Тема: ДІАГРАМИ ПОТОКІВ ДАНИХ
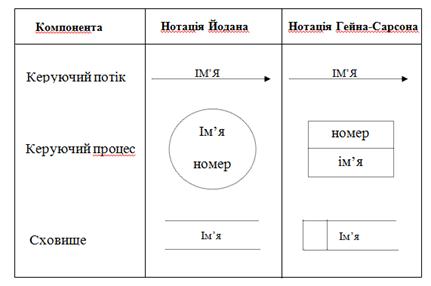
Діаграми потоків даних (DFD) є основним засобом моделювання функціональних вимог майбутнього ПЗ. З їх допомогою ці вимоги розбиваються на функціональні компоненти (процеси) і представляються у вигляді мережі, зв'язаної потоками даних. Головна мета таких засобів - продемонструвати, як кожен процес перетворить свої вхідні дані у вихідні, а також виявити відносини між цими процесами [11]. При використанні цієї моделі систему представляють у вигляді ієрархії діаграм потоків даних, що описують асинхронний процес перетворення інформації з моменту введення в систему до видачі користувачеві. На кожному наступному рівні ієрархій відбувається уточнення процесів, поки черговий процес не буде визнаний елементарним. Примітка. Моделі потоків даних були незалежно запропоновані спочатку Е. Йорданом (1975), потім Ч. Гейном і Т. Сарсоном (1979). На цих моделях засновані класичні методології структурного аналізу і проектування програмного забезпечення відповідно Йордана-де Марка і Гейна-Сарсона. Та ж модель використовується в методології структурного аналізу і проектування SSADM (Structured Systems Analysis and Design Method) прийнятою в Великобританії як національний стандарт розробки інформаційних систем. У основі моделі лежать поняття зовнішньої сутності, процесу, сховища (накопичувача) даних і потоку даних. Зовнішня сутність - матеріальний об'єкт або фізична особа, що виступають в якості джерел або приймачів інформації, наприклад, замовники, персонал, постачальники, клієнти банк і тому подібне. Процес - перетворення вхідних потоків даних у вихідні відповідно до певного алгоритму. Кожен процес в системі має свій номер і пов'язаний з виконавцем який здійснює дане перетворення. Як у разі функціональних діаграм фізично перетворення може здійснюватися комп'ютерами, уручну або спеціальними пристроями. На верхніх рівнях ієрархії, коли процеси ще не визначені, замість поняття «процес» використовують поняття «система» і «підсистема», які позначають відповідно систему в цілому або її функціонально закінчену частину. Сховище даних - абстрактний пристрій для зберігання інформації. Тип пристрою і способи розміщення, вилучення і зберігання для такого пристрою не деталізують. Фізично це може бути база даних, файл, таблиця в оперативній пам'яті, картотека на папері і тому подібне. Потік даних — процес передачі деякої інформації від джерела до приймача. Фізично процес передачі інформації може відбуватися по кабелях під управлінням програми або програмної системи або уручну за участю пристроїв або людей зовні проектованої системи. Таким чином, діаграма ілюструє як потоки дані, породжені деякими зовнішніми сутностями, трансформуються відповідними процесами (або підсистемами), зберігаються накопичувачами даних і передаються іншій зовнішній суті — приймачам інформації. В результаті ми отримуємо мережеву модель зберігання/обробки інформації. Для зображення діаграм потоків даних традиційно використовують два види нотацій: нотації Йордана і Гейна-Сарсона (табл. 9.1).
Таблиця 9.1.
Зображення потоків даних у двох нотаціях
Над лінією потоку, напрям якого позначають стрілкою, вказують, яка конкретно інформація в даному випадку передається (рис. 9.1).
