Статистическая сводка (группировка данных)
На первом этапе обработки данных часто возникает необходимость в их группировке. Группировка позволяет представить первичные данные в компактном виде, выявить закономерности варьирования изучаемого признака. Количество классов можно приблизительно наметить, пользуясь следующими принципами: - при количестве наблюдений от 25 до 40 – 5-6 классов; - при количестве наблюдений от 40 до 60 – 6-8 классов; - при количестве наблюдений от 60 до100 – 7-10 классов; - при количестве наблюдений от 100 до 200 наблюдений – 8-12 классов; - при количестве наблюдений более 200 – 10-15 классов. Расчет описательных статистик производится при помощи модуля Basic Statistic and Tables. В этом модуле объединены наиболее часто использующиеся на начальном этапе обработки данных процедуры. После запуска системы STATISTICA, модуля Basic Statistic and Tables и статистической процедуры Descriptive statistic(Описание статистик) на экране появится одноименное диалоговое окно Descriptive Statistic (Описание статистик) (рис. 14)
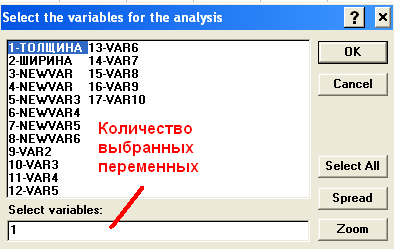
Рисунок 14. Окно Descriptive Statistic (Описание статистик) В этом окне при помощи кнопки Variables (Переменные) следует выбрать переменные для дальнейшего анализа (рис. 15).
Рисунок 15. Выбор переменных для дальнейшего анализа Одним из методов статистической сводки данных (группировки данных) является построение таблиц частот. Построение таблиц частот, как правило, предшествует этапу построения гистограмм. Для построения таблиц частот используется группа кнопок Distribution (распределение) окна Descriptive statistics. Чтобы построить таблицу частот, в окне, показанном на рисунке 13, следует нажать кнопку Frequency Tables (Таблицы частот). После этого в появившемся далее окне следует выбрать переменные, для которых необходимо построение таблиц частот. Число классов (интервалов) группировки данных устанавливается при помощи счетчика переключателя Number of intervals окна Descriptive statistics. Справа от кнопок Distribution находятся две опции Categorization (Группировка), позволяющие задать число интервалов группировки или установить величину интервала равную целому числу. Если активировать переключатель Integer intervals (categories), то классы (интервалы) группировки будут являться целыми числами. На рисунке 16 показана готовая таблица частот.
Рисунок 16. Готовая таблица частот для переменной Толщина На рисунке 16: Count – Количество случаев, попавших в данных интервал (частота); Cumul. Count – Накопленная частота [2]; Percent of Valid – Процент случаев от количества данных, подвергающихся обработке; Cumul. % of Valid – Накопленный процент случаев от количества данных, подвергающихся обработке; % of all Cases – Процент случаев от общего количества; Count% of all – Накопленный процент случаев от общего количества [3]. В графе Missing (Вне диапазона классов) указано общее количество по столбцам таблицы частот. Чтобы продолжить обработку данных, не закрывая таблицу частот, необходимо нажать кнопку Continue (Продолжить), после чего появится окно, показанное на рисунке 14. При необходимости обработки сгруппированных данных нужно воспользоваться кнопкой W (weight вес) окна Descriptive statistics (рис. 17).
Рисунок 17. Кнопка для указания веса переменной В появляющемся диалоговом окне в поле Weight variables (Вес переменных) следует указать переменную, которая будет являться весами для других переменных. При этом переключатель Status необходимо установить в положение ON (рис. 18). Необходимо иметь в виду, что веса действуют сразу для всех переменных. Поэтому обрабатывать сгруппированные и не сгруппированные данные следует отдельно.
Рисунок 18. Указание весовой переменной Таблицы частот, построенные без указания веса переменной и с указанием этого веса, отличаются друг от друга.
|