
АВТОМАТИЧЕСКОЕ ИНДЕКСИРОВАНИЕ
Автоматическое индексирование документов может основываться на простых односложных, или многословных составных терминах (фразах). Простые термины далеко не идеальны для индексирования, поскольку смысл слов вне контекста нередко бывает неоднозначным. Термины-фразы обладают большей дискриминирующей способностью. Термин-фраза может состоять из основы фразы и остальных компонентов. Основой фразы признается термин с частотой вхождения в документы, превышающей определенный порог. Остальные компоненты термина-фразы имеют среднюю или низкую частоту вхождения. При этом учитывается их связь с основой фразы, например размещение их в одном предложении или на некотором заданном расстоянии друг от друга. Для генерации групп взаимосвязанных слов по замеченным закономерностям совместного их вхождения в документы применяются методы группирования или кластеризации терминов. Если представить матрицу терминов в виде двухмерного массива, вышеупомянутый метод сравнивает друг с другом столбцы матрицы и делает заключение о том, входит та или иная группа терминов в несколько документов совокупности. Если такое неоднократное вхождение имеет место, то термины считаются связанными и группируются в один класс. Основу методов автоматического индексирования составляет присваивание весовых коэффициентов терминам на основе статистических характеристик. Предположим, что в исследуемой совокупности имеется Пусть Частоту термина и последнюю величину можно объединить в рамках единой модели индексирования по частоте, означающей вес термина
Еще один статистический метод индексирования основывается на дискриминации по термину. Здесь каждый документ рассматривается как точка в пространстве документов. Чем больше сходства у множеств терминов двух документов, тем ближе расположены соответствующие точки в пространстве документов. В рамках данной схемы можно оценивать качество термина как дискриминатора документа, основываясь на том, какие изменения произойдут в пространстве документов после введения термина в индекс. Для количественной оценки такого изменения удобно использовать увеличение или уменьшение расстояния между документами. Термин является хорошим дискриминатором, если его введение увеличивает среднее расстояние между документами (снижается плотность в пространстве документов). Дискриминирующая характеристика термина
Полученные значения весов терминов могут использоваться в процессе принятия решения о включении термина в ПОД. Однако часто в ПОД заносят все термины, встречающиеся в документе, и их веса.
|
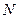 документов. Пусть
документов. Пусть 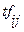 - частота вхождения термина
- частота вхождения термина  в документ
в документ 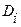 . Индексирование на основе частоты термина позволяет достичь лишь одной из целей индексирования – полноты поиска. Для повышения точности поиска используют термины, сконцентрированные в отдельных документах. Это позволяет отделить документы, где такие термины встречаются, от тех, где их нет.
. Индексирование на основе частоты термина позволяет достичь лишь одной из целей индексирования – полноты поиска. Для повышения точности поиска используют термины, сконцентрированные в отдельных документах. Это позволяет отделить документы, где такие термины встречаются, от тех, где их нет.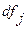 - число документов, в которых встречается термин
- число документов, в которых встречается термин  =
= 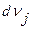 , вычисляется как разность между плотностями пространства документов до и после введения термина. Для совместного учета частоты термина и его дискриминирующей характеристики применяют следующую схему взвешивания:
, вычисляется как разность между плотностями пространства документов до и после введения термина. Для совместного учета частоты термина и его дискриминирующей характеристики применяют следующую схему взвешивания:


