
Подход на основе условных вероятностей (теоремы Байеса)
Рассматриваемый здесь подход к построению логического вывода на основе условных вероятностей называют байесовским. Байесовский подход не является единственным подходом к построению выводов на основе использования вероятностей, но он представляется удобным в условиях, когда решение приходится принимать на основе части свидетельств и уточнять по мере поступления новых данных. В сущности, Байес исходит из того, что любому предположению может быть приписана некая ненулевая априорная (от лат. a priori - из предшествующего) вероятность того, что оно истинно, чтобы затем путем привлечения новых свидетельств получить апостериорную (от лат. a posteriori - из последующего) вероятность истинности этого предположения. Если выдвинутая гипотеза действительно верна, новые свидетельства должны способствовать увеличению этой вероятности, в противном же случае должны ее уменьшать. Примем для дальнейших рассуждений следующие обозначения: Р(Е:H) - вероятность получения свидетельства Е при условии, что гипотеза Н верна;
Здесь обнаруживаются достоинства байесовского метода. Первоначальная (априорная) оценка вероятности истинности гипотезы Р(Н) могла быть весьма приближенной, но она позволила путем учета свидетельства Е получить более точную оценку Р(Н:Е), которую можно теперь использовать в качестве обновленного значения Р(Н) для нового уточнения с привлечением нового свидетельства. Иначе говоря, процесс уточнения вероятности Р(Н) можно повторять снова и снова с привлечением все новых и новых свидетельств, каждый раз обращаясь к одной и той же формуле. В конечном счете, если свидетельств окажется достаточно, можно получить окончательный вывод об истинности (если окажется, что Р(Н) близка к1) или ложности (если окажется, что Р(Н) близка к 0) гипотезы Н. Шансы и вероятности связаны между собой следующей формулой: В некоторых странах использование шансов более распространено, чем использование вероятностей. Кроме того, использование шансов вместо вероятностей может быть более удобным с точки зрения вычислений. Переходя к шансам в рассмотренных нами формулах, получим: Если же перейти к логарифмам величин, а в базе знаний хранить логарифмы отношений Р(Е:Н)/Р(Е:неН), то все вычисления сводятся просто к суммированию, поскольку ln |O(H:E)| = ln |Р(Е:Н)/Р(Е:неН)| + ln |O(H)|.
Против использования шансов есть несколько возражений, главное из которых состоит в том, что крайние значения шансов равны "плюс" и "минус" бесконечности, тогда как для вероятностей это 0 и 1. Поэтому шансы использовать удобно в тех случаях, когда ни одна из гипотез не может быть ни заведомо достоверной, ни заведомо невозможной. Как принцип байесовский подход выглядит прекрасно, но есть и несколько проблем, связанных с его применением. Первое замечание касается возможности вычисления величины Р(Е). Эту величину легко определить, если есть возможность вычислить Р(Е:неН), а это не всегда можно сделать. Одна из возможностей обойти это затруднение состоит в переходе к полной группе событий, однако это не спасает положение, если состав полной группы событий неизвестен. Можно пользоваться и грубыми оценками, если сохраняется точность диагноза. Кроме того, если Р(Н) уточняется в ходе работы, то Р(Е) можно тоже уточнять. Второе замечание касается используемого в этом подходе предположения о независимости свидетельств. С теоретической точки зрения это замечание очень серьезно, но поскольку в конце процесса диагноза нас интересуют не столько точные значения вероятностей (это больше беспокоит статистиков), сколько соотношения вероятностей, то при одинаковом порядке ошибочности оценок вероятностей гипотез для практики более важной оказывается правильность общей картины, создаваемой экспертной системой.
Рассмотрим простой пример. В табличной форме представлены некие воображаемые данные, которые могли бы (именно могли бы) быть использованы для предсказания продолжительности жизни. Как бы там ни было, это - иллюстрация рассматриваемых принципов. Таблица 4.1
В приводимой табл. 4.1 содержатся данные по 100 умершим людям, из которых 44 умерли в возрасте за 75 лет, а остальным было 75 лет или меньше, причем указано, кто среди них был курильщиком, а кто нет. (Не забывайте, что это просто пример, а не реальные данные.) Априорные шансы в этой выборке из 100 случаев в пользу человек проживет более 75 лет: О (Долгожитель) = 44/56 = 11/14 = 0,7857, а отношения правдоподобия ОП(Долгожитель: Курящий) = (20/44) / (33/56) = (20*56) / (44*33)= =320/363 = 0,8815; ОП(Долгожитель: Некурящий) = (24 • 56)/(44 • 23) = 336/25= =1,3280. Предположим далее для наших иллюстративных целей, что принимается во внимание как еще одна переменная, имеющая отношение к долгожительству. Согласно табл. 4.2 отношение правдоподобия дпя мужчин ОП(Долгожитель: Мужчина) = (24/44)/(36/56) = 0,8484; дпя женщин ОП (Долгожитель: Женщина) = (20/44) /(20/56) = 1,2727.
Таблица 4.2
Теперь, учитывая, что априорные шансы в пользу продолжительной жизни (свыше 75 лет) равны 11/14, мы можем вычислить апостериорные шансы того, что курящий мужчина проживет долгую жизнь, пользуясь выражением О’ (Долгожитель) = ОП (Долгожитель: Курящий)) * *ОП (Долгожитель: Мужчина) * О (Долгожитель), откуда О' (Долгожитель) = 0,8815* 0,8484*11/14, что примерно равно 0,5876. Это значение соответствует вероятности 0,3701, тогда как начальная вероятность была 0,44. Таков результат учета двух довольно негативных факторов. Этот же принцип допускает модификацию для работы более чем с двумя гипотезами (колонками таблицы) без особых затруднений. Отношения правдоподобия всегда положительны. Хотя нуль и бесконечность могут встретиться, всегда есть возможность избежать этих значений, при необходимости слегка подправив данные. Тогда ОП >1 указывает свидетельства в пользу гипотезы, ОП<1 — против нее, а ОП = 1 говорит о том, что свидетельства не влияют на правдоподобие рассматриваемой гипотезы. Множитель ОП показывает, насколько более вероятной становится данная гипотеза при наличии свидетельств, чем при их отсутствии. Если свидетельства сами по себе вызывают сомнения, то не составляет труда построить масштабированное ОП', такое как ОП’ = ОП* BC+ (1 — ВС), где ВС — вероятность того, что свидетельство надежно. Например, если свидетельство известно с вероятностью p = 0,8, то отношение правдоподобия, равное 1,2 (в пользу гипотезы), уменьшится до 1,2* 0,8 + 0,2 = 0,96 + 0,2 = 1,16, тогда как отношение правдоподобия 0,5, значительно противоречащее гипотезе, увеличится до 0,5 0,5+0,5 =0,75, т. е. в меньшей степени противоречит гипотезе. Подводя итоги, отметим, что отношения правдоподобия дают два имущества: во-первых, они допускают комбинирование нескольких независимых источников данных; во-вторых, их легко корректировать, свидетельство ненадежно само по себе. Здесь имеется, однако, замаскированное препятствие – слово “независимый”. Необходимо дополнительное исследование, чтобы оправдать рассмотрение данных о мужчинах/женщинах и курящих/некурящих как два независимых источника информации. А такое дополнительное рассмотрение не только потребует много времени, но и приведет к гораздо большей таблице, с большим числом клеток, каждая из которых будет содержать слишком малую по объему выборку, чтобы можно было ей довериться. В любой реальной совокупности указателей (индикаторов) почти неизбежно будет иметься какая-то степень ассоциации. Ее минимизация является важной практической задачей. Другими словами, было бы неразумно добавить к нашему списку индикаторов такие данные, как бородатые/безбородые, поскольку вряд ли найдется хоть одна бородатая женщина. Точно так же сильный-кашель/отсутствие-кашля также не бyдет хорошей дополнительной переменной, поскольку среди курящих с большей вероятностью встретятся люди с хроническим кашлем. В последнем случае возникает опасность, что один и тот же эффект будет измерен дважды. Приведенные примеры являются весьма очевидными случаями корреляций, однако могут быть более запутанные ситуации, так что в задачу программного обеспечения системы должны входить их отфильтрование или соответствующая калибровка значений отношений пpaвдоподобия, когда такие корреляции встречаются.
|
 и
и  .
.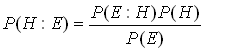 .
. .
. .
. .
.


