети с 3, 4 либо 5 слоями). в. Рекуррентные сети с ослабленной обратной связью от входного, скрытого либо выходного слоя. Эти сети отлично работают для данных, представляющих собой временные последовательности. г. Сети Ворда с несколькими скрытыми блоками. Когда различные скрытые блоки используют различные передаточные функции, такие сети оказываются очень мощными, благодаря тому, что скрытые блоки выделяют различные признаки во входных данных. Это дает возможность выходному слою рассматривать данные "с разных точек зрения".
2. Сеть Кохонена (обучение без учителя) Сеть Самоорганизующейся карты Кохонена - это сеть, обучающаяся без учителя, т.е. сеть, которая может учиться без предъявления правильных ответов на выходе. Такие сети способны разделять данные на указанное число категорий.
3. Вероятностная нейронная сеть (ВНС) Вероятностные нейронные сети (ВНС) известны своей способностью к быстрому обучению на "рыхлых" наборах данных (обучение происходит "с учителем"). ВНС разбивает множество данных на указанное количество выходных категорий, т.е. классифицирует входные образы.
4. Нейронная сеть с общей регрессией (НСОР) Как и сети ВНС, нейронные сети с общей регрессией (НСОР) известны своей способностью к быстрому обучению на "рыхлых" наборах данных. Сеть НСОР обучается "с учителем". Однако вместо того, чтобы разбивать множество данных на категории, как ВНС, приложения на основе НСОР способны предсказывать выходы с непрерывной амплитудой. В процессе нашего тестирования мы обнаружили, что НСОР на многих типах задач (но не на всех) ведут себя намного лучше, чем сети с обратным распространением ошибки. Они особенно полезны для аппроксимации непрерывных функций. НСОР могут иметь многомерный вход и строить многомерные поверхности, аппроксимирующие данные. Поскольку сети НСОР работают с каждым выходом независимо от всех остальных, сети НСОР в ситуации с несколькими выходами могут работать точнее, чем сети с обратным распространением.
5. Сеть МГУА (Метод группового учета аргументов или Полиномиальные сети) МГУА работает путем построения последовательных слоев со сложными связями (или соединениями), представляющими собой отдельные члены полинома. Эти полиномиальные члены создаются с использованием линейной и нелинейной регрессии. Исходный слой является просто входным слоем. Первый слой создается путем построения полиномов от входных переменных с последующим выбором наилучших полиномов. При построении второго слоя аргументами для полиномов наряду с входными переменными являются значения, полученные в первом слое. Снова алгоритмом отбираются лишь наилучшие. Их называют призерами. Этот процесс продолжается, пока сеть не перестанет улучшаться (согласно указанному заранее критерию отбора). Полученная в результате сеть может быть представлена как сложное полиномиальное (т.е. в виде знакомой формулы) описание модели. Вы можете видеть формулу, которая использует наиболее существенные входные переменные. В некоторых аспектах все это очень напоминает использование регрессионного анализа, однако это метод гораздо более мощный, чем регрессионный анализ. МГУА может строить очень сложные модели, избегая проблем переучивания. - Параметры тренировки и критерии остановки
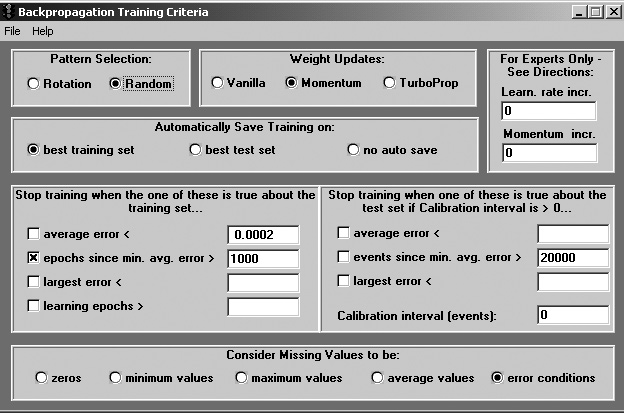
Рис. 6. Экранная форма Параметров тренировки и критерии остановки
Выбор параметров, определяющих, как сеть будет тренироваться и когда тренировка должна быть остановлена. Выбор примеров (Pattern Selection) Поочередный (Rotational) - Этот метод обеспечивает выбор тренировочных примеров в том порядке, в котором они появляются в.PAT-файле или в.TRN-файле, если используется Калибровка. Используйте его, если схожие тренировочные примеры равномерно распределены по тренировочному набору. Случайный (Random) - Этот метод обеспечивает случайный выбор тренировочных примеров, хотя он не гарантирует, что каждый пример будет выбран одинаковое количество раз. Используйте его, если тренировочный набор содержит примеры, чередующиеся циклически (например, данные об объеме продаж, подверженные сезонным изменениям), а Вы хотите, чтобы сеть давала ответы, не зависящие от этих изменений и от группировки примеров в файле. Рекуррентные сети должны тренироваться с поочередным выбором, поскольку для них порядок предъявления примеров важен.
