
РУБРИЦИРОВАНИЕ, ОСНОВАННОЕ НА ПРИМЕРАХ
Системы автоматического рубрицирования, основанные на примерах, рассматривают в качестве понятий, которым нужно обучиться, рубрики. Машинное обучение производится на основе примеров текстов, которые были заранее отрубрицированы экспертом вручную. Выделяют статистические и нейросетевые методы рубрицирования. Статистическое рубрицирование состоит в определении степени соответствия терминологического портрета документа и терминологического портрета рубрик на основе статистических характеристик субъектов сравнения. Под терминологическим портретом документа понимают совокупность наиболее важных терминов, содержащихся в тексте документа. В качестве показателя важности термина в документе может быть использована частота его встречаемости. Под терминологическим портретом рубрики понимается набор наиболее характерных для этой рубрики терминов с их весами. Таким образом, семантика рубрики задается однозначно только ее терминологическим портретом. Формирование терминологических портретов каждой рубрики производится с помощью одной из технологий обучения рубрикатора. При этом роль эксперта сводится к формированию для каждой рубрики обучающей выборки – совокупности максимально коротких фрагментов текстов, содержащих полное и минимально избыточное лингвистическое наполнение одной обучаемой рубрики. Выделение характеристических терминов для рубрики производится автоматически, на основе их весов, которые могут быть получены в процессе анализа обучающей выборки. Например,
где Таким образом, единую модель для всех рубрик одного рубрикатора можно представить в виде двухмерной матрицы весов{
где Пороговые значения для каждой из рубрик определяются таким образом, чтобы при применении решающего правила ко всей обучающей выборке к данной рубрике было отнесено максимальное количество релевантных и минимальное количество не релевантных ей текстов. Вычисление может производиться как c помощью математических методов, так и эмпирическим путем. К достоинством метода относятся: - простота определения семантики рубрики, позволяющая автоматизировать обучение рубрик; - универсальность подхода для очень широкого класса предметных областей; - наличие аппарата количественной оценки релевантности документов рубрикам; - высокое быстродействие. Недостатком метода является относительно низкое качество рубрицирования. Нейросетевой метод рубрицирования использует нейронные сети (НС) в качестве обучаемого классификатора. Считается, что в наличии имеется подборка примеров текстов, каждый из которых помечен как релевантный или нерелевантный определенной рубрике. Задача НС, обученной на этих примерах, состоит в определении степени релевантности любого нового текста данной рубрике. Этот подход предполагает, что семантика рубрики однозначно задается примерами принадлежащих ей текстов. Достоинствами НС являются строгое математическое обоснование и большое быстродействие. К недостаткам НС относятся скрытый механизм функционирования и длительный процесс обучения.
|
 = log
= log  ,
, - количество документов в обучающей выборке, принадлежащих рубрике
- количество документов в обучающей выборке, принадлежащих рубрике  ,
,  - количество документов в обучающей выборке, принадлежащих рубрике
- количество документов в обучающей выборке, принадлежащих рубрике 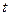 . Список характеристических терминов упорядочен по убыванию весов терминов в ней.
. Список характеристических терминов упорядочен по убыванию весов терминов в ней. >
>  ,
, - частота встречаемости термина
- частота встречаемости термина 


