
Методические указания по теме. Задача 1. На предприятии в порядке случайной бесповторной выборки было опрошено 100 рабочих из 1000 и получены следующие данные об их доходе за месяц:
Задача 1. На предприятии в порядке случайной бесповторной выборки было опрошено 100 рабочих из 1000 и получены следующие данные об их доходе за месяц:
С вероятностью 0,950 определить: 1) среднемесячный размер дохода работников данного предприятия; 2) долю рабочих предприятия, имеющих месячный доход более 700 у.е.; 3) необходимую численность выборки при определении среднемесячного дохода работников предприятия, чтобы не ошибиться более чем на 50 у.е.; 4) необходимую численность выборки при определении доли рабочих с размером месячного дохода более 700 у.е., чтобы при этом не ошибиться более чем на 5%. Решение. Выборочный метод (выборка) используется, когда применение сплошного наблюдения физически невозможно из-за огромного массива данных или экономической нецелесообразности. Учитывая, что на основе выборочного обследования нельзя точно оценить изучаемый параметр (например, среднее значение – Таблица 3. Вспомогательные расчеты для решения задачи
По формуле (18) получим средний доход в выборке: Затем необходимо определить предельную ошибку выборки по формуле (39)[1]:
где t – коэффициент доверия, зависящий от вероятности, с которой определяется предельная ошибка выборки;
где n – численность выборки; N – численность генеральной совокупности. В нашей задаче выборка бесповторная, значит, применяя формулу (41), получим среднюю ошибку выборки при определении среднего возраста в генеральной совокупности: Для определения средней ошибки выборки при определении доли рабочих с доходами более 700 у.е. в генеральной совокупности необходимо определить дисперсию этой доли. Дисперсия доли альтернативного признака w (признак, который может принимать только два взаимоисключающих значения – например, больше или меньше определенного значения) определяется по формуле (42):
В нашей задаче долю альтернативного признака (рабочие с доходами более 700 у.е.) найдем как отношение числа таких рабочих к общему числу рабочих в выборке: w = 20/100 = 0,2 или 20%. Теперь определим дисперсию этой доли по формуле (42): Значения вероятности Таблица 4. Значения интеграла вероятностей Лапласа
В нашей задаче После расчета предельной ошибки находят доверительный интервал обобщающей характеристики генеральной совокупности по формуле (43) – для средней величины и по формуле (44) – для доли альтернативного признака: ( В нашей задаче по формуле (43): 571-38,494 Аналогично определяем доверительный интервал для доли по формуле (44): 0,2-0,075 При разработке программы выборочного наблюдения очень часто задается конкретное значение предельной ошибки ( nповт = В нашей задаче выборка бесповторная, значит, воспользуемся формулой (46), в которую подставим уже рассчитанные дисперсии среднего выборочного дохода рабочих (Дв = 42859) и доли рабочих с доходами более 700 у.е. (Дв = 0,16): nб/повт = Таким образом, необходимо включить в выборку не менее 62 рабочих при определении среднего месячного дохода работников предприятия, чтобы не ошибиться более чем на 50 у.е., и не менее 197 рабочих при определении доли рабочих с размером месячного дохода более 700 у.е., чтобы при этом не ошибиться более чем на 5%.
|
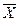 или долю какого-то признака – р) генеральной совокупности, необходимо найти пределы, в которых он находится. Для этого необходимо определить изучаемый параметр по данным выборки (выборочную среднюю –
или долю какого-то признака – р) генеральной совокупности, необходимо найти пределы, в которых он находится. Для этого необходимо определить изучаемый параметр по данным выборки (выборочную среднюю – 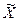 и/или выборочную долю – w) и его дисперсию (Дв). Для этого построим вспомогательную таблицу 3.
и/или выборочную долю – w) и его дисперсию (Дв). Для этого построим вспомогательную таблицу 3.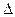 = t
= t 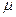 ,(39)
,(39)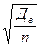 , (40)
, (40) 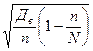 , (41)
, (41)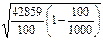 = 19,640 (у.е.).
= 19,640 (у.е.).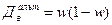 .(42)
.(42) =0,2*(1-0,2) = 0,16. Теперь можно рассчитать среднюю ошибку выборки по формуле (41):
=0,2*(1-0,2) = 0,16. Теперь можно рассчитать среднюю ошибку выборки по формуле (41): 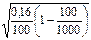 = 0,038 или 3,8%.
= 0,038 или 3,8%. и коэффициента доверия t имеются в математических таблицах нормального закона распределения вероятностей (если в выборке более 30 единиц), из которых в статистике широко применяются сочетания, приведенные в таблице 4:
и коэффициента доверия t имеются в математических таблицах нормального закона распределения вероятностей (если в выборке более 30 единиц), из которых в статистике широко применяются сочетания, приведенные в таблице 4:
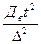 ;(45) nб/повт =
;(45) nб/повт = 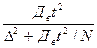 . (46)
. (46)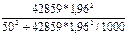 = 62 (чел.), nб/повт=
= 62 (чел.), nб/повт= 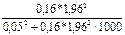 = 197 (чел.).
= 197 (чел.).


