Недостатки СУБД
Лекция 3. СУБД как средство создания и обработки базы данных. Уровни представления данных: внешний, концептуальный, внутренний. Языки, используемые в БД: язык описания, манипулирования данными, язык запросов Современные авторы часто употребляют термины «банк данных» и «база данных» как синонимы, однако в общеотраслевых руководящих материалах по созданию банков данных эти понятия различаются. Программы, с помощью которых пользователи работают с БД, называются приложениями. В общем случае с одной БД могут работать множество различных приложений. Основная цель СУБД заключается в том, чтобы предложить пользователю абстрактное представление данных, скрыв конкретные особенности хранения и управления ими. Следовательно, отправной точкой при проектировании базы данных должно быть абстрактное и общее описание информационных потребностей организации, которые должны найти свое отражение в создании базы данных. Более того, поскольку база данных является общим ресурсом, то каждому пользователю может потребоваться свое, отличное от других представление о характеристиках информации, сохраняемой в БД. Для удовлетворения этих потребностей архитектура большинства современных коммерческих СУБД в той или иной степени строится на базе так называемой архитектуры ANSI – SPARC (ANCI – American National Standard Institute - Национальный институт стандартизации США, SPARC – Standards Planning And Requirements Committee – комитет планирования стандартов и норм ANSI). Уровень, на котором воспринимает данные пользователи, называется внешним уровнем, тогда как СУБД и ОС воспринимает данные на внутреннемуровне. Концептуальный уровень представления данных предназначен для отображения внешнего уровня на внутренний и обеспечения необходимых независимостей друг от друга. Фактически концептуальный уровень отображает обобщенную модель предметной области. Этот уровень содержит логическую структуру всей базы данных. На этом уровне представлены следующие компоненты: - Все сущности, их структуры и связи - Накладываемые на данные ограничения - Семантическая информация о данных - Информация о мерах обеспечения безопасности и поддержки целостности данных. Внутренний уровень описывает физическую реализацию БД и предназначен для достижения оптимальной производительности и обеспечения экономного использования дискового пространства. Он содержит описание структур данных и организации отдельных файлов, используемых для хранения данных в запоминающих устройствах. На этом уровне осуществляется взаимодействие СУБД с методами доступа ОС с целью размещения данных на запоминающих устройствах, создания индексов, извлечения данных и т.д. Ниже внутреннего уровня находится физический уровень, который контролируется ОС, но под руководством СУБД. Этот уровень – собственно данные, расположенные в файлах или в страничных структурах, расположенных на внешних носителях. В архитектуре базы данных ANSI – SPARC используется три уровня абстракции: внешний, концептуальный и внутренний (рис.2)
Внешний
Концептуальный уровень
Физическая организация данных
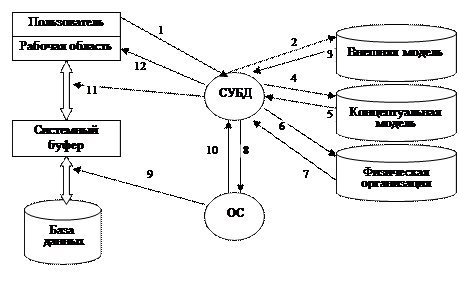
Рисунок 1. Трехуровневая архитектура ANSI – SPARC.
