Идентификация диктора на HTML5
Лабораторная работа
Красноярск, 2013 Задание: · Разработать алгоритм, позволяющий идентифицировать диктора при помощи WebAudioApi. · Разработать графический интерфейс при помощи HTML5.
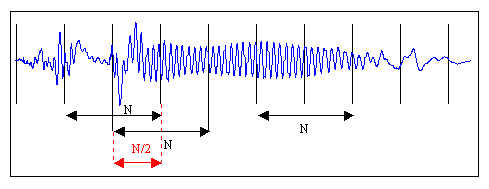
Решение: Для реализации алгоритма был изучен алгоритм текстозависимой идентификации человека по голосу. Первым шагом к реализации алгоритма является запись человеческого голоса(фразы) для дальнейших манипуляций. Для получения эталонных данных (усредненного вектора признаков) Необходима обработка речевого сигнала, включающая в себя: 1. Разбиение звукозаписи на кадры. Необходимость в этом объясняется тем, что установив фиксированный размер подзадачи и усреднив результаты вычислений по всем задачам, получим наперед заданное количество признаков для классификации. Рис.1 – кадрирование звукового сигнала На рисунке изображена «порезка» звукового сигнала на кадры длины N с половинным перекрытием. Необходимость в перекрытии вызвана искажением звука в случае, если бы кадры были расположены рядом. Для программы были выбраны кадры длительность 128 мс. 2. Для устранения нежелаетльных эффектов при дальнейшей обработке кадров, каждый элемент кадра умножается на особую весовую функцию («окно»). Результатом станет выделение центральной части кадра и плавное затухание амплитуд на его краях. Это необходимо для достижения лучших результатов при прогонке преобразования Фурье, поскольку оно ориентировано на бесконечно повторяющийся сигнал. Соответственно, кадр должен стыковаться сам с собой и как можно более плавно. Окон существует великое множество. Я буду использовать окно Хэмминга.
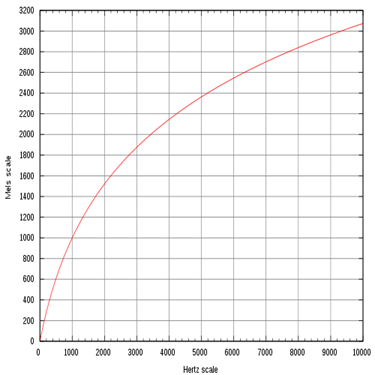
n — порядковый номер элемента в кадре, для которого вычисляется новое значение амплитуды N — как и ранее, длина кадра (количество значений сигнала, измеренных за период) 3. Следующим шагом будет получение кратковременной спектрограммы каждого кадра в отдельности. Для этих целей используем дискретное преобразование Фурье. 4. Переход к мел-шкале. На сегодняшний день наиболее успешными являются системи распознавания голоса, использующие знания об устройстве слухового аппарата. Ухо интерпретирует звуки не линейно, а в логарифмическом масштабе. Рис.2 Мел-шкала Как видно, мел-шкала ведет себя линейно до 1000 Гц, а после проявляет логарифмическую природу. Переход к новой шкале описывается несложной зависимостью. 5. Получение вектора признаков. Вектор признаков будет состоять из тех самых мел-кепстральных коэффициентов. Вычисляются по формуле (4). 6. Последней стадией является классификация говорящего. Классификация производится вычислением меры схожести пробных данных и уже известных. Мера схожести выражается расстоянием от вектора признаков пробного сигнала до вектора признаков уже классифицированного. Нас будет интересовать наиболее простое решение — расстояние городских кварталов.
