
АВТОМАТИЗИРОВАННОЕ ФОРМИРОВАНИЕ ЗНАНИЙ
Приобретение знаний при создании БД ИИС основано на методах инженерии знаний и в общем случае не обходится без участия экспертов – специалистов в предметной области. Однако их занятость в процессе формирования БД и обучении ИИС определяется степенью автоматизации указанного процесса. Автоматизация формирования знаний имеет свои законы, аппаратные и программные средства. Рассмотрим так называемое индуктивное машинное обучение, обеспечивающее получение новых знаний на основе уже накопленной информации. Индуктивное обучение имеет прямую аналогию с мышлением человека. Программам, использующим индуктивное обучение, демонстрируют ряд примеров. Программа должна проанализировать набор свойств этих примеров и идентифицировать подходящие концепты – принципы, объединяющие примеры. Свойства примеров известны и представлены (например, экспертами) парами " атрибут-значение". Таким образом, индуктивное обучение представляет собой эвристический поиск в пространстве символических описаний по правилам вывода. Очевидно, что выводы являются формой логического мышления. Одна из форм индуктивного обучения предусматривает демонстрацию примеров двух типов – тех, которые соответствуют концепту «позитивные экземпляры», и тех, которые ему не соответствуют («негативные экземпляры»). Задача программы обучения – обеспечить выявление или конструкцию подходящего концепта, который включал бы все позитивные экземпляры и не включал ни одного негативного. Такой вид обучения называется обучением концептам. Рассмотрим набор исходных данных, представленный табл. 6.1 (последний столбец предстоит заполнить). Предположим, программа обучается концепту «Немецкий автомобиль». Тогда позитивными экземплярами для этого концепта будут BMW 316 и VW Cabriolet (см. последний столбец), а остальные – негативными. Если же целевой концепт – “Американский автомобиль старой марки”, то позитивными экземплярами будут Thunderbird Raodster и Chevrolet Bel Air, а остальные – негативными. Обучающая выборка примеров Таблица 6.1
Необходимо предъявить программе и позитивные, и негативные экземпляры. В противном случае выводы, которые она сделает, будут далеки от требуемых. Так, в первой из рассмотренных задач и BMW 316 и VW Cabriolet являются малыми машинами, поэтому если программе не предъявить в качестве негативного экземпляра Chevrolet Bel Air, то она может сделать вывод (коль скоро мы предполагаем у нее умственные способности), что концепт “Немецкий автомобиль” совпадает с концептом “Малый автомобиль”. Аналогично, если во второй задаче не будет представлен негативный экземпляр Oldmobile Cutlass, то программа может посчитать концепт “Американский автомобиль старой марки” совпадающим с более общим концептом “Американский автомобиль”. Таким образом, с формальной точки зрения для любого множества данных обучающей выборки, в котором выделены и положительные, и отрицательные экземпляры, нужно специфицировать некоторый необходимый набор атрибутов, имеющий отношение к обучаемым концептам, и запись каждого экземпляра должна содержать все значения этих атрибутов. Другая форма индуктивного обучения – обобщение дескрипторов – предполагает набор экземпляров некоторого класса объектов, представляющий некоторый концепт. Программа должна сформировать описание, которое позволит идентифицировать (распознать) любые объекты этого класса. Пусть, например, обучающая выборка имеет вид {Cadillac Seville, Oldsmobile Cutlass, Lincoln Continental}. При этом каждый экземпляр выборки имеет атрибуты «размер, уровень комфорта и расход топлива». Тогда в результате выполнения задачи обобщения дескрипторов программа сформирует описание, представляющее набор значений дескрипторов, характерный для данного класса объектов: {большой, комфортабельный, прожорливый}. Отличие между двумя методиками состоит в следующем: - метод обучения концептам предполагает включение в обучающую выборку как позитивных, так и негативных экземпляров некоторого заранее заданного набора концептов, а в процессе выполнения задачи будет сформировано правило, позволяющее программе распознавать ранее неизвестные экземпляры концепта; - задача обобщения дескрипторов предполагает включение в обучающую выборку только экземпляров определенного класса, а в процессе обучения (выполнение задачи) создается наиболее компактный вариант описания из всех, которые подходят к каждому из предъявляемых экземпляров. Обе методики относятся к так называемому супервизорному обучению, поскольку в распоряжении программы имеются специально подготовленная обучающая выборка и пространство атрибутов. Альтернативным методом представления информации является использование дерева решения. Это один из способов разбиения множества данных на классы или категории. Корень дерева неявно содержит все классифицируемые данные, а листья – определенные классы после выполнения классификации. Промежуточные узлы дерева представляют пункты принятия решения о выборе или выполнения тестирующих процедур с атрибутами элементов данных, которые служат для дальнейшего разделения данных в этом узле. Промежуточные узлы дерева можно рассматривать как атрибуты классифицируемых объектов, а дуги – возможные альтернативные значения этих атрибутов. Пример дерева представлен на рис. 6.1.
Здесь даны атрибуты «наблюдение, влажность, ветрено». Листья деревьев промаркированы классами П (например, позитивный концепт – выйти на прогулку), Н (например, негативный концепт – остаться дома). Дерево можно прямо транслировать в общее правило: Если наблюдение = облачно Ú наблюдение = солнечно & влажность = нормально Ú наблюдение = дождливо & ветрено = нет, то П.
Данное правило можно разбить на три частных, не требующих логических дизъюнкций. Дерево решения имеет несомненные визуальные достоинства, отличающие его от эквивалентной выборки пар атрибут значения – табл. 6.2.. Обучающая выборка дерева решения Таблица 6.2
Следует обратить внимание на то, что после составления дерева решения становятся не только очевиднее, принимаются быстрее, но и сокращается объем параметров (за счет становящихся ненужными значений температуры). Один из алгоритмов (поскольку рассматривается автоматизированное обучение при минимальном участии экспертов) формирования дерева решения по обучающей выборке использует последовательность тестовых процедур
Если рекурсивно заменять каждый узел
|

 к каждому объекту
к каждому объекту 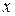 , с помощью которых множество
, с помощью которых множество 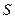 элементов выборки разделяется на подмножества {
элементов выборки разделяется на подмножества {  ,
,  , …,
, …,  }, содержащие объекты только одного класса такие, что для
}, содержащие объекты только одного класса такие, что для  значение
значение 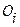 (рис.6.2).
(рис.6.2).