Цель трехуровневой архитектуры заключается в отделении пользовательского представления БД от ее физического представления. Перечислим несколько причин, по которым желательно выполнять такое разделение. - Каждый пользователь должен иметь возможность обращаться к одним и тем же данным, используя свое собственное представление о них. - Пользователи не должны непосредственно иметь дело с такими подробностями физического хранения данных в базе, как индексирование и хеширование, иначе говоря, взаимодействие поля с базой не должно зависеть от особенностей хранения в ней данных. - Администратор БД должен иметь возможность изменять структуру хранения данных в базе, не оказывая влияния на пользовательские представления. - Внутренняя структура БД не должна зависеть от таких изменений физических аспектов хранения информации, как переключение на новое устройство хранения. Эта архитектура позволяет обеспечить логическую (между уровнями 1 и 2) и физическую (между уровнями 2 и 3) независимость при работе с данными. Логическая независимость предполагает возможность изменения одного приложения без корректировки других приложений, работающих с этой же базой данных. Физическая независимость предполагает возможность переноса хранимой информации с одних носителей на другие при сохранении работоспособности всех приложений, работающих с данной БД. Это именно то, чего не хватало в файловых системах. Выделение концептуального уровня позволило разработать аппарат централизованного управления БД. Классификация СУБД и основные их функции. В общем случае под СУБД можно понимать любой программный продукт, поддерживающий процессы создания, ведения и использования БД. Рассмотрим какие из имеющихся на рынке программ имеют отношение к БД и в какой мере они связаны с базами данных. К СУБД относятся следующие основные виды программ: полнофункциональные СУБД, серверы БД, клиенты БД, средства разработки программ работы с БД. Полнофункциональные СУБД (ПСУБД) представляют собой традиционные СУБД, которые сначала появились для больших машин, затем для мини-машин и для ПЭВМ. Из числа всех СУБД современные ПСУБД являются наиболее многочисленными и мощными по своим возможностям. Обычно ПСУБД имеют развитый интерфейс, позволяющий с помощью команд меню выполнить основные действия с БД: создавать и модифицировать структуры таблиц, вводить данные, формировать запросы, разрабатывать отчеты, выводить их на печать и т.п. Для создания запросов и отчетов не обязательно программирование, а удобно пользоваться языком QBE. Многие ПСУБД включают средства программирования для профессиональных разработчиков. Серверы БД предназначены для организации центров обработки данных в сетях ЭВМ. Эта группа БД в настоящее время менее многочисленна, но их количество постепенно растет. Серверы БД реализуют функции управления базами данных, запрашиваемые другим (клиентскими) программами обычно с помощью операторов SQL. В роли клиентских программ для серверов БД в общем случае могут использоваться различные программы: ПСУБД, электронные таблицы, текстовые процессоры, программы электронной почты и т.д. При этом элементы пары «клиент-сервер» могут принадлежать одному или разным производителям программного обеспечения. В случае, когда клиентская и серверная части выполнены одной фирмой, естественно ожидать, что распределение функций между ними выполнено рационально. Средстваразработки программ работы с БД могут использоваться для создания разновидностей следующих программ: клиентских программ, серверов БД и отдельных компонентов, пользовательских приложений. Программы первого и второго вида довольно многочисленны, так как предназначены, главным образом, для системных программистов. Пакетов третьего вида гораздо больше, но меньше, чем полнофункциональные СУБД. По характеру использования СУБД делят на персональные и многопользовательские. Персональные СУБД обычно обеспечивают возможность создания персональных БД и недорогих приложений, работающих с ними. Персональные СУБД или разработанные с их помощью приложения зачастую могут выступать в роли клиентской части многопользовательской СУБД. К персональным СУБД, например, относятся Visual FoxPro, Paradox, Clipper, dBase, Access и др. Многопользовательские СУБД включают в себя сервер БД или клиентскую часть и, как правило, могут работать в неоднородной вычислительной среде (с разными типами ЭВМ и операционными системами). К многопользовательским СУБД относятся, например, СУБД Oracle и Informix. По используемой модели данных СУБД (как и БД), разделяют на иерархические, сетевые, реляционные, объектно-ориентированные и другие типы. Некоторые СУБД могут одновременно поддерживать несколько моделей данных. Языки баз данных. Внутренний язык СУБД для работы с данными состоит из двух частей: языка определения данных DDL и языка управления данными DML. Язык описания данных(DDL- Data Definition Language) - высокоуровневый непроцедурный язык декларативного типа, предназначенный для описания логической структуры данных используется для определения схемы БД. Язык DML манипулирования данными (DML-Data Manipulation Language) – совокупность конструкций, обеспечивающих выполнение основных операций по работе с данными: ввод, модификацию и выборку данных по запросам предназначении для чтения и обновления данных, хранимых в базе. Эти языки называются подъязыкми данных, поскольку в них отсутствуют конструкции для выполнения всех вычислительных операций, обычно используемых в языках программирования высокого уровня. Общее описание базы данных называется схемой базы данных. Схема БД состоит из набора определений, выраженных на специальном языке определения данных DDL. Результатом компиляции DDL–операторов является набор таблиц, хранимых в особых файлах, называемых системным каталогом. В системном каталоге интегрированы метаданные, т.е. данные, которые описывают объекты БД, а также позволяют упростить способ доступа к ним и управления ими. Язык DML – язык содержащий набор операторов для поддержки основных операций манипулирования содержащимися в базе данных. К операциям управления данными относятся: вставка в БД новых сведений; модификация сведений, хранимых в БД; извлечение сведений, содержащихся в БД; удаление сведений из БД. Языки DML отличаются базовыми конструкциями извлечения данных. Следует различать два типа языков DML: процедурный и непроцедурный. Основное отличие между ними заключается в том, что процедурные языки указывают то, как можно получить результат оператора языка DML, тогда как непроцедурные языки описывают то, какой результат будет получен. Как правило, в процедурных языках записи рассматриваются по отдельности, тогда как непроцедурные языки оперируют с целыми наборами записей. Непроцедурные языки DML позволяют определить весь набор требуемых данных с помощью одного оператора извлечения или обновления. Реляционные СУБД в той или иной форме обычно включают поддержку непроцедурных языков манипулирования данными – чаще всего это бывают языки структурированных запросов - SQL или язык запросов по образцу - QBE. Кроме этого в СУБД используется структурированный язык запросов – SQL. Рассмотрим взаимодействие пользователя, СУБД и ОС при обработке запроса на получение данных (рисунок 2).
