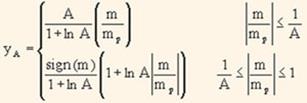Применяемые в современном оборудовании (7 кГц)
Речь представляет собой колебания сложной формы, зависящей от произносимых слов, тембра голоса, интонации, пола и возраста говорящего. Спектр речи весьма широк (примерно от 50 до 10000 Гц), но для передачи речи в аналоговой телефонии когда-то отказались от составляющих, лежащих вне полосы 0,3-3,4 кГц, что ухудшило восприятие ряда звуков, но мало затронуло разборчивость. Ограничение частоты снизу (до 300 Гц) также ухудшает восприятие из-за потерь низкочастотных гармоник основного тона. А в цифровой телефонии к влиянию ограничения спектра добавляются еще шумы дискретизации, квантования и обработки, дополнительно зашумляющие речь. Решающими в выборе полосы 0,3-3,4 кГц были экономические соображения и нехватка телефонных каналов. Для совместимости по полосе с распространенными аналоговыми сетями в цифровой телефонии отсчеты аналоговой речи приходится брать согласно теореме Котельникова с частотой 8 кГц — не меньше двух отсчетов на 1 Гц полосы. Правда, в цифровой телефонии существует принципиальная возможность использовать спектр речи за пределами полосы 0,3-3,4 кГц и тем самым повысить качество, но эти методы не реализуются, так как они вычислительно пока еще очень сложны. При полосе исходного сигнала до 6 кГц и тактовой частоте отсчетов около 16 кГц сжатый цифровой сигнал требует для передачи канал в 12 кбит/с. При этом оценка качества по критерию MOS может быть выше 4,5 балла. Озвученная речь, представляющая большую трудность для сжатия, образуется с помощью звуковых связок человека. Скорость их периодических колебаний задает так называемую частоту основного тона (ОТ) — периодическую подпитку энергией голосового тракта человека, который представляет собой объемный резонатор. Голосовой тракт формирует спектральную окраску речи, или, другими словами, ее формантную структуру. Другое название голосового тракта - синтезирующий фильтр — нам более удобно, так как математическое описание речеобразования обычно ведется в терминах линейной фильтрации. Тогда, условно, речевой сигнал можно разделить на две составляющие, отвечающие за 1- ый ОТ (возбуждение фильтра) и 2-ой голосовой тракт (формантная структура сигнала). Соответственно, большинство на сегодня используемых алгоритмов, так или иначе, решают один вопрос - как наиболее эффективно выделить и сокращенно описать обе составляющие. А отрезки глухой речи при моделировании заменяют спектрально окрашенным шумом.
3.1.1 Импульсно-кодовая модуляция (PCM — Pulse-Code Modulation)
Прямое аналого-цифровое преобразование является низкоэффективным (т. е. имеющим малую скорость кодирования при заданном качестве) высококачественным методом кодирования. Кодеки, построенные на базе данного метода, работают на скоростях не ниже 32 кбит/с. При этом полоса входного аналогового сигнала ограничена диапазоном 0,3-3,4 кГц. Для повышения качества преобразования полоса может быть расширена до 6 кГц, что соответствует скорости передачи 88 кбит/с при частоте дискретизации 12 кГц (при дальнейшем расширении полосы качество представления речи не повышается). Еще в 60-х годах был принят алгоритм оцифровки голоса под названием импульсно-кодовой модуляции (Pulse-Code Modulation — PCM, международный стандарт G.711). Оцифровка голосового сигнала включает измерение уровня аналогового сигнала через равные промежутки времени. В соответствии со стандартом G.711 принимается, что для узнаваемости голоса необходимо обеспечить передачу его частотных составляющих в диапазоне от 200 до 3400 Гц. Известно, что для правильной передачи всех частотных составляющих необходимо измерять уровень сигнала с частотой 8 кГц. В стандарте также принимается, что оцифровка аналогового сигнала производится с восьмиразрядным разрешением. При этом обычно используется один из двух способов установления соответствия между амплитудой звукового сигнала и цифровым значением - либо A-кодирование (оно принято в Европе и Азии), либо мю-кодирование (принятое в США, Канаде и некоторых других странах). И то и другое — просто таблицы соответствия между измеряемым значением напряжения и числом, при помощи которого оно кодируется. Для передачи одного голосового канала в цифровом виде требуется пропускная способность 64 кбит/с (8 кГц х 8 разрядов). 3.1.2 m-Law и A-Law кодирование
Когда звуковая карта получает звуковые данные, она преобразует каждое значение дискретизации в соответствующее значение напряжения, которое затем усиливается и подается на динамик или наушники. При изменении значения оцифрованного звука меняется напряжение, а динамик преобразует изменение напряжения в изменение звукового давления, которое в виде звуковой волны распространяется в воздухе и достигает вашего уха. Какая же связь между значением оцифрованного звука и генерируемым звуковой картой напряжением? Наиболее очевидный подход заключается в использовании линейной связи (linear relation), при которой, например, увеличение значения цифрового представления звука вдвое будет приводить к увеличению напряжения также в два раза. Однако этот подход не эффективен. Человеческое ухо воспринимает звук нелинейно: разница между малыми цифровыми представлениями звукового сигнала может быть слишком велика для слабых звуков, в то время как разница между большими представлениями будет слишком мала, чтобы ухо ее различило. Принимая во внимание указанную природу человеческого слуха вводят логарифмическую шкалу. Соотношения m-Law и A-Law соответствуют этой шкале. Соотношение m-Law используется, прежде всего, в Северной Америке и в Японии.
