
Интервальные оценки параметров распределения.
Интервальной называют оценку, которая определяется двумя числами—концами интервала. Интервальные оценки позволяют установить точность и надежность оценок. Пусть найденная по данным выборки статистическая характеристика Q* служит оценкой неизвестного параметра Q. Будем считать Q постоянным числом (Q может быть и случайной величиной). Ясно, что Q* тем точнее определяет параметр Q, чем меньше абсолютная величина разности |Q- Q*|. Другими словами, если d>0 и |Q- Q*| <d, то чем меньше d, тем оценка точнее. Таким образом, положительное число d характеризует точность оценки. Однако статистические методы не позволяют категорически утверждать, что оценка Q* удовлетворяет неравенству |Q- Q*| <d; можно лишь говорить о вероятности g, с которой это неравенство осуществляется. Надежностью (доверительной вероятностью) оценки называют вероятность g, с которой осуществляется неравенство |Q—Q* | <d. Обычно надежность оценки задается наперед, причем в качестве g берут число, близкое к единице. Наиболее часто задают надежность, равную 0,95; 0,99 и 0,999. Пусть вероятность того, что, |Q- Q*| <d равна g: P(|Q- Q*| <d)= g. Заменив неравенство равносильным ему двойным неравенством получим: Р [Q* —d< Q < Q* +d] = g Это соотношение следует понимать так: вероятность того, что интервал Q* - d< Q < Q* +d заключает в себе (покрывает) неизвестный параметр Q, равна g. Интервал (Q* - d Q* +d) называется доверительным интервалом, который покрывает неизвестный параметр с надежностью g
27. Оценки вероятности события. Вероятность события количественно характеризует возможность (шанс) осуществления этого события в ходе случайного эксперимента. В данном параграфе мы начинаем изучать возможности, предоставляемые теорией вероятности для сравнительного анализа ситуаций, возникающих при различных комбинациях равновероятных событий. Представим, что у нас проводится эксперимент с пространством из n элементарных исходов, которые равновероятны. Элементарные исходы являются несовместными событиями (напомним, что несовместные события - это те, которые не могут произойти одновременно), поэтому вероятность каждого из них равна 1/n. Допустим, нас интересует событие А, которое наступает только при реализации благоприятных элементарных исходов, количество последних m (m< n). Тогда, согласно классическому определению, вероятность такого события: Р(А)=m/n. Для любого события А справедливо неравенство: 0 < P(A) <1. Частость как точечная оценка вероятности события Обозначим через р неизвестную вероятность появления случайного события А в единичном испытании. Приближенное значение
где m - число появления события А в n испытаниях. Серия независимых испытаний, в каждом из которых событие А происходит с вероятностью q=1-p, является последовательностью испытаний Бернулли. Теорема. Пусть m - число наступлений события А в n независимых испытаниях, р - вероятность наступления события А в каждом из испытаний. Тогда
28.Статистическая проверка гипотез, система приёмов в математической статистике, предназначенных для проверки соответствия опытных данных некоторой статистической гипотезе. Процедуры С. п. г. позволяют принимать или отвергать статистические гипотезы, возникающие при обработке или интерпретации результатов измерений во многих практически важных разделах науки и производства, связанных с экспериментом. Правило, по которому принимается или отклоняется данная гипотеза, называется статистическим критерием. Построение критерия определяется выбором подходящей функции Т от результатов наблюдений, которая служит мерой расхождения между опытными и гипотетическими значениями. Эта функция, являющаяся случайной величиной, называется статистикой критерия, при этом предполагается, что распределение вероятностей Т может быть вычислено при допущении, что проверяемая гипотеза верна. По распределению статистики Т находится значение Т0, такое, что если гипотеза верна, то вероятность неравенства T > T0 равна a, где a — заранее заданный значимости уровень. Если в конкретном случае обнаружится, что Т > T0, то гипотеза отвергается, тогда как появление значения Т £ T0 не противоречит гипотезе. Пусть, например, требуется проверить гипотезу о том, что независимые результаты наблюдений x1,..., xn подчиняются нормальному распределению со средним значением а = a0 и известной дисперсией s 2. При этом предположении среднее арифметическое и подчинена Стьюдента распределению с n — 1 степенями свободы (подобную задачу см. в ст. Математическая статистика, табл. 1a). Такого рода критерии называются критериями согласия и используются как для проверки гипотез о параметрах распределения, так и гипотез о самих распределениях (см. Непараметрические методы). При решении вопроса о принятии или отклонении какой-либо гипотезы H0 с помощью любого критерия, основанного на результатах наблюдения, могут быть допущены ошибки двух типов. Ошибка "первого рода" совершается тогда, когда отвергается верная гипотеза H0. Ошибка "второго рода" совершается в том случае, когда гипотеза H0 принимается, а на самом деле верна не она, а какая-либо альтернативная гипотеза Н. Естественно требовать, чтобы критерий для проверки данной гипотезы приводил возможно реже к ошибочным решениям. Обычная процедура построения наилучшего критерия для