Рисунок.2. Схема прохождения запроса к БД
На рисунке 3.2 цифрами обозначена последовательность выполняемых действий. 1. Пользователь отправляет СУБД запрос на получение данных из БД. 2. Анализ прав пользователя и внешней модели данных соответствующей данному пользователю, подтверждает или запрещает доступ данного пользователя к запрошенным данным. 3. В случае запрета на доступ к данным СУБД сообщает пользователю об этом (12) и прекращает дальнейший процесс обработки данных, в противном случае СУБД определяет часть концептуальной модели, которая затрагивается запросом пользователя. 4. СУБД получает информацию о запрошенной части концептуальной модели. 5. СУБД запрашивает информацию о местоположении данных га физическом уровне (файлы и физические адреса).. 6. В СУБД возвращается информация о местоположении данных в терминах операционной системы. 7. СУБД «просит» ОС предоставить необходимые данные, используя средства ОС. 8. ОС оповещает СУБД об окончании пересылки. 9. СУБД выбирает из доставленной информации, находящейся в системном буфере, только то, что нужно пользователю, и пересылает эти данные в рабочую область пользователя. Лекция 4. Модели данных. Структура данных, основные операции над данными. Выбор модели данных. Реляционная модель данных: Модели данных. Одними из основополагающих в концепции баз данных являются обобщенные категории «данные» и «модель данных». Понятие «данные» в концепции баз данных — это набор конкретных значений, параметров, характеризующих объект, условие, ситуацию или любые другие факторы. Примеры данных: Петров Николай Степанович, $30 и т. д. Данные не обладают определенной структурой, данные становятся информацией тогда, когда пользователь задает им определенную структуру, то есть осознает их смысловое содержание. Поэтому центральным понятием в области баз данных является понятие модели. Не существует однозначного определения этого термина, у разных авторов эта абстракция определяется с некоторыми различиями, но тем не менее можно выделить нечто общее в этих определениях. Модель данных — это некоторая абстракция, которая, будучи приложима к конкретным данным, позволяет пользователям и разработчикам трактовать их уже как информацию, то есть сведения, содержащие не только данные, но и взаимосвязь между ними. Хранимые в базе данные имеют определенную логическую структуру – иными словами, описываются некоторой моделью представления данных или моделью данных, поддерживаемой СУБД. В соответствии с рассмотренной ранее трехуровневой архитектурой мы сталкиваемся с понятием модели данных по отношению к каждому уровню. И действительно, физическая модель данных оперирует категориями, касающимися организации внешней памяти и структур хранения, используемых в данной операционной среде. В настоящий момент в качестве физических моделей используются различные методы размещения данных, основанные на файловых структурах: это организация файлов прямого и последовательного доступа, индексных файлов и инвертированных файлов, файлов, использующих различные методы хэширования, взаимосвязанных файлов. Кроме того, современные СУБД широко используют страничную организацию данных. Физические модели данных, основанные на страничной организации, являются наиболее перспективными. Наибольший интерес вызывают модели данных, используемые на концептуальном уровне. По отношению к ним внешние модели называются подсхемами и используют те же абстрактные категории, что и концептуальные модели данных.