Подстройка весов (Weight Updates) Простая(Vanilla)- Алгоритм обратного распространения ошибки в NeuroShell 2 - это не простой традиционный алгоритм, описанный в книгах, но алгоритм, модифицированный компанией для достижения максимальной скорости и точности. В данном случае "простая" означает, что при подстройке весов используется скорость обучения, но не используется момент. С моментом (Momentum) - Подстройка весов учитывает не только изменение, определяемое скоростью обучения, но включает также долю предыдущего изменения весов. Как и для момента в физике, большая величина момента заставит сеть продолжать двигаться, в общем, в направлении, в котором она двигалась до этого. Другими словами, при большой величине момента флуктуации весов будут сглаживаться. Используйте большой момент для очень шумных данных, или если Вы хотите установить высокую скорость обучения. TurboProp - Это метод тренировки, который работает в режиме "пакетной" подстройки весов, что гораздо быстрее, чем в других наших методах обратного распространения ошибки, и который имеет то дополнительное преимущество, что он нечувствителен к скорости обучения и моменту. Тренировка продолжается в течение целой эпохи, прежде чем веса будут подстроены. Все изменения весов складываются, и веса подстраиваются в конце эпохи. Метод TurboProp использует подстройку весов на разные независимые величины для разных весов, а не обычный метод с единой скоростью обучения и моментом для всех весов. Более того, величины шагов адаптивно подстраиваются в процессе обучения. TurboProp проще использовать, чем другие методы, так как пользователю нет необходимости устанавливать скорость обучения и момент. Изменение скорости обученеи и момента (Learn rate inc, Momentum inc) Существует возможность динамически увеличивать скорость обучения и/или момент в процессе тренировки на задаваемую величину приращения. Ненулевые приращения, которые должны быть очень малы, добавляются в конце каждой эпохи. Изменения одинаково влияют на все связи в сети. Некоторые эксперты считают, что для многих типов задач скорость обучения и момент следует медленно увеличивать или уменьшать в процессе тренировки. Если Вы указали приращение для скорости обучения или для момента, их использование не будет прекращено автоматически. Вам необходимо будет вернуться в этот модуль и установить приращение в 0. Если Вы остановите обучение, измененные значения скорости обучения и момента не сохраняются автоматически. Вам необходимо будет вернуться в модуль Проектирование и изменить скорость обучения и момент.
Сохранение сетей (Automatically Save Training) Для задания момента автоматической записи сети щелкните по одной из следующих кнопок переключателя: На тренировочном наборе (best training set) - сеть сохраняется каждый раз при достижении нового минимального значения средней ошибки на тренировочном наборе. Данный метод можно использовать, если НЕ используете Калибровку. (При использовании этого метода вычисление средней ошибки производится по окончании каждой эпохи.) На тестовом наборе (best test set) - сеть сохраняется каждый раз при достижении нового минимального значения средней ошибки на тестовом наборе. Если используете Калибровку, выберите этот метод. (Вычисления для тестового набора производятся по окончании указанного количества событий.) Не нужно (no auto save) - сеть не сохраняется. Вы можете захотеть использовать этот режим для ускорения тренировки в начале, когда сеть все время находит новые значения минимальной ошибки, но необходимо сохранить сеть, прежде чем закрыть модуль. Когда новые значения минимальной ошибки будут попадаться уже не так часто, Вы можете захотеть включить автоматическую запись сети, выбирая На тренировочном наборе или На тестовом наборе. Вы можете изменять метод автоматической записи сети в процессе тренировки.
Чтобы автоматически остановить тренировку, установите соответствующие флажки и укажите числа, соответствующие выбранным критериям остановки на тестовом и/или на тренировочном наборе. Если выбрано более одного критерия, тренировка будет прекращена, как только будет выполнен любой из них: Критерии на тренировочном наборе (Training Set)- Вычисляются в конце каждой эпохи Средняя ошибка меньше указанного уровня. Количество эпох после достижения минимальной средней ошибки превышает указанное. Наибольшая ошибка меньше указанного уровня. Количество эпох обучения превысило указанное значение. Критерии на тестовом наборе (Test Set) - Вычисляются в конце интервала Калибровки Средняя ошибка меньше указанного уровня. Количество событий после достижения минимальной средней ошибки превышает указанное. Наибольшая ошибка меньше указанного уровня.
