ДИСКРИМИНАНТНЫЙ АНАЛИЗ
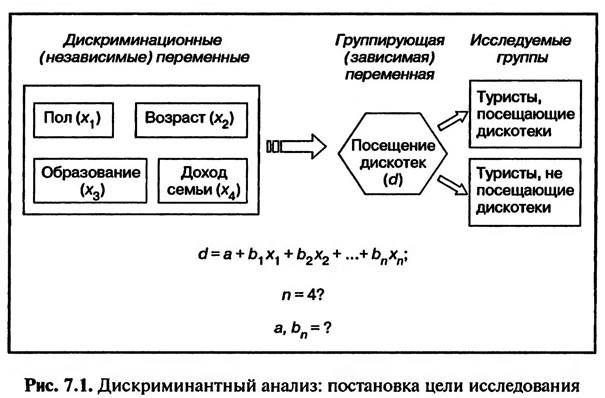
7.1. ПОСТАНОВКА ЦЕЛИ ИССЛЕДОВАНИЯ И ПРЕДСТАВЛЕНИЕ ИСХОДНЫХ ДАННЫХ В SPSS Дискриминантный анализ — анализ различий заранее заданных групп объектов исследования (потребителей, товаров, брендов и т.п.). Переменная, разделяющая совокупность объектов исследования на группы, называется группирующей. С помощью дискриминантного анализа изучаются различия между двумя или более группами по определенным признакам. Признаки, используемые для выявления различий между группами, называются дискриминационными переменными. С точки зрения теории статистики группирующая переменная должна быть номинальной, т.е. измеряться по номинальной шкале, а зависимые переменные — метрическими (см. подраздел 2.3 «Типы шкал измерения переменных»). Соблюдение этого условия обеспечивает высокую точность статистических расчетов. Однако на практике при использовании SPSS допускается, что группирующая переменная может быть номинааьной или порядковой, а дискриминационные переменные могут измеряться по шкале любого типа. Результатом дискриминантного анализа является построение дискриминантной модели (дискриминантной функции), которая имеег вид
где d — группирующая (зависимая) переменная; bп — коэффициенты дискриминантной функции; а — свободный член (константа); хп — дискриминационные (независимые) переменные. С помощью этой модели, зная харакгеристики объекта исследования, можно с определенной степенью уверенности определить его принадлежность к одной из исследованных групп. Например, требуется построить дискриминантную модель, при помощи которой на основании социально-демографических признаков (пол, возраст, образование, доход семьи) можно было бы причислить туриста к одной из двух групп: посещающих и не посещающих дискотеки (рис. 7.1).
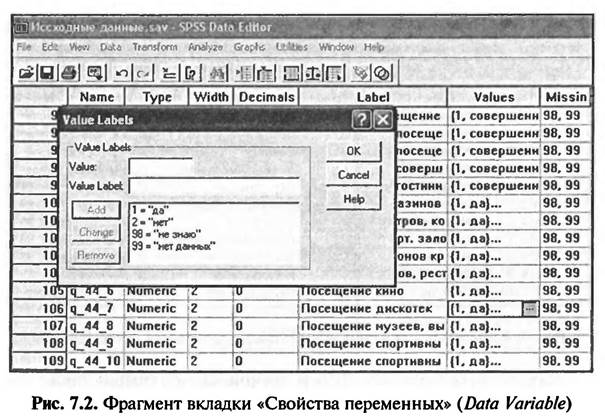
Для того чтобы построить дискриминантную модель, следует сначала выяснить, все ли выбранные дискриминационные переменные в действительности служат отличительными признаками исследуемых групп (п = 4?). Только после этого можно построить дискриминантную модель (я, Ьп). В нашем примере для дискриминантного анализа используются данные, собранные в результате опроса туристов, отдыхающих в курортной зоне «Баварский лес». Информация по группирующей переменной формируется из ответов респондентов на вопрос анкеты № 4: «Какие заведения/ мероприятия Вы часто посещаете во время отдыха?» В качестве ответа на этот вопрос респондентам предлагается выбрать один или несколько вариантов из 11 предложенных ответов. В качестве ответа № 7 предлагается вариант «дискотеки». При занесении в файл данных SPSS ответов на многовариантные вопросы создается несколько дихотомических переменных (см. раздел 2.2 «Виды кодировки данных»). В рассматриваемом примере вопрос анкеты № 44 представлен в файле данных SPSS в виде семи переменных (рис. 7.2).