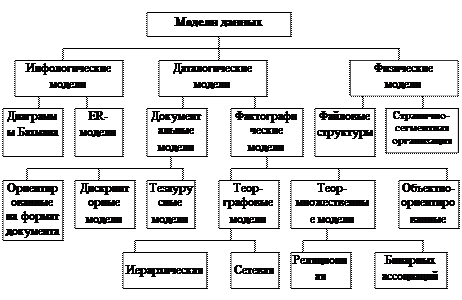
Рисунок 4.1- Классификация моделей данных Кроме трех рассмотренных уровней абстракции при проектировании БД существует еще один уровень, предшествующий им. Модель этого уровня должна выражать информацию о предметной области в виде, независимом от используемой СУБД. Эти модели называются инфологическими, или семантическими, и отражают в естественной и удобной для разработчиков и других пользователей форме информационно-логический уровень абстрагирования, связанный с фиксацией и описанием объектов предметной области, их свойств и их взаимосвязей. Инфологические модели данных используются на ранних стадиях проектирования для описания структур данных в процессе разработки приложения, а дата-логические модели уже поддерживаются конкретной СУБД. Документальные модели данных соответствуют представлению о слабоструктурированной информации, ориентированной в основном на свободные форматы документов, текстов на естественном языке. Модели, основанные на языках разметки документов, связаны прежде всего со стандартным общим языком разметки — SGML (Standart Generalised Markup Language), который был утвержден ISO в качестве стандарта еще в 80-х годах. Этот язык предназначен для создания других языков разметки, он определяет допустимый набор тегов (ссылок), их атрибуты и внутреннюю структуру документа. Контроль за правильностью использования тегов осуществляется при помощи специального набора правил, называемых DTD-описаниями, которые используются программой клиента при разборе документа. Для каждого класса документов определяется свой набор правил, описывающих грамматику соответствующего языка разметки. С помощью SGML можно описывать структурированные данные, организовывать информацию, содержащуюся в документах, представлять эту информацию в некотором стандартизованном формате. Но ввиду некоторой своей сложности SGML использовался в основном для описания синтаксиса других языков (наиболее известным из которых является HTML), и немногие приложения работали с SGML-документами напрямую. Гораздо более простой и удобный, чем SGML, язык HTML позволяет определять оформление элементов документа и имеет некий ограниченный набор инструкций — тегов, при помощи которых осуществляется процесс разметки. Инструкции HTML в первую очередь предназначены для управления процессом вывода содержимого документа на экране программы-клиента и определяют этим самым способ представления документа, но не его структуру. В качестве элемента гипертекстовой базы данных, описываемой HTML, используется текстовый файл, который может легко передаваться по сети с использованием протокола HTTP. Эта особенность, а также то, что HTML является открытым стандартом и огромное количество пользователей имеет возможность применять возможности этого языка для оформления своих документов, безусловно, повлияли на рост популярности HTML и сделали его сегодня главным механизмом представления информации в Интернете. Однако HTML сегодня уже не удовлетворяет в полной мере требованиям, предъявляемым современными разработчиками к языкам подобного рода. И ему на смену был предложен новый язык гипертекстовой разметки, мощный, гибкий и, одновременно с этим, удобный язык XML. В чем же заключаются его достоинства? XML (Extensible Markup Language) — это язык разметки, описывающий целый класс объектов данных, называемых XML-документами. Он используется в качестве средства для описания грамматики других языков и контроля за правильностью составления документов. То есть сам по себе XML не содержит никаких тегов, предназначенных для разметки, он просто определяет порядок их создания. Тезаурусные модели основаны на принципе организации словарей, содержат определенные языковые конструкции и принципы их взаимодействия в заданной грамматике. Эти модели эффективно используются в системах-переводчиках, особенно многоязыковых переводчиках. Принцип хранения информации в этих системах и подчиняется тезаурусным моделям. Дескрипторные модели — самые простые из документальных моделей, они широко использовались на ранних стадиях использования документальных баз данных. В этих моделях каждому документу соответствовал дескриптор — описатель. Этот дескриптор имел жесткую структуру и описывал документ в соответствии с теми характеристиками, которые требуются для работы с документами в разрабатываемой документальной БД. Например, для БД, содержащей описание патентов, дескриптор содержал название области, к которой относился патент, номер патента, дату выдачи патента и еще ряд ключевых параметров, которые заполнялись для каждого патента. Обработка информации в таких базах данных велась исключительно по дескрипторам, то есть по тем параметрам, которые характеризовали патент, а не по самому тексту патента.
|

 уровень
уровень