Для преобразования значения линейной дискретизации m в дискретизацию Ym используется следующее уравнение:
где mp — максимальное входное значение оцифрованного звука, а m — константа, обычно 100 или 255. A-Law используется в Европе. Оно также используется для преобразования значения линейной дискретизации в дискретизацию YA. А — это константа 87.6:
Соотношения m-Law и A-Law позволяют восьмиразрядные измерения представлять в том же диапазоне, что и линейные 12-разрядные. Таким образом, можно получить более чем 30% сжатия.
3.1.3 Методы эффективного кодирования речи После того как аналоговый сигнал преобразован в цифровую форму, к нему можно применять различные способы обработки, которые невозможно использовать при работе с чисто аналоговым сигналом. В частности, оцифрованный сигнал перед передачей можно сжать, уменьшив таким образом пропускную способность, необходимую для передачи одного голосового соединения. Методы сжатия речи разрабатываются для достижения определенных целей — нужных скоростей битового потока, качества сигнала, задержки и сложности. Чтобы гарантировать взаимную совместимость устройств кодирования и декодирования, организации по стандартам, такие как ITU-Т, ISO и ETSI, определяют эти цели в соответствии с предназначением каждого метода.. Несмотря на то, что алгоритмы сжатия реализуются на аппаратном уровне, с использованием специализированных процессоров обработки цифрового сигнала (Digital Signal Processor — DSP), все-таки эта операция может привести к задержкам в передаче голоса. При разработке высококачественных методов сжатия речи для скоростей цифровых потоков ниже 10 Кбит/с возникают особенные трудности. Для простых алгоритмов задержка невелика — единицы миллисекунд, однако для сложных алгоритмов, обеспечивающих значительное сжатие, продолжительность задержки может составлять около сотни миллисекунд, что вполне ощутимо при разговоре. К счастью, недавние достижения в области обработки цифровых сигналов (digital signal processing — DSP) и сверхбольших интегральных схем (very large scale integration — VLSI) сделали реализацию таких кодирующих устройств возможной и экономически эффективной.
3.1.4 Кодирование речи в стандарте CDMA В стандарте сотовой связи CDMA применяется метод многостанционного доступа с кодовым разделением каналов, основанный на использовании широкополосных сигналов. Каждому вызову присваивается уникальный код, позволяющий отличить этот вызов от других, передаваемых в том же частотном диапазоне. В этом стандарте обеспечивается более высокое качество речи, чем в стандарте GSM. Это во многом определяется применением кодирования речи. В системе CDMA для преобразования аналогового речевого сигнала в цифровой используется вокодер с переменной скоростью кодирования, в основу работы которого положен алгоритм с ЛП кода - CELP. Этот алгоритм учитывает особенности человеческой речи. Вокодер перекодирует цифровой поток, имеющий скорость 64 кбит/с, в поток со скоростью 8 или 13 кбит/с. В ходе этого преобразования информационный поток делится на кадры, и содержащие паузы интервалы удаляются. Результирующий поток имеет скорость от 1 до 8 кбит/с. Вокодер приемной стороны объединяет кадры в единый поток и делает обратное преобразование. Другой важной особенностью вокодера с переменной скоростью кодирования является использование адаптивного порога для определения требуемой скорости кодирования данных. Уровень порога изменяется в соответствии с фоновым шумом. Результатом этого является подавление фона и улучшение качества речи даже в шумной обстановке. Вокодер позволяет подмешивать в речевой канал вторичный трафик, т.е. служебную информацию.