Затруднения в реализации: Изначальным решением для реализации алгоритма было использование функции getByteFrequencyData(), принадлежащую модулю анализатора контекста webkitAudioContext. Однако использование данной функции не могло быть хорошим решением, так как анализ аудио потока производится в реальном времени, при воспроизведении. При этом количество кадров, над которыми производилось ДПФ было не фиксированным даже для одного аудиофайла. Ни о каком получении усредненного вектора признака речи идти и не могло. Вторым решением было использование буфера аудиоконтекста в качестве источника данных для кадрирования, ДПФ и дальнейшего анализа. Однако такое решение так же было обречено на неудачу, так как средствами javascript не удалось инициализировать двумерный массив достаточного размера для хранения кадров. Требуемый массив в зависимости от длинны речевого сигнала должен был иметь размерность порядка 20-100 на 5644(а именно столько отсчетов содержит в себе кадр длительностью 128 мс и частотой дискретизации 44100Гц) элементов. Следующий синтаксис не дал требуемого результата: var array=[]; for(var i=0;i<buf.length;i+=5644) array[i]=new Array(5644);
Исходный код программы: Первый вариант: <!DOCTYPE html> <html> <head> </head> <body> <script type="text/javascript"> window.addEventListener('load', init, false); var ctx; //audio context var buf; //audio buffer var fft; //fft audio node var samples = 256; var setup = false; //indicate if audio is set up yet var array; var k=0; //init the sound system //инициализация аудиоконтекста и массива уср. признаков function init() { array=new Float32Array(samples); for(var i=0; i<samples; i++) { array[i]=0; } console.log("in init"); try { ctx = new webkitAudioContext(); //is there a better API for this? setupCanvas(); loadFile(); } catch(e) { alert('you need webaudio support' + e); }
} window.addEventListener('load',init,false);
//load the mp3 file function loadFile() { var req = new XMLHttpRequest(); req.open("GET","5.mp3",true); //we can't use jquery because we need the arraybuffer type req.responseType = "arraybuffer"; req.onload = function() { //decode the loaded data ctx.decodeAudioData(req.response, function(buffer) { buf = buffer; alert(buffer.length) play(); }); }; req.send(); } //начало воспроизведения function play() { //create a source node from the buffer var src = ctx.createBufferSource(); src.buffer = buf; alert(buf[2]); //create fft fft = ctx.createAnalyser(); fft.fftSize = samples;
//connect them up into a chain src.connect(fft); fft.connect(ctx.destination);
//play immediately src.noteOn(0); setup = true; webkitRequestAnimationFrame(update); } //получение массива байтов с ДПФ и попытка получения их среднеарифметического function update() {
webkitRequestAnimationFrame(update); if(!setup) return;
var data = new Uint8Array(samples); fft.getByteFrequencyData(data);
for(var i=0; i<data.length; i++) {
array[i]=array[i]+data[i]/256;
}
} </script> </body> </html>
Второй вариант: <!DOCTYPE html> <html> <head>
</head> <body> <script type="text/javascript"> window.addEventListener('load', init, false); var ctx; //audio context var buf=[]; //audio buffer var fft; //fft audio node var samples = 256; var setup = false; //indicate if audio is set up yet var array=[]; var k=0; //init the sound system function init() {
console.log("in init"); try { ctx = new webkitAudioContext(); //is there a better API for this? loadFile(); } catch(e) { alert('you need webaudio support' + e); }
} window.addEventListener('load',init,false);
//load the mp3 file function loadFile() { var req = new XMLHttpRequest(); req.open("GET","5.mp3",true); //we can't use jquery because we need the arraybuffer type req.responseType = "arraybuffer"; req.onload = function() { //decode the loaded data ctx.decodeAudioData(req.response, function(buffer) { buf = buffer;
segmentation(); }); }; req.send(); } //попытка занести кадры в двумерный массив, параллельно попытка его инициализации. function segmentation(){ k=0; for(var i=0;i<buf.length;i+=5644){ array[i]=new Array(5644); for(var j=i;j<i+5644;j++) {array[k][j-i]=buf[j]; k++;} }