простой гипотезы заключается в выборе среди всех критериев с заданным уровнем значимости и (вероятность ошибки первого рода) такого, который приводил бы к наименьшей вероятности ошибки второго рода (или, что то же самое, к наибольшей вероятности отклонения гипотезы, когда она неверна). Последняя вероятность (дополняющая до единицы вероятность ошибки второго рода) называется мощностью критерия. В случае, когда альтернативная гипотеза Н простая, наилучшим будет критерий, который имеет наибольшую мощность среди всех других критериев с заданным уровнем значимости а (наиболее мощный критерий). Если альтернативная гипотеза Н сложная, например зависит от параметра, то мощность критерия будет функцией, определенной на классе простых альтернатив, составляющих Н, т. е. будет функциейпараметра. Критерий, имеющий наибольшую мощность при каждой альтернативной гипотезе из класса Н, называется равномерно наиболее мощным, однако следует отметить, что такой критерий существует лишь в немногих специальных ситуациях. В задаче проверки гипотезы о среднем значении нормальной совокупности а = а0 против альтернативной гипотезы а > a0 равномерно наиболее мощный критерийсуществует, тогда как при проверке той жегипотезы против альтернативы а ¹ a0 его нет. Поэтому часто ограничиваются поиском равномерно наиболее мощных критериев в тех или иных специальных классах (Инвариантных, несмещенных критериев и т.п.). Теория С. п. г. позволяет с единой точки зрения трактовать выдвигаемые практикой различные задачи математической статистики (оценка различия между средними значениями, проверка гипотезы постоянства дисперсии, проверка гипотезы независимости, проверка гипотез о распределениях и т.п. Идеи последовательного анализа, примененные к С. п. г., указывают на возможность связать решение о принятии или отклонении гипотезы с результатами последовательнопроводимых наблюдений (в этом случае число наблюдений, на основе которых по определённому правилу принимается решение, не фиксируется заранее, а определяется в ходе эксперимента)
23, 24. Дискретной (прерывной) называют случайную величину, которая принимает отдельные, изолированные возможные значения с определенными вероятностями. Число возможных значений дискретной случайной величины может быть конечным или бесконечным. Дадим более точное определение: Дискретной случайной величиной (ДСВ) называют такую величину, множество значений которой либо конечное, либо бесконечное, но счетное. Случайная величина
Все методы математико-статистического анализа условно делятся на первичные и вторичные. Первичными называют методы, с помощью которых можно получить показатели, непосредственно отражающие результаты производимых в эксперименте измерений. Соответственно под первичными статистическими показателями имеются в виду те, которые применяются в самих психодиагностических методиках и являются итогом начальной статистической обработки результатов психодиагностики. Вторичными называются методы статистической обработки, с помощью которых на базе первичных данных выявляют скрытые в них статистические закономерности. К первичным методам статистической обработки относят, например, определение выборочной средней величины, выборочной дисперсии, выборочной моды и выборочной медианы. В число вторичных методов обычно включают корреляционный анализ, регрессионный анализ, методы сравнения первичных статистик у двух или нескольких выборок. Рассмотрим методы вычисления элементарных математических статистик. Мода Числовой характеристикой выборки, как правило, не требующей вычислений, является так называемая мода. Модой называют количественное значение исследуемого признака, наиболее часто встречающееся в выборке. Для симметричных распределений признаков, в том числе для нормального распределения, значение моды совпадает со значениями среднего и медианы. Для других типов распределении, несимметричных, это не характерно. К примеру, в последовательности значений признаков 1, 2, 5, 2, 4, 2, 6, 7, 2 модой является значение 2, так как оно встречается чаще других значений - четыре раза. Моду находят согласно следующим правилам: 1) В том случае, когда все значения в выборке встречаются одинаково часто, принято считать, что этот выборочный ряд не имеет моды. Например: 5, 5, 6, 6, 7, 7 - в этой выборке моды нет. 2) Когда два соседних (смежных) значения имеют одинаковую частоту и их частота больше частот любых других значений, мода вычисляется как среднее арифметическое этих двух значений. Например, в выборке 1, 2, 2, 2, 5, 5, 5, 6 частоты рядом расположенных значений 2 и 5 совпадают и равняются 3. Эта частота больше, чем частота других значений 1 и 6 (у которых она равна 1). Следовательно, модой этого ряда будет величина =3,5 3) Если два несмежных (не соседних) значения в выборке имеют равные частоты, которые больше частот любого другого значения, то выделяют две моды. Например, в ряду 10, 11, 11, 11, 12, 13, 14, 14, 14, 17 модами являются значения 11 и 14. В таком случае говорят, что выборка является бимодальной. Могут существовать и так называемые мультимодальные распределения, имеющие более двух вершин (мод). 4) Если мода оценивается по множеству сгруппированных данных, то для нахождения моды необходимо определить группу с наибольшей частотой признака. Эта группа называется модальной группой.
|
 вероятности р определяется в виде
вероятности р определяется в виде ,
,
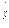 - частость появления события А в n испытаниях;
- частость появления события А в n испытаниях; - состоятельная, несмещенная и эффективная оценка вероятности р.
- состоятельная, несмещенная и эффективная оценка вероятности р. результатов наблюдений распределено нормально со средним а = a0 и дисперсией s 2/n, а величина
результатов наблюдений распределено нормально со средним а = a0 и дисперсией s 2/n, а величина 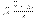 распределена нормально с параметрами (0, 1). Полагая
распределена нормально с параметрами (0, 1). Полагая  можно найти связь между T0 и a по таблицам нормального распределения. Например, при гипотезе а = a0 событие Т > 1, 96 имеет вероятность а = 0,05. Правило, рекомендующее считать, что гипотеза а = a0 неверна, если Т > 1,96, будет приводить к ложному отбрасыванию этой гипотезы в среднем в 5 случаях из 100, в которых она верна. Если же Т £ 1,96, то это ещё не означает, что гипотеза подтверждается, т.к. указанное неравенство с большой вероятностью может выполняться при а, близких к a0. Следовательно, при использовании предложенного критерия можно лишь утверждать, что результаты наблюдений не противоречат гипотезе а = a0. При выборе статистики Т всегда явно или неявно учитывают гипотезы, конкурирующие с гипотезой а = a0. Например, если заранее известно, что а ³ a0, т. е. отклонение гипотезы а = a0 влечёт принятие гипотезы а > a0, то вместо Т следует взять
можно найти связь между T0 и a по таблицам нормального распределения. Например, при гипотезе а = a0 событие Т > 1, 96 имеет вероятность а = 0,05. Правило, рекомендующее считать, что гипотеза а = a0 неверна, если Т > 1,96, будет приводить к ложному отбрасыванию этой гипотезы в среднем в 5 случаях из 100, в которых она верна. Если же Т £ 1,96, то это ещё не означает, что гипотеза подтверждается, т.к. указанное неравенство с большой вероятностью может выполняться при а, близких к a0. Следовательно, при использовании предложенного критерия можно лишь утверждать, что результаты наблюдений не противоречат гипотезе а = a0. При выборе статистики Т всегда явно или неявно учитывают гипотезы, конкурирующие с гипотезой а = a0. Например, если заранее известно, что а ³ a0, т. е. отклонение гипотезы а = a0 влечёт принятие гипотезы а > a0, то вместо Т следует взять  . Если дисперсия s2 неизвестна, то вместо данного критерия для проверки гипотезы а = a0 можно воспользоваться т. н. критерием Стьюдента, основанным на статистике
. Если дисперсия s2 неизвестна, то вместо данного критерия для проверки гипотезы а = a0 можно воспользоваться т. н. критерием Стьюдента, основанным на статистике  которая включает несмещенную оценку дисперсии
которая включает несмещенную оценку дисперсии
 называется непрерывной, если для нее существует неотрицательная кусочно-непрерывная функция*
называется непрерывной, если для нее существует неотрицательная кусочно-непрерывная функция*  , удовлетворяющая для любых значений x равенству
, удовлетворяющая для любых значений x равенству