Пропущенные значения (Consider Missing Value) NeuroShell 2 предоставляет несколько способов обработки пропущенных данных. Щелкните по соответствующей кнопке переключателя, чтобы заменять пропущенные данные нулем, минимальным или максимальным значением переменной, или средним между минимальным и максимальным значениями. Выберите то, что считаете наиболее вероятным значением для переменной. Если ожидаете появления пропущенных данных, мы рекомендуем использовать среднее между минимальным и максимальным значениями, которое, вероятно, является наилучшей оценкой величины. Нейронная сеть будет работать лучше, если сделаете разумную догадку относительно пропущенной величины, а не оставите место пустым. Если не ожидаете появления пропущенных данных, выберите "ошибки" (установка по умолчанию), чтобы система предупреждала Вас о возникновении пропущенных данных.
4. Обучение - Это модуль, в котором сеть учит примеры данных из тренировочного набора. Тренировка продолжается, пока не будут выполнены условия, установленные в модуле Параметры тренировки и критерии остановки. Модуль обучения вызывает различные подпрограммы обучения в зависимости от выбранной модели и архитектуры. В процессе тренировки существует возможность видеть графики и статистические показатели тренировки сети. При увеличении числа отображаемых графиков или статистических показателей тренировка замедляется.
Применение сети 1. Показатели важности - Этот модуль вычисляет для каждой входной переменной число, называемое показателем важности, которое является грубой мерой важности этой переменной для предсказания выхода сети по отношению к другим входным переменным той же сети. Чем больше число, тем больше вклад данной переменной в предсказание или классификацию. Сравнивать показатели важности для различных сетей нельзя. Этот модуль работает только для сетей с обратным распространением ошибки. Однако версии сетей ВНС и НСОР с генетическим поиском вычисляют для каждого входа индивидуальный параметр сглаживания, который можно рассматривать как показатель чувствительности для каждого входа. Чем выше значение параметра сглаживания, тем большее влияние оказывает соответствующий вход на предсказание выхода. За подробностями обратитесь к разделам Обучение ВНС и Обучение НСОР. Сети МГУА также показывают, какие входы имеют большее значение для предсказания выхода. За подробностями обратитесь к разделу Обучение сетей МГУА.
2. Применение к файлу - Этот модуль пропускает файл данных через натренированную сеть, создавая новый файл, содержащий предсказания или классификации, сделанные сетью. Воспользуйтесь этим модулем для обработки файла данных натренированной нейронной сетью, чтобы получить классификацию или предсказания сети для каждого примера в файле. Будет получен выходной файл (.OUT-файл).
3. Приписывание выходного файла - Этот модуль объединяет новый файл, содержащий ответы сети, с исходным файлом данных. Вы также можете использовать этот модуль для объединения любых двух файлов во внутреннем формате (файлов электронных таблиц). Воспользуйтесь этим модулем, чтобы приписать два существующих файла один к другому сбоку или снизу. Приписывание файла сбоку Этот модуль обычно используют, когда хотят сравнить результаты классификации или предсказания сети с данными, использованными для тренировки сети. Этот модуль объединяет файлы, «приклеивая» результаты классификации или предсказания сети к файлу данных справа. Приписывание файлов снизу Используйте этот модуль, чтобы объединить два файла в один, например, когда хотите добавить дополнительные данные в существующий файл. Оба файла должны содержать одни и те же переменные в одних и тех же столбцах.
Постобработка 1. Графики зависимостей - Этот модуль позволяет многими разнообразными способами строить графики зависимостей для одной или нескольких переменных сети. Подавая данные на вход сети, можете захотеть построить корреляционную диаграмму для двух переменных, чтобы убедиться, что примеры тренировочного набора являются представительными для всей области определения задачи. После обработки данных сетью можете построить график для сравнения предсказаний сети с реальными ответами. 1. График зависимостей по всем примерам. Позволяет построить зависимость одной или нескольких переменных по всем примерам в файле, даже если переменные имеют различные типы. Этот тип графиков полезен для анализа временных зависимостей. Так же есть возможность строить зависимости по выбранному количеству примеров. 2. График зависимостей внутри примера. Используйте этот тип графика, если все переменные в примере - одного типа, например, 100 точек в физиологическом сигнале, таком, как электрокардиограмма. На графике увидите, как выглядит эта кардиограмма. 3. Корреляционная точечная диаграмма. Позволяет построить зависимость одной переменной от другой для всех примеров, что демонстрирует корреляцию между ними. На этом графике отображается также линейный коэффициент корреляции между этими двумя переменными. 4. График High Low Close. Построение графика в переменных максимальная цена (high) - минимальная цена (low) - цена закрытия (close), используемых для рыночных предсказаний.