3.1.5 Речевые кодеки для IP-телефонии Особенности функционирования каналов для передачи речевых данных, и прежде всего сети Интернет, а также возможные варианты построения систем телефонной связи на базе сети Интернет предъявляют ряд специфических требований к речевым кодекам (вокодерам). В силу пакетного принципа передачи и коммутации речевых данных отпадает необходимость кодирования и синхронной передачи одинаковых по длительности фрагментов речи. Наиболее целесообразным и естественным для систем IP-телефонии является применение кодеков с переменной скоростью кодирования речевого сигнала. В основе кодека речи с переменной скоростью лежит классификатор входного сигнала, определяющий степень его информативности и, таким образом, задающий метод кодирования и скорость передачи речевых данных. Наиболее простым классификатором речевого сигнала является Voice Activity Detector (VAD), который выделяет во входном речевом сигнале активную речь и паузы. При этом, фрагменты сигнала, классифицируемые как активная речь, кодируются каким-либо из известных алгоритмов (как правило на базе метода Code Excited Linear Prediction - CELP) с типичной скоростью 4 - 8 Кбит/с. Фрагменты, классифицированные как паузы, кодируются и передаются с очень низкой скоростью (порядка 0.1 - 0.2 Кбит/с), либо не передаются вообще. Передача минимальной информации о паузных фрагментах предпочтительна. Схемы более эффективных классификаторов входного сигнала детальнее осуществляют классификацию фрагментов, соответствующих активной речи. Это позволяет оптимизировать выбор стратегии кодирования (скорости передачи данных), выделяя для особо ответственных за качество речи участков речевого сигнала большее число бит (сответственно большую скорость), для менее ответственных - меньше бит (меньшую скорость). При таком построении кодеков могут быть достигнуты низкие средние скорости (2 - 4 Кбит/с) при высоком качестве синтезируемой речи. Необходимо отметить, что для рассматриваемых приложений традиционная для вокодеров проблема снижения задержки при обработке сигнала в кодеке не является актуальной, так как величина суммарной задержки при передаче речи в системах IP-телефонии главным образом определяется задержками вносимыми каналами сети Интернет. Тем не менее, решения, позволяющие снизить задержку в вокодере, представляют практический интерес. Основным источником возникновения искажений, снижения качества и разборчивости синтезированной речи является прерывание потока речевых данных, вызванное потерями при передачи по сети либо превышением предельно допустимого времени доставки пакета с речевыми данными. Гистограммы распределения числа последовательно потерянных пакетов показывают, что вероятность одиночных потерь выше вероятности потерь нескольких кадров подряд. Можно ожидать, что с развитием сети Интернет при дальнейшем увеличении ее пропускной способности, оптимизации маршрутизаторов и протоколов преобладающую роль будут играть потери одиночных пакетов. Следует заметить, что в случае прихода пакета данные, как правило, доставляются без ошибок. В таких условиях помехоустойчивое кодирование речевых данных нецелесообразно. Таким образом, одной из важнейших задач при построении вокодеров для IP-телефонии является создание алгоритмов компрессии речи толерантных к потерям пакетов. Для обслуживания широкой сети абонентов система IP телефонной связи с использованием шлюзов должна включать абонентские линии связи с аналоговыми окончаниями. Это означает, что синтезированный в шлюзе аналоговый речевой сигнал по соединительной линии будет поступать на телефонный аппарат абонента. Точно также сигнал с выхода микрофона телефонного аппарата абонента по аналоговой линии будет поступать на вход вокодера, размещенного в шлюзе. Хорошо известно, что классические алгоритмы низкоскоростной компрессии речи чувствительны к амплитудно-частотным искажениям, возможным в соединительных линиях и акустических трактах. При создании алгоритмов низкоскоростных вокодеров это обстоятельство должно приниматься во внимание.
3.1.6 Оценка качества кодирования речи При оценке качества кодирования и сопоставлении различных кодеков оцениваются разборчивость речи и качество синтеза (качество звучания) речи.