Побудову ієрархії діаграм потоків даних починають з діаграми особливого вигляду - контекстної діаграми, яка визначає найбільш загальний вид системи. На такій діаграмі показують, як система, що розробляється, взаємодіятиме з приймачами і джерелами інформації без вказівки виконавців, тобто описують інтерфейс між системою і зовнішнім світом. Зазвичай початкова контекстна діаграма має форму зірки. Якщо проектована система містить велику кількість зовнішніх сутностей (більше 10-ти), має розподілену природу або включає вже існуючі підсистеми, то будують ієрархії контекстних діаграм. При розробці контекстних діаграм відбувається деталізація функціональної структури майбутньої системи, що особливо важливо, якщо розробка ведеться декількома колективами розробників. Отриману таким чином модель системи перевіряють на повноту початкових даних про об'єкти системи і ізольованість об'єктів (відсутність інформаційних зв'язків з іншими об'єктами). На наступному етапі кожну підсистему контекстної діаграми деталізують за допомогою діаграм потоків даних. В процесі деталізації дотримуються правила балансування – при деталізації підсистеми можна використовувати компоненти тільки тих підсистем, з якими у підсистеми, що розробляється, існує інформаційний зв'язок (тобто з якими вона пов'язана потоками даних) [11]. Рішення про завершення деталізації процесу ухвалюють в наступних випадках: • процес взаємодіє з 2-3-ма потоками даних; • можливий опис процесу послідовним алгоритмом; • процес виконує єдину логічну функцію перетворення вхідної інформації у вихідну. На процеси, що не деталізуються, складають специфікації, які повинні містити опис логіки (функцій) даного процесу. Такий опис може, виконуватися: на природній мові, із застосуванням структурованої природної мови (псевдокодів), з застосуванням таблиць і дерев рішень, у вигляді схем алгоритмів, зокрема flow-форм і діаграм Насси-Шнейдермана. Для полегшення сприйняття процеси підсистеми, що деталізується, нумерують, дотримуючи ієрархію номерів: так процеси, отримані при деталізації процесу або підсистеми «1» повинні нумеруватися «1.1», «1.2» і так далі. Окрім цього бажано розміщувати на кожній діаграмі від 3-х до 6-7-ми процесів і не захаращувати діаграми деталями, не суттєвими на даному рівні. Декомпозицію потоків даних необхідно здійснювати паралельно з декомпозицією процесів. Остаточно розробку моделі виконують в два етапи. 1 етап - побудова контекстної діаграми - включає виконання наступних дій: • класифікацію безлічі вимог і організацію їх в основні функціональні групи — процеси; • ідентифікацію зовнішніх об'єктів - зовнішньої суті, з якою система повинна бути зв'язана; • ідентифікацію основних видів інформації - потоків даних, що циркулює між системою і зовнішніми об'єктами; • попередню розробку контекстної діаграми; • вивчення попередньої контекстної діаграми і внесення до неї змін по результатам відповідей на питання, що виникають при вивченні, по всіх її частинах; • побудова контекстної діаграми шляхом об'єднання всіх процесів попередньої діаграми в один процес, а також групування потоків. 2 етап - формування ієрархії діаграм потоків даних – включає для кожного рівня: • перевірку і вивчення основних вимог по діаграмі відповідного рівня (для першого рівня - по контекстній діаграмі); • декомпозицію кожного процесу поточної діаграми потоків даних з допомогою деталізуючої діаграми або — якщо деяку функцію складно або неможливо виразити комбінацією процесів, побудова специфікації процесу; • додавання визначень нових потоків в словник даних при кожній появі їх на діаграмі; • проведення ревізії з метою перевірки коректності і поліпшення наочності моделі після побудови двох-трьох рівнів. Повна специфікація процесів включає також опис структур даних, які використовуються як при передачі інформації в потоці, так і при зберіганні в накопичувачі. Описані структури даних можуть містити альтернативи, умовні входження і ітерації. Умовне входження означає, що відповідні елементи даних в структурі можуть бути відсутніми. Альтернатива означає, що в структуру може входити один з перерахованих елементів. Ітерація означає, що елемент може повторюватися деяка кількість разів. Крім того, для даних повинен бути вказаний тип: безперервне або дискретне значення. Для безперервних даних можуть визначатися одиниці вимірювань, діапазон значень, точність уявлення і форма фізичного кодування. Для дискретних - може указуватися таблиця допустимих значень. Отриману закінчену модель необхідно перевірити на повноту і узгодженість. Під узгодженістю моделі в даному випадку розуміють виконання для всіх потоків даних правила збереження інформації: що всі поступають куди-небудь дані повинні бути зчитані і записані. Приклад 9.1. Розглянемо процес СКЛАДАННЯ ЕКЗАМЕНУ. У нас є дві сутності СТУДЕНТ і ВИКЛАДАЧ. Опишемо потоки даних, якими обмінюється наша система із зовнішніми об'єктами (рис.9.2).
Рисунок 9.2 – Опис потоків даних між майбутньою системою та зовнішніми сутностями з використанням нотації Йордана
З боку сутності СТУДЕНТ опишемо інформаційні потоки. Для складання іспиту необхідно, щоб у СТУДЕНТА була залікова КНИЖКА, а також щоб він мав ДОПУСК ДО ЕКЗАМЕНУ. Результатом складання екзамену, тобто вихідними потоками будуть ОЦІНКА ЗА ЕКЗАМЕН і залікова КНИЖКА, в яку буде проставлена ОЦІНКА. З боку сутності ВИКЛАДАЧ інформаційні потоки наступні. ЕКЗАМЕНАЦІЙНА ВІДОМІСТЬ згідно якої буде відомо, що СТУДЕНТ допущений до екзамену, а також офіційний папір, куди буде занесений результат екзамену, тобто ОЦІНКА ЗА ЕКЗАМЕН, ПРОСТАВЛЕНА У ВІДОМІСТЬ. Тепер деталізуємо процес 1.СКЛАДАННЯ ЕКЗАМЕНУ. Цей процес міститиме наступні процеси (рис.9.3): 1.1. Витягнути білет. 1.2. Підготуватися до відповіді. 1.3. Відповіді на білет. 1.4. Виставлення оцінки.
Рисунок 9.3 – Деталізація процесу СКЛАДАННЯ ЕКЗАМЕНУ Приклад 9.2. Розробимо ієрархію діаграм потоків даних програми побудови графіків/таблиць функцій. Розробку почнемо з побудови контекстної діаграми. Для чого визначимо зовнішні сутності і потоки даних між ними та програмою. У даної системи єдина зовнішня сутність Учень. Він вводить або вибирає із списку функцію, задає інтервал і кількість точок, а потім отримує таблицю значень функції і її графік. На рис. 9.4 представлена контекстна діаграма системи. Деталізуючи цю діаграму, отримуємо три процеси: Введення/вибір функції і її розбір, Побудова таблиці значень функції і Побудова графіка функції. Для зберігання функцій додаємо сховище функцій. Потім визначаємо потоки даних. Отримали деталізуючу діаграму потоків даних (рис. 9.5) Приклад 9.3. Розробити ієрархію діаграм потоків даних системи обліку успішності студентів. Як зовнішня сутність для системи виступають Декан, Заступник декана по курсу і Співробітник деканату. Визначимо потоки даних між цими сутностями і системою. Декан повинен отримувати (рис. 9.6): • зведення успішності по факультету (відсоток успішності груп, курсів і в цілому по факультету) на теперішній або вказаний момент часу; • повні відомості про навчання конкретного студента (успішність по всіх вивчених предметам всіх завершених семестрів навчання з урахуванням перездач). Заступник декана по курсу повинен отримувати: • зведення успішності по курсу (відсоток успішності по групах) на поточний або вказаний момент; • зведення про здачу іспитів і заліків вказаною групою; • поточні відомості про успішність конкретного студента; • повні відомості про навчання конкретного студента (успішність по всіх вивчених предметам всіх завершених семестрів навчання з урахуванням перездач); • список боржників по факультету з вказівкою груп і незданих предметів. Співробітник деканату повинен забезпечувати: · введення списків студентів, зарахованих на перший курс; · коректування списків студентів відповідно до наказів про зарахування, відрахування перекладі і т. п.; · введення учбових планів кафедр; · введення розкладу сесії; · введення результатів здачі заліків і іспитів на підставі відомостей і напрямів. Крім того, співробітник декана повинен мати можливість отримувати: • довідку про предмети, що прослуховують студентом, з вказівкою годинника і підсумкових оцінок; • додаток до диплома випускника також з вказівкою годинника і підсумкових оцінок.
Далі деталізуємо процеси в системі. На рис. 9.7 представлена деталізуюча діаграма потоків даних, де виділено дві підсистеми: Підсистема наповнення бази даних і Підсистема формування звітів, а також сховище даних, яке може бути реалізоване як за допомогою засобів СУБД, так і без них. Вирішення про доцільність використання засобів СУБД може бути прийняте пізніше, після аналізу структур даних, що зберігаються. Подальшу деталізацію процесів можна не виконувати, оскільки їх суть для розробника очевидна. Проте стає ясно, що повна специфікація даної розробки повинна включати опис бази даних. Окрім цього, для даної системи доцільно виконати моделювання керуючих процесів, що дозволить уточнити організацію процесу обробки даних.
Керуючий процес отримує за допомогою керуючих потоків деяку інформацію про ситуації в системі і ініціює за допомогою керуючого потоку відповідні процеси. На діаграмах керуючих потоків даних, використовують ті ж позначення, що і для звичайних потоків, але зображають їх пунктирною лінією.
Таблиця 9.2. Позначення керуючих процесів
Додатково може бути вказаний тип керуючого потоку: • Т-потік (Trigger Flow - тригерний потік) – керуючий потік, який може тільки «вмикати» процес - наступний керуючий сигнал знову «включить» процес, навіть якщо процес вже активний; • А-потік (Activator Flow - активуючий потік) – керуючий потік, який може як «вмикати», так і «вимикати» процес - якщо процес включений, то наступний сигнал його вимкне; • E/D-потік (Enable/Disable Flow - перемикальний потік) – керуючий потік, який може включати процес сигналом по одній (Е) лінії і вимикати - сигналом по іншій (D) лінії. При необхідності тип потоку даних (керуючий або звичайний) можна змінювати. Для цього використовують спеціальне позначення - вузол зміни типу потоку даних (рис. 11.8). До цього вузлу потік підходить як потік даних, а виходить з нього як керуючий потік. Декомпозиція даних і відповідні розширення діаграм потоків даних [38].Індивідуальні дані в системі часто є незалежними. Проте іноді необхідно мати справу з декількома незалежними даними одночасно. Наприклад, в системі є потоки ЯБЛУКА, АПЕЛЬСИНИ і ГРУШІ. Ці потоки можуть бути згруповані за допомогою введення нового потоку ФРУКТИ. Для цього необхідно визначити формально потік ФРУКТИ, що складається з декількох елементів-нащадків. Таке визначення задається за допомогою форми Бекуса-Наура (БНФ)в словнику даних. У свою чергу потік ФРУКТИ сам може міститися в потоці-предку ЇЖА разом з потоками ОВОЧІ, М'ЯСО та ін. Такі потоки, які об'єднують декілька потоків, отримали назву групових.
Зворотна операція, розщеплювання потоків на підпотоки, здійснюється з використанням групового вузла (табл. 9.3), що дозволяє розщеплювати потік на будь-яке число підпотоків.
Таблиця 9.3. Розширені позначення на діаграмах потоків даних
При розщеплюванні також необхідно формально визначити підпотоки в словнику даних (за допомогою БНФ). Аналогічним чином здійснюється і декомпозиція потоків через межі діаграм, що дозволяє спростити деталізуючу DFD. Нехай є потік ФРУКТИ, що входить в процес, що буде деталізуватися. На деталізованій діаграмі процесу ФРУКТИ може не бути зовсім, але замість нього можуть бути потоки ЯБЛУКА і АПЕЛЬСИНИ (нібито вони передані з процесу, що деталізується). В цьому випадку повинно існувати БНФ-визначення потоку ФРУКТИ, що складається з підпотоків ЯБЛУКА і АПЕЛЬСИНИ, для цілей балансування. Застосування цих операцій над даними дозволяє забезпечити структуризацію даних, збільшує наочність і читабельність діаграм. Для забезпечення декомпозиції даних і деяких інших сервісних можливостей до DFD додаються наступні типи об'єктів: 1) ГРУПОВИЙ ВУЗОЛ. Призначений для розщеплювання і об'єднання потоків. В деяких випадках може бути відсутнім (тобто фактично вироджуватися в точку злиття/розщеплювання потоків на діаграмі). 2) ВУЗОЛ-ПРЕДОК. Дозволяє пов'язувати вхідні та вихідні потоки між процесом, що деталізується, і деталізуючою DFD. 3) НЕВЖИВАНИЙ ВУЗОЛ. Застосовується за ситуації, коли декомпозиція даних проводиться в груповому вузлі, при цьому потрібні не всі елементи вхідного у вузол потоку. 4) ВУЗОЛ ЗМІНИ ІМЕНІ. Дозволяє неоднозначно іменувати потоки даних, при цьому їх вміст еквівалентний. Наприклад, якщо при проектуванні різних частин системи один і той же фрагмент даних отримав різні імена, то еквівалентність відповідних потоків даних забезпечується вузлом зміни імені. При цьому один із потоків даних є вхідним для даного вузла, а інший вихідним. 5) Текст у вільному форматі в будь-якому місці діаграми.
|