}
</script> </body> </html>
Функции для дальнейшего преобразования и анализа кадров: var freq; var freqmel; var cn; var k,n; var result; function mel(var freqtemp) { for(var i=0;i<freqtemp.lenght; i++) { for(var j=0;j<freqtemp[i].lenght;j++) { freqmel[i][j]=1127*Math.log(1+freqtemp[i][j]/700) } }
} function vectorget(var freqtemp) { var temp; k=freqtemp.lenght; n=10;
for(var i=0;i<freqtemp.lenght; i++) { cn[i]=0;
for(var j=0;j<freqtemp[i].lenght;j++) { temp=Math.log(freqtemp[i][j])*(n*(j-0.5)*3.14/k); } cn[i]+=temp; }
function comparation(var sample, var standart) { result=0; if(sample.lenght<standart.lenght) for(var j=0;j<sample.lenght;j++) { result+=Math.abs(sample[j]-standart[j]) } else for(var j=0;j<standart.lenght;j++) { result+=Math.abs(sample[j]-standart[j]) } } function analysis(var freqtemp) { mel(freqtemp); vectorget(freqmel); comparation(cn,st);
} }
Готовое приложение для записи звукового сигнала и преобразования в.wav <!DOCTYPE html>
<html> <head> <meta http-equiv="Content-Type" content="text/html; charset=utf-8"> <style type='text/css'> ul { list-style: none; } #recordingslist audio { display: block; margin-bottom: 10px; } </style> </head> <body>
<button onclick="startRecording(this);">record</button> <button onclick="stopRecording(this);" disabled>stop</button>
<h2>Recordings</h2> <ul id="recordingslist"></ul>
<h2>Log</h2> <pre id="log"></pre>
<script> function __log(e, data) { log.innerHTML += "\n" + e + " " + (data || ''); }
var audio_context; var recorder;
function startUserMedia(stream) { var input = audio_context.createMediaStreamSource(stream); __log('Media stream created.');
input.connect(audio_context.destination); __log('Input connected to audio context destination.');
recorder = new Recorder(input); __log('Recorder initialised.'); }
function startRecording(button) { recorder && recorder.record(); button.disabled = true; button.nextElementSibling.disabled = false; __log('Recording...'); }
function stopRecording(button) { recorder && recorder.stop(); button.disabled = true; button.previousElementSibling.disabled = false; __log('Stopped recording.');
// create WAV download link using audio data blob createDownloadLink();
recorder.clear(); }
function createDownloadLink() { recorder && recorder.exportWAV(function(blob) { var url = URL.createObjectURL(blob); var li = document.createElement('li'); var au = document.createElement('audio'); var hf = document.createElement('a');
au.controls = true; au.src = url; hf.href = url; hf.download = new Date().toISOString() + '.wav'; hf.innerHTML = hf.download; li.appendChild(au); li.appendChild(hf); recordingslist.appendChild(li); }); }
window.onload = function init() { try { // webkit shim window.AudioContext = window.AudioContext || window.webkitAudioContext; navigator.getUserMedia = navigator.getUserMedia || navigator.webkitGetUserMedia; window.URL = window.URL || window.webkitURL;
audio_context = new AudioContext; __log('Audio context set up.'); __log('navigator.getUserMedia ' + (navigator.getUserMedia? 'available.': 'not present!')); } catch (e) { alert('No web audio support in this browser!'); }
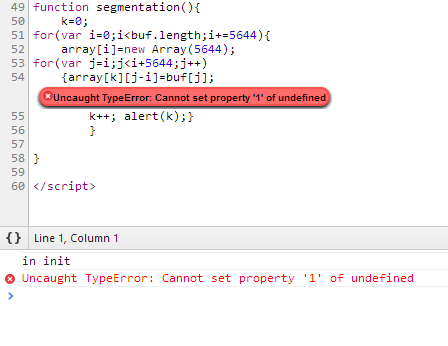
navigator.getUserMedia({audio: true}, startUserMedia, function(e) { __log('No live audio input: ' + e); }); }; </script> <script src="recorder.js"></script> </body> </html> Сведения об ошибке при обращении к неинициализированному массиву:
Вывод: в ходе проведения лабораторной работы был изучен алгоритм идентификации диктора по голосу. Так же было выяснено, что HTML5 и javascript не являются хорошими языками программирования для работы с многомерными массивами и точного спектрального анализа речевого сигнала.
|
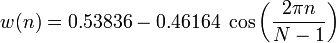 (1)
(1)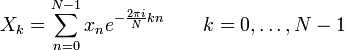 (2)
(2)
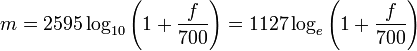 (3)
(3)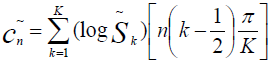 (4)
(4)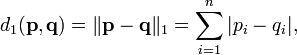 (5)
(5)