2. Дополнения - Этот модуль включает в себя три отдельно оплачиваемых дополнения, которые содержат средства предобработки данных фондового рынка и данных по срочным контрактам (фьючерсных), предобработки данных по результатам скачек, а также предобработки данных социологических опросов для прогнозирования результатов выборов. Пакет Рыночных индикаторов. Этот модуль позволяет построить сложный набор индикаторов, пользуясь необработанными данными фондового рынка или рынка ценных бумаг, такими, как high (наивысшая цена), low (наинизшая цена), close (цена закрытия) и volume (объем торгов). Пакет предсказания результатов скачек. Этот модуль позволяет осуществить предобработку данных о скачках, преобразуя их в форму, в которой сети легче их выучить. Пакет прогнозирования результатов выборов. Этот модуль позволяет осуществить предобработку данных социологических опросов, преобразуя их в форму, в которой сети легче их выучить.
3. Правила - Этот модуль позволяет создавать правила типа "если/то/иначе" для предобработки данных. Используйте модуль Правила, чтобы применить правила для преобразования или предобработки данных перед тем, как они будут обрабатываться нейронной сетью. Например, Вы можете использовать две входные переменные для расчета значений третьей входной переменной. Допустим, Вы считаете, что, если сложить цену на золото и цену акций IBM и сумма будет больше 400, то экономическая ситуация улучшается. Вы можете преобразовать эту информацию в новый вход нейросети следующим образом:
Рис. 7. Экранная форма модуль Правила Вы можете также использовать модуль Правила для постобработки предсказаний и классификаций, сделанных сетью. Например, если выходы являются категориями и лежат в диапазоне от нуля до единицы, и Вы хотите, чтобы все значения в столбце 1, превышающие 0,5, преобразовывались в «истина» или в 1, то правило может иметь следующий вид: Если столбец 1 >= 0,5, то столбец 1 = 1, иначе столбец 1 = 0. Таким образом Вы можете установить Ваше собственное пороговое значение, в данном случае 0,5, для определения того, включать ли данный пример в выходную категорию. Существуют и множество других применений для правил, применяемых к выходным данным.
4. Декодирование символов - Модуль Декодирование символов может быть применен к выходному файлу сети (.OUT) для преобразования числовых данных в символы. Например, если была построена система предсказания продаж, в которой ответами сети являются 1 и 0, Вы можете захотеть преобразовать 1 в строку "Продажа вероятна", а 0 - в строку "Продажа маловероятна".
Для декодирования символов проделайте следующее: 1. Щелчком мыши поместите курсор в столбец Найти значение:.Введите числовое значение, которое Вы хотите декодировать. Нажмите Еnter для завершения редактирования. 2. Щелчком мыши поместите курсор в столбец Декодировать в текст:.Введите текст, на который должно быть заменено числовое значение, и нажмите Enter. 3. Еще раз щелкните мышью, чтобы поместить курсор в столбец Преобразовать в следующих переменных: Выберите столбцы, где необходимо осуществить декодирование, щелкая по соответствующим переменным в поле Список переменных/столбцов. Указанный текст будет заменять указанное числовое значение в выбранных столбцах. 4. Повторите описанную процедуру для каждого числового значения в данном файле, которое желаете декодировать.. Модуль Декодирования символов позволяет Вам декодировать до 10 столбцов в одном файле данных. Вывод задачи 1. Экспорт файлов - Этот модуль позволяет экспортировать файлы из внутреннего формата файлов NeuroShell 2. Этот внутренний формат совпадает с форматами электронных таблиц Lotus 1-2-3.WK1 и Excel 4.XLS, поэтому можете просматривать файл на любом этапе его обработки с помощью программы электронных таблиц. Поддерживается экспорт файлов следующих форматов: - Экспорт текстовых файлов - Экспорт двоичных файлов - Экспорт файлов электронных таблиц 2. Просмотр данных - Этот модуль (известный также как Таблица) позволяет просматривать файлы после их обработки сетью. По умолчанию в Таблицу передается.OUT-файл. Таблица - это напоминающее программу электронных таблиц средство ввода и просмотра данных, позволяющее вырезать, вставлять и перемещать данные, однако это не есть полностью функциональная прогр
|