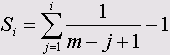Ранговые преобразования
В SPSS существует возможность задавать ранги для измеренных значений переменной, проводить оценки Сэвиджа, вычислять процентные ранги и формировать процентильные группы, добавляя в файл данных соответствующие переменные. Так, например, в формулах для непараметрических тестов (см. главу 14) вместо исходных измеренных значений переменной используются присвоенные им ранги. Однако эти процедуры производят автоматическое присвоение рангов и в явном виде выполнять предварительные ранговые преобразования не требуется. Поэтому они играют второстепенную роль. Мы продемонстрируем присвоение рангов на более наглядном примере, а затем проведем обзор различных типов рангов.
Пример рангового преобразования В главе 20 представлен файл europa.sav, содержащий отдельные статистические показатели по 28 европейским странам. В частности, он включает переменные land (краткое обозначение страны) и tjul (средняя дневная температура в июле). Требуется расположить страны в нисходящем порядке согласно значениям последней переменной и затем вывести их в отсортированном виде. · Загрузите файл europa.sav. · Выберите в меню команды Transform (Преобразовать) Rank Cases... (Присвоить ранги наблюдениям) Откроется диалоговое окно Rank Cases.
Рис. 8.10:Диалоговое окно Rank Cases · Щелкните в списке переменных на переменной tju1. В поле By: (По) можно задать группирующую переменную. В этом случае назначение рангов будет выполнено раздельно по группам, образуемым этой переменной. · Присвоим самой теплой стране (с максимальным значением переменной tju1) ранг 1; для этого щелкните в поле Assign Rank I to (Присвоить ранг 1) на опции Largest value (Максимальное значение). Щелкнув на кнопке Rank types... (Типы рангов), можно увидеть стандартную настройку Rank. Пока оставим ее без изменений; остальные настройки мы рассмотрим в разделе 8.6.2. · Кнопка Ties... (Связки) открывает диалоговое окно Rank Cases: Ties. Его настройки указывают, как программа будет поступать при появлении одинаковых измеренных величин. По умолчанию принято (и, как правило, это наилучший вариант), что присваивается среднее (Mean) из значений рангов этих величин. При установке Low все значения получают наименьший, при установке High — наибольший из этих рангов. При выбранной опции Sequential ranks to unique values (Присваивать последовательные ранги) все связанные наблюдения получают одинаковый ранг; следующему наблдению присваивается следующее по порядку целое число. Поэтому максимальный присвоенный ранг равен не общему количеству значений, а количеству различных значений. Перечисленные четыре способа присвоения рангов можно пояснить с помощью простого примера, в котором семь значений расположены по убыванию.
Рис. 8.11: Диалоговое окно Rank Cases: Ties
· Оставьте стандартную настройку и закройте диалоговое окно кнопкой Continue. · Начните присвоение рангов, щелкнув на ОК. В файл данных будет добавлена переменная rtju1, содержащая ранги, присвоенные значениям переменной tju1. Для обозначения ранговой переменной к имени исходной переменной спереди дописывается буква г. Затем отсортируем файл данных по этой ранговой переменной. · Для этого, как описано в разделе 7.3, выберите в меню команды Data (Данные) Son Cases... (Сортировать наблюдения) и в появившемся диалоговом окне выберите в качестве переменной сортировки rtjul. Примите предлагаемый по умолчанию порядок сортировки по возрастанию. · Запустите сортировку кнопкой ОК. Теперь выведем значения переменных rtju1, land и tju1 в отсортированном виде. · Для этого выберите в меню команды (см. раздел 4.8) Analyze (Анализ) Reports (Отчеты) Case summaries... (Итоги по наблюдениям) и перенесите в поле Variables переменные rtjul, land и tjul в указанной последовательности. · Запустите создание отчета кнопкой ОК. В окне просмотра будет показана следующая таблица. Отсюда можно заключить, что Греция является самой теплой страной (ранг 1), за ней следует Италия (ранг 2), следующий ранг имеют две страны — Албания и Румыния (средний ранг 3,5) и т.д. Case Processing Summary a (Сводка случаев)
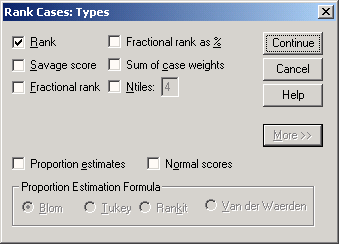
2 Типы рангов В диалоге Rank Cases можно, щелкнув на кнопке Rank Types... (Типы рангов), от-крыть диалоговое окно Rank Cases: Types (Ранги: Типы). В этом окне представлены шесть типов рангов; щелкнув на кнопке More» (Еще), можно увидеть еще два. Ниже приведено объяснение различных типы рангов. · Rank (Ранг): Абсолютные значения рангов (см. раздел 8.6.1). Это установка по умолчанию. · Savage score (Оценка Сэвиджа): Это значения ранга, полученное на основе экспоненциального распределения. При общем количестве значений переменной т оценка Сэвиджа для i-го ранга определяется по формуле
Рис. 8.12: Диалоговое окно Rank Cases: Types · Fractional Rank (Относительный ранг): Это значение ранга деленное на количество наблюдений. · Fractional Rank as % (Относительный ранг в %): Это численные значения относительных рангов, умноженные на 100. Например, процентный ранг 33,93 означает, что 33,93% всех наблюдений имеют более низкий ранг. · Sum of case weights (Сумма весов наблюдений): Эта величина представляет интерес только при определении рангов для подгрупп и является постоянной в каждой подгруппе; она соответствует количеству случаев в подгруппе. · Ntiles (N-процентили): Пользователь может задать число групп процентилей, на которые должны быть разбиты наблюдения (по умолчанию 4). Тогда каждому случаю присваивается значение процентильной группы, к которой он принадлежит. · Proportion estimates (Долевые оценки): Вычисление накопленной доли при предположении нормальном распределении переменной. Для ранга г и количества наблюдений я соответствующие долевые оценки вычисляются по четырем нижеследующим формулам.
· Normal scores (Нормальные ранги): Значения процентилей, относящиеся к долевым оценкам. Для перечисленных рангов SPSS автоматически задает имена переменных, которые приведены в нижеследующей таблице. При этом имеет значение, был ли выбран единственный тип ранга или одновременно вычислялись ранги нескольких типов (что является исключением). В последнем случае, для обеспечения однозначности переменных имена должны различаться. В таблице приводятся также принятые в SPSS метки этих переменных. Для долевых оценок и нормальных рангов здесь приведен вариант, когда применяется формула Блома (Blom); при выборе других формул расчета этих рангов метки соответственно изменяются. Имя исходной переменной — lem (в нашем примере — это средняя ожидаемая продолжительность жизни мужчин).
Если провести ранговые преобразования всех возможных типов и вывести получившиеся значения с помощью средства формирования сводки наблюдений, мы получим следующую таблицу. Case Processinq Summary3 (Сводка наблюдений)
a. Limited to first 100 cases (Ограничено первыми 100 наблюдениями) Кодирование и кодировочная таблица Для того чтобы полученные данные можно было обработать, прежде всего следует создать кодировочную таблицу. Кодировочная таблица устанавливает соответствие между отдельными вопросам анкеты и переменными. используемыми при компьютерной обработке данных. Например, пункту анкеты "Пол" может быть поставлена в соответствие переменная sex. Переменные — это ячейки памяти, в которые можно записывать значения, введенные с клавиатуры. Мы выбрали для переменной имя sex, так как имена переменных в SPSS для Windows могут содержать до восьми символов. Другое, более подробное имя было бы слишком длинным. Имена переменных могут состоять из букв латинского алфавита, цифр и специальных символов; причем первым символом имени должна быть буква. Переменные могут принимать различные значения. Переменная sex может иметь два возможных значения: "женский" и "мужской". Кодировочная таблица определяет кодовые числа, соответствующие отдельным значениям переменных; например, значению "женский" может соответствовать цифра "1", а значению "мужской" — "2". Подитожим задачи, которые решаются при составлении кодировочной таблицы: · Кодировочная таблица устанавливает соответствие между отдельным вопросам анкеты и переменными. · " Кодировочная таблица устанавливает соответствие между возможным значениями переменных и кодовыми числами. Для нашей анкеты мы можем составить следующую кодировочную таблицу. Она приводится в самой анкете.
|