В рассматриваемом примере дискриминантного анализа в качестве группирующей переменной используется переменная с именем «q_44_7» и меткой «Посещение дискотек». Метка этой переменной имеет два значения: «1» — «да» и «2» — «нет», которые разделяют опрашиваемых туристов на две группы: посещающие и не посещающие дискотеки. Ответы респондентов, которые затруднились или не захотели отвечать на этот вопрос («98», «99»), не участвуют в исследовании, о чем есть пометка в столбце «Missing». В качестве дискриминационных переменных в рассматриваемом примере используются социально-демографические признаки туристов: пол, возраст, образование и доход семьи (рис. 7.3). Переменная с именем «s_J» и меткой «Пол» имеет всего два значения («1» — «мужчины», «2» — женщины), т.е. она является дихотомической. Переменная с именем «s_2a» и меткой «Возраст» является метрической переменной. Ответы на соответствующий вопрос анкеты выражаются в числах, поэтому числовые коды значений метки переменной отсутствуют, о чем говорит отметка «None» в столбце «Values». Переменная с именем «s_4» и меткой «Образование» является порядковой переменной. Значения меток этой переменной относятся к 7 категориям, соответствующим уровням иерархии системы образования в Германии.
Переменная с именем «s_9» и меткой «Доход семьи» также является порядковой. Значения этой переменной представлены 9 категориями туристов по уровню дохода семьи: «1» — «до 500 евро», «2» — «от 500 до 900 евро», «3» — «от 900 до 1250 евро», «4» — «от 1250 до 1800 евро»... «9» — «свыше 3800 евро» в неделю. Как отмечалось выше, не все из выбранных дискриминационных переменных в действительности могут выступать в качестве отличительных признаков исследуемых групп. Если они таковыми не являются, они должны быть исключены из дискриминантной модели. В целом при выполнении дискриминантного анализа решаются следующие задачи: • Оценивается выбор дискриминационных переменных. • Строится дискриминантная модель. • Оценивается точность прогнозов на основе построенной дискриминантной модели. 7.2. КОМАНДЫ SPSS НА ВЫПОЛНЕНИЕ ДИСКРИМИНАНТНОГО АНАЛИЗА Дискриминантный анализ, как и кластерный, относится к классификационным видам анализа. Для задания процедуры его выполнения в меню методов анализа, предлагаемых пакетом SPSS, следует выбрать группу методов «Classify», которая имеет собственное меню, включающее некоторые виды кластерного анализа и дискриминантный анализ (рис. 7.4).
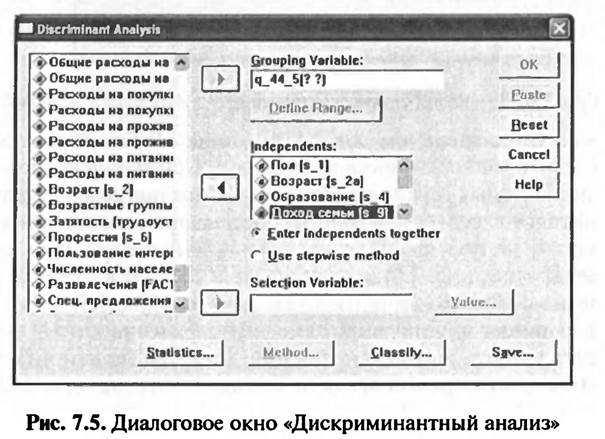
При выборе меню «Analyze > Classify > Discriminant» открывается диалоговое окно «Дискриминантный анализ», в котором формируется задание на выполнение дискриминантного анализа (рис. 7.5).
В левом поле диалогового окна «Дискриминантный анализ» находится список меток всех переменных, занесенных в исходный файл данных. Из этого списка следует выбрать метки независимых переменных дискриминантной модели и при помощи кнопки со стрелкой поочередно перенести их в правое поле окна «Independents». В рассматриваемом примере это метки переменных: «Пол», «Возраст», «Образование» и «Доход семьи». Затем из списка всех меток переменных в левом поле диалогового окна «Дискриминантный анализ» следует выбрать метку группирующей переменной и при помощи кнопки со стрелкой перенести ее в правое поле «Group ng Variable». В рассматриваемом примере это метка переменной «Посещение дискотек». После осуществления переноса метки группирующей переменной в поле «Grouping Variable» в этом поле появляется имя группирующей переменной («q_44_ 5») и активизируется кнопка «Define Range» («Определить область»). При нажатии этой кнопки открывается одноименное вспомогательное диалоговое окно (рис. 7.6).
Во вспомогательном диалоговом окне «Define Range» следует определить минимальное и максимальное значения числовых кодов исследуемых групп. В рассматриваемом примере исследуемых групп только две: «1» — «туристы, посещающие дискотеки» и «2» — «туристы, не посещающие дискотеки». После нажатия кнопки «Continue» (см. рис. 7.6) осуществляется возврат в главное диалоговое окно «Дискриминантный анализ» (см. рис. 7.5). В главном диалоговом окне «Дискриминантный анализ» следует указать метод построения дискриминантной модели. Возможен выбор пошагового метода («Use stepwise method») (см. рис. 7.5), который предполагает поэтапное включение независимых переменных в дискриминантную модель. В результате применения этого метода создается несколько дискриминантных моделей по количеству независимых переменных. В рассматриваемом примере выбран метод «Enter independents together» (см. рис. 7.5). Этот метод предполагает одновременное включение в дискриминантную модель всех заданных независимых переменных. При нажатии кнопки «Statistics» в главном диалоговом окне «Дискриминантный анализ» открывается вспомогательное диалоговое окно «Статистические показатели» (рис. 7.7).
В диалоговом окне «Статистические показатели» можно задать команды на расчет различных статистических показателей в процессе выполнения процедуры дискриминантного анализа. В рассматриваемом примере в поле «Descriptives» («Описательные статистические методы») поставлены отметки напротив команд «Means» и «Univariate A NOVAs». В результате выполнения команды «Means» рассчитываются средние значения дискриминационных переменных для каждой исследуемой группы. Результаты выполнения этой команды будут представлены далее (см. табл. 7.2). В результате выполнения команды «Univariate ANOVAs» («Одномерные тесты ANOVA») производится тест на равенство средних значений дискриминационных переменных в исследуемых группах (см. подраздел 3 «Сравнение средних величин в SPSS»). Результаты выполнения этой команды будут представлены далее (см. табл. 7.2 и 7.3). В рассматриваемом примере в поле «Matrices»(«Таблицы») диалогового окна «Статистические показатели» поставлена отметка напротив команды «Withi i-groups corretauon» (см. рис. 7.7). В результате выполнения этой команды на экран компьютера выводится таблица «Объединенные матрицы внутри групп», содержащая данные о корреляционных связях между дискриминационными переменными (см. далее табл. 7.5). Также в рассматриваемом примере в поле «Function Coefficients» диалогового окна «Статистические показатели» поставлена отметка напротив команды «Unstandardized» (см. рис. 7.7). Это означает, что при построении дискриминантной функции будут использованы нестандартизированные коэффициенты. Значения нестандарт!жированных коэффициентов дискриминантной функции в рассматриваемом примере будут представлены далее (см. табл. 7.10). При нажатии кнопки «Continue» в диалоговом окне «Статистические показатели» данное окно закрывается и осуществляется возврат в главное диалоговое окно «Дискриминантный анализ» (см. рис. 7.5). При нажатии кнопки «Classify» е главном диалоговом окне «Дискриминантный анализ» открывается вспомогательное диалоговое окно «Классификация» (рис. 7.8).
В диалоговом окне «Классификация» задаются условия и форма представления классификации объектов исследования, т.е. распределения их по группам. В рассматриваемом примере речь идет о разделении туристов на две группы: «посещающие дискотеки» и «не посещающие дискотеки». В поле «Plots» («Графики») диалогового окна «Классификация» можно задать построение графиков, иллюстрирующих результаты классификации. В рассматриваемом примере поставлена отметка напротив команды «Separate-groups» («Разделенные группы») (см. рис. 7.8). В результате выполнения этой команды на экран выводятся графики распределения дискриминантной функции для каждой исследуемой группы. Результаты выполнения этой команды будут представлены далее (см. табл. 7.9 и 7.10). В поле «Display» диалогового окна «Классификация» задается форма представления результатов классификации. В рассматриваемом примере отмечена команда «Casewise results» («Результаты отдельно по каждому наблюдению»). Таким образом, на экран выводятся результаты классификации отдельно по каждому респонденту, а именно к какой группе и с какой вероятностью он может быть причислен исходя из значения дискриминантной функции. Следует ограничить число респондентов, по которым представляются результаты классификации. Это можно сделать при помощи команды «Lim teases to first...» («Ограничить наблюдения по первым...»). В нашем примере задано ограничение по первым 20 респондентам (см. рис. 7.8). Результаты классификации по первым 20 респондентам будут представлены далее (см. табл. 7.12). В поле «Display» диалогового окна «Классификация» также поставлена отметка напротив команды «Summary table» («Сводная таблица»). В результате выполнения этой команды на экран компьютера выводится сводная таблица результатов классификации (см. далее табл. 7.13). При нажатии кнопки «Continue» в диалоговом окне «Классификация» данное окно закрывается и осуществляется возврат в главное диалоговое окно «Дискриминантный анализ» (см. рис. 7.5). При нажатии кнопки «Save» («Сохранить») в диалоговом окне «Дискриминантный анализ» открывается одноименное вспомогательное диалоговое окно, в котором можно задать команды на сохранение результатов дискриминантного анализа в виде новых переменных в исходном файле данных, В рассматриваемом примере такие операции не производятся. Запуск процедуры выполнения дискриминантного анализа осуществляется путем нажатия кнопки «ОК» в главном диалоговом окне «Дискриминантный анализ». 7.3. ОЦЕНКА ВЫБОