ПРОБЛЕМЫ, СВЯЗАННЫЕ С ИСПОЛЬЗОВАНИЕМ СВОДНЫХ ДАННЫХ
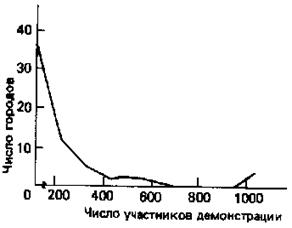
Из предшествующего изложения видно, что специфические проблемы, встающие при анализе сводных данных, меняются в зависимости от типов и источников этих данных. Существуют, однако, некоторые общие проблемы, с которыми всегда приходится сталкиваться при использовании сводных данных. Мы рассмотрим две такие проблемы, не ставя перед собой цели предложить готовые их решения, но желая предупредить исследователя о необходимости не упускать их из поля зрения. Обсудим сначала так называемую проблему экологической ошибки, которую необходимо учитывать при составлении плана исследования и при спецификации и операционализации переменных, равно как и собственно при принятии решения об использовании сводных данных применительно к конкретному исследовательскому вопросу. Исследователь рискует совершить одну из нескольких экологических ошибок всякий раз, как он пытается, основываясь на данных, собранных на одном уровне анализа, обобщить результаты на другой уровень анализа. Например, если мы, собирая данные о расовой принадлежности получателей государственного социального пособия в разных штатах США, обнаружим наличие сильной прямой зависимости между получением регулярной помощи от государства и принадлежностью к небелому населению, у нас может возникнуть искушение распространить этот результат на более высокий, т.е. общенациональный, уровень и объявить, что эта зависимость верна для данного государства в целом, либо, наоборот, обобщить “вниз”, допустив, что зависимость, обнаруживаемая в каждом отдельном штате, будет также верна и для каждого из его округов. Если же сведением данных мы занимаемся на общенациональном или окружном уровне, то, возможно – а по сути дела, почти наверняка, – мы обнаружим, что на [c.302] этих уровнях наблюдается зависимость, сильно отличная от той, которая была получена на основе данных, сведенных на уровне штата. Эмпирическое изучение “экологической” проблемы показало, что зависимости на разных уровнях могут быть не просто слабее или сильнее, но они могут быть даже разнонаправленными 5. Когда исследователь экстраполирует результаты одного уровня анализа на другой, он рискует неверно проинтерпретировать свои данные и прийти к ошибочным выводам. Значит ли это, что мы должны использовать только те данные, которые были сведены на уровне единиц анализа, изначально выбранных нами для изучения, и что мы в своем исследовании совсем не можем обобщать “вверх” или “вниз”? Нет, это не так. Существуют методы анализа данных, которые при определенных условиях помогают по меньшей мере свести к минимуму тот риск, с которым бывают связаны межуровневые обобщения 6. Когда исследователь видит, что он волей обстоятельств вынужден использовать данные, сведенные не на том уровне анализа, с которым он имеет дело, а на другом, то, прежде чем собирать данные, он должен предусмотреть применение одного или нескольких таких методов и проследить, чтобы имеющиеся у него данные отвечали их требованиям. Наверное, еще важнее проявлять бдительность – памятуя о риске “экологических” заключений – при планировании исследования и операционализации понятий. Здесь надо по возможности избегать применения показателей, требующих обобщения результатов разных уровней анализа. Пусть, например, задачей нашего исследования является определение зависимости между членством в профсоюзе и поддержкой демократической партии (в США), и в нашем распоряжении оказываются сводные данные по избирательным округам, где указано, какой процент избирателей каждого округа голосовал на последних выборах за демократов и какой процент трудящихся каждого округа состоит в профсоюзе. Мы сможем использовать эти данные только в том случае, если единицей нашего анализа являются избирательные округа, а целью анализа – суждения типа: “Чем больше в округе членов профсоюзов, тем больше вероятность, что на выборах в нем победит кандидат от демократов”. Однако если единицей анализа у нас выступают отдельные избиратели [c.303] (индивиды), то мы будем стремиться к получению суждений типа: “Члены профсоюзов, как правило, голосуют за кандидатов от демократов”. При этом мы не можем сколь-нибудь уверенно использовать сводные данные по избирательным округам, и будет разумнее, если мы попытаемся поискать данные, относящиеся к членству в профсоюзе и поведению на выборах отдельных индивидов. Вторая (близкая первой) группа проблем, часто встречающихся при анализе сводных данных, связана с трудностями построения на основе сводных данных валидных показателей. Редко когда случается обнаружить сводные цифры, которые можно было бы использовать в качестве непосредственной меры какого-либо интересного для политолога понятия. Чаще всего мыимеем дело с числами, представляющими такие переменные, которые можно рассматривать как часть какого-то более крупного явления, с которым связаны наши базовые понятия. При изучении политических последствий научно-технического прогресса, например, исследователю, возможно, не удастся найти сводных данных, непосредственно отражающих уровень научно-технического прогресса в различных странах. Но он, наверное, сможет получить информацию о том, какая часть населения каждой страны грамотна, или живет в населенных пунктах численностью свыше 25 тыс. человек, или занята в несельскохозяйственных отраслях экономики; все эти параметры могут рассматриваться как составляющие научно-технического прогресса. Подобные цифры часто называют необработанными (“сырыми”) данными; они интересуют исследователя не сами по себе, а как основа для создания важных в рамках конкретного исследования понятий. Перед исследователем стоит задача найти поддающиеся теоретическому и методологическому обоснованию пути превращения необработанных данных в пригодные для использования меры. Существует два основных подхода к этому – через формирование индексов и через преобразование данных. Построение индекса заключается в сведении сложных данных в единый показатель, который отражает значение понятия полнее, чем любой из его компонентов. Широко используются три типа индексов – аддитивные, мультипликативные и взвешенные. Аддитивный индекс употребим [c.304] в тех случаях, когда доступные исследователю данные отражают различные меры одной и той же базовой переменной. Например, для получения показателя понятия “размеры экспорта сельскохозяйственной продукции” мы могли бы просто сложить все отчетные цифры, отражающие количество экспортированной пшеницы, кукурузы и соевых бобов (в бушелях); для выяснения размеров “религиозного сообщества” в некоторой стране можно было бы просуммировать все числовые данные, отражающие количество приверженцев различных религий, исповедуемых в этой стране. Часто, однако, сводные данные отражают меры различных сторон некоторого явления, что не допускает возможности суммирования. Следуя законам математической логики, мы не можем, например, складывать число людей, участвовавших в беспорядках, с числом часов, в течение которых длились эти беспорядки, в надежде тем самым построить индекс степени серьезности беспорядков. Число участников и продолжительность являются неаддитивными элементами явления под названием “беспорядки”. Можно, однако, утверждать, что эти два элемента взаимодействуют друг с другом, и тогда для получения показателя степени серьезности беспорядков мы могли бы число участников умножить на число часов, вычислив таким образом число “человеко-часов”, пришедшихся на беспорядки. Полученный таким путем показатель называется мультипликативным индексом. Подобные индексы бывают нужны в тех случаях, когда мы измеряем различные аспекты некоторого понятия 7. При определенных обстоятельствах необработанные данные – для того чтобы стать обоснованным показателем понятий – нуждаются во взвешивании с помощью некоторого эталона. Например, использование числа участников антиправительственной манифестации в качестве показателя величины кредита доверия к правительству правомерно только тогда, когда это число выражено в форме процентного отношения к численности всего населения. Чтобы получить взвешенный индекс, мы должны одну переменную (число участников антиправительственных манифестаций) взвесить с помощью другой (численности населения). Точно так же, исходяиз предположения, что десять демонстраций в год указывают на [c.305] большую политическую нестабильность, чем те же десять демонстраций, но растянутые на десять лет, мы могли бы число антиправительственных демонстраций взвесить с помощью эталонной переменной “время”, получив индекс количества демонстраций в год. Этот конкретный тип взвешивания называется стандартизацией. Взвешивание – технически простая операция, но с концептуальной стороны зачастую бывает трудно определить, нуждается ли конкретная мера во взвешивании и что следует выбрать в качестве эталона веса. Неясно, к примеру, что выступает в роли спускового крючка гонки вооружений: абсолютные уровни вооружений вовлеченных в гонку государств или определенное соотношение этих уровней? Следует ли в качестве эталона веса использовать уровень вооружений государства-противника? Ответы на подобные вопросы обычно можно получить посредством эмпирического выяснения того, как именно применение взвешенных и невзвешенных показателей влияет на результаты статистического анализа. Случается, что при использовании сводных данных исследователь сталкивается с такими мерами, которые невозможно сделать пригодными для целей конкретного исследования путем простого сочетания с другими мерами и их необходимо видоизменить в индивидуальном порядке. Иногда даже индексы после их видоизменения становятся более пригодными. Такие видоизменения обычно называются преобразованиями данных. Данные преобразуются главным образом для того, чтобы они отвечали требованиям определенных статистических процедур, которые исследователь намеревается применять в процессе анализа. Самым общим основанием для преобразования данных является необходимость избежать такого искажения результатов статистического анализа, которое бывает обусловлено определенными свойствами распределения необработанных данных. Существует много методов преобразования данных, и каждый из них рассчитан на исправление вполне определенных изъянов, имеющихся у необработанных данных 8. Однако логарифмическое преобразование может, пожалуй, служить хорошим общим примером того, как работают эти методы. Некоторые из наиболее часто используемых статистических процедур могут быть законно применены [c.306] только к данным с нормальным распределением (о нормальном распределении см. гл.15). Применение этих процедур к данным, не характеризующимся нормальным распределением, может привести к серьезной недооценке силы зависимостей, существующих между переменными, и к другим неверным выводам. Но необработанные сводные данные чаще всего не отличаются нормальным распределением. Логарифмические преобразования рассчитаны как раз на то, чтобы как можно более приблизить данные к нормальному распределению. Основная процедура состоит в том, что к “оценке” каждого случая в рамках множества необработанных данных прибавляется некоторая константа, после чего исходная оценка заменяется на подходящий логарифм с использованием логарифмической таблицы. Итог такого преобразования виден на рис.10.1, где показаны результаты преобразования гипотетических данных о числе людей, принявших участие в демонстрациях в защиту прав гомосексуалистов в 57 городах США. Распределение преобразованных данных (см. рис. рис.10.1б) не образует нормальной, или колоколообразной, кривой, но оно гораздо ближе к ней, чем распределение необработанных данных (см. рис. рис.10.1а).
Рис. 10.1. Влияние логарифмическою преобразования на гипотетические данные о демонстрациях в защиту прав гомосексуалистов, имевших место в 57 городах США. Сказанное выше не следует интерпретировать в том смысле, что иметь дело сразу с несколькими мерами нежелательно. Наоборот, иметь множественные показатели (multiple indicators) понятий весьма желательно; при этом зачастую полезно как объединять разные меры в индексы, так [c.307] и изучать их на каком-то этапе анализа данных отдельно друг от друга. Это мотивируется тем, что использование множественных показателей позволяет контролировать степень обоснованности нашей операционализации понятий. Пусть, например, мы хотим измерить понятие “дискриминация по признаку пола в сфере занятости” применительно к разным американским штатам. Допустим, нам удалось раздобыть данные по следующим переменным: (1) соотношение средней заработной платы мужчин и женщин; Мы можем использовать все три показателя, приписав каждому штату оценку (ранг) в рамках каждой переменной, а затем сравнив полученные результаты. Если те штаты, в которых выявляется наибольшая степень дискриминации по одному показателю, заняли высокий ранг и по другим показателям, то у нас есть все основания полагать, что каждый из этих показателей является валидной мерой базового понятия “дискриминация по признаку пола в сфере занятости”. С другой стороны, если мы обнаружим, что штаты, занявшие высокий ранг по двум каким-то показателям, по третьему из показателей имеют низкий ранг, то нам придется воздержаться от дальнейшего использования этого последнего девиантного показателя в качестве меры нашего базового понятия. Чем больше независимых показателей удается выделить для каждого понятия, тем лучше, потому что большее количество показателей позволяет осуществить более основательную проверку валидности каждого из них. Так, в отношении предыдущего примера, где были выделены всего три меры, мы не можем быть совершенно уверены в том, что “девиантная” мера не является на самом деле валидной, а две другие, наоборот, лишенными валидности. Возможно, именно в силу своей валидности эта мера отклоняется от других показателей в том, как они ранжируют штаты. Если бы, однако, у нас было пять или десять мер, которые бы вполне непротиворечиво ранжировали штаты, наряду с одной стоящей в стороне от них мерой, то мы бы могли быть совершенно уверены в том, что валидности [c.308] лишена именно эта девиантная мера, а не остальные. Существует целый ряд методов, использующих множественные меры для проверки и усиления валидности показателей 9. Существует еще один очень важный вопрос, о котором необходимо помнить при использовании сводных данных. Он связан с тем фактом, что сводные данные доступны подчас только в форме, не позволяющей делать состоятельных сравнений между единицами. Так, например, если нас интересует, какое внимание уделяется в различных американских штатах вопросам народного образования, то нам следовало бы поискать данные о величине ежегодных расходов каждого штата на народное образование. Было бы, однако, некорректно сравнивать общую сумму денег, расходуемых Техасом, с общей суммой, расходуемой Род-Айлендом, ввиду того что эти штаты несопоставимы по размерам и благосостоянию. Род-Айленд может расходовать только малую долю того, что расходует Техас, и при этом демонстрировать большую степень заботы о народном образовании, благодаря тому что здесь на школы будет тратиться намного больше в расчете на каждого ребенка школьного возраста или относительно объема всего бюджета штата. Чтобы сравнить бюджеты штатов, нужно перевести данные об их расходах на образование в такую форму, которая бы учитывала имеющиеся между ними различия в численности населения и в величине бюджета. Если мы этого не сделаем, то у нас не будет валидного показателя базового понятия и наши выводы будут отражать не столько относительную величину заботы каждого штата о народном образовании, сколько его относительные размеры и благосостояние. Подобные ситуации вынуждают нас каким-то образом стандартизовать наши меры. Мера является стандартизованной, когда она сформулирована так, чтобы в ней учитывались возможные расхождения между отдельными случаями в рамках переменных, отличных от той, которую она отображает. Очень часто бывает необходимо стандартизовать сводные данные перед тем, как приступать к сравнению единиц анализа. Это может повлечь за собой необходимость сбора данных по переменным, не имеющим прямого отношения к данному исследованию. Так, возвращаясь к предыдущему примеру, нам могут [c.309] понадобиться данные по численности населения и общей величине расходов штатов, чтобы с их помощью можно было стандартизовать расходы штатов на образование, выразив их в количестве долларов, приходящихся на обучение каждого ребенка школьного возраста, или в форме процентного отношения ко всему бюджету штата. Точно так же, если бы мы захотели измерить понятие “милитаризация”, опираясь на цифры военных расходов различных государств, то, прежде чем делать какие бы то ни было сравнения, нам нужно было бы стандартизовать эту меру, выразив ее в форме процентного отношения к валовому национальному продукту (общая стоимость всех товаров и услуг, произведенных в данной стране за определенный период). Не сделай мы этого, и богатое государство будет выглядеть большим милитаристом, чем бедное, даже если оно расходует на военные цели относительно общей суммы своих доходов в десять раз меньше, чем бедное государство. Итак, всякий раз, как вы собираетесь сравнивать какие-нибудь группы (страны, города, организации и т.п.), вам надо помнить о необходимости стандартизовать ваши меры и запланировать сбор дополнительных данных, которые могут понадобиться для стандартизации. Стандартизация обычно заключается в приведении меры к выражению вида “такое-то количество единиц в расчете на единицу какой-то другой переменной” или к форме процентного отношения к какой-то другой переменной. Это зачастую предполагает вычисление некоторого коэффициента, или уровня, как-то: уровень преступности (количество преступлений на тысячу человек населения), уровень грамотности (количество грамотных на тысячу человек населения), уровень детской смертности (количество детских смертей на тысячу рождений) и т.п. Дополнительная работа по сбору данных по тем переменным, с помощью которых должна быть стандартизована ключевая переменная, совершенно необходима, если стремиться к обоснованности сравнений между теоретически сильно различающимися случаями. Итак, при анализе сводных данных исследователь должен не только проявлять осторожность в использовании необработанных данных в качестве показателей понятий, но и помнить о пользе множественных мер, а также о [c.310] возможности усовершенствования показателей посредством их сочетания, преобразования или стандартизации. [c.311]
|