Для оценки разборчивости речи используется метод DRT (диагностический рифмованный тест). В этом методе подбираются пары близких по звучанию слов, отличающихся отдельными согласными, которые многократно произносятся рядом дикторов, и по результатам испытаний оценивается доля искажений. Метод позволяет получить как оценку разборчивости отдельных согласных, так и общую оценку разборчивости речи. Для оценки качества звучания используется критерий DAM (диагностическая мера приемлемости). Испытания заключаются в чтении несколькими дикторами (мужчинами и женщинами) ряда фраз, которые прослушиваются на выходе тракта связи рядом экспертов-слушателей, выставляющих оценки по 5-балльной шкале. Результатом является средняя субъективная оценка, или средняя оценка мнений (MOS). Хотя этот метод является субъективным, его результаты по сопоставлению различных типов кодеков при проведении испы- таний одними и теми же группами дикторов и экспертов-слушателей являются достаточно объективными, и на них основываются выводы и решения. В табл. 3 приведены результаты оценки четырех типов кодеков. Близкие к шкале MOS результаты дает объективный метод оценки качества с использованием понятия кепстрального расстояния (Cepstrum Distance - CD). Существует множество вариантов кодеков речи, из которых приходится выбирать кодек для ССС. Например, при разработке стандарта GSM были исследованы шесть типов кодеков, после чего выбор был остановлен на кодеке RPE-LTP. Работа по выбору типа кодека для стандарта GSM была завершена в 1988 г., а в 1989 г. был предложен метод VSELP, принятый затем в стандарте D-AMPS. Работы по совершенствованию кодекса речи продолжаются и в настоящее время. Обоими стандартами (D-AMPS и GSM) предусмотрено введение полускоростного кодирования, которое сможет увеличить пропускную способность канала связи в два раза. В числе исследуемых вариантов для стандарта D-AMPS рассматривается возможность введения векторного квантователя параметров линейных спектральных пар с расщеплением и межкадровым предсказанием, а для стандарта GSM - использование метода кодирования CELP. Таблица 3 Оценка кодеков речи по шкале MOS
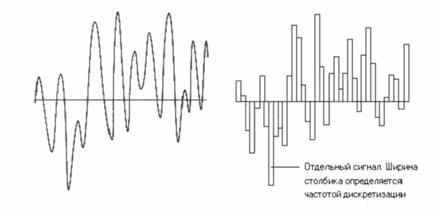
Основные понятия цифровой звукозаписи 3.2.1 Натуральное цифровое представление данных Одна из "цифровых" форм записи звуковых данных известна уже очень давно, с тех времен, когда не существовало никаких компьютеров. Это всем известная запись музыки при помощи нот. Такого рода запись активно применяется и сегодня (так называемый формат General MIDI, или просто MIDI) при использовании компьютера для создания электронной музыки. Фактически в таком случае в файл записываются не сами звуки, а правила их синтеза. Поэтому эту запись называют синтетической. Таким образом, можно добиться очень высокого качества звука, но ограничения, присущие этому методу, также очевидны. Синтетическая звукозапись не записывается, а конструируется. С ее помощью нельзя записать игру реального оркестра или пение, она также не имеет средств для записи естественной речи и вообще произвольных звуков, которые нельзя представить в виде набора простых стандартных звуковых единиц ("нот"). Поэтому, более распространен натуральный способ цифровой записи звука, заключающийся в хранении самой формы звуковой волны, то есть, регистрации в цифровом виде изменения амплитуды звукового сигнала с течением времени. Это основной способ цифровой записи звука, так как в нем не делается различий в отношении того, какой именно звук записывается. Исходная форма волны, как уже говорилось, - непрерывная аналоговая величина, поэтому в ходе записи производится аналогово-цифровое преобразование. При воспроизведении звука требуется обратное, цифро-аналоговое преобразование. 3.2.2 Кодирование РСМ Метод натуральной цифровой записи звука называется РСМ (Pulse Code Modulation - импульсно-кодовая модуляция). Он заключается в том, что в ходе записи в течение каждой секунды многократно регистрируется текущая амплитуда звуковой волны. Некоторое значение амплитуды рассматривается как предельное, которое может быть представлено в звукозаписи. Ему соответствует максимальное целое число, которое "умещается" внутри соответствующего элемента данных. Текущее значение масштабируется относительно максимального и округляется до ближайшего целого числа. В результате получается как бы моментальный снимок звуковой волны. Вся звукозапись представляет собой последовательность таких "снимков". Терминология, используемая в компьютерной цифровой звукозаписи, не устоялась как в русском, так и в английском языке, что выражается в том, что одни и те же термины используются для обозначения совершенно разных понятий. Так, с помощью английского термина sample обозначают как отдельный "снимок" звуковой волны, так и всю временную последовательность таких снимков.
Рисунок 3.1 На русском языке в том же смысле часто используют термин "сигнал". Сигнал обозначает отдельный снимок звуковой волны, а всю последовательность сигналов мы будем рассматривать как волновую форму (в соответствии с другим часто используемым английским термином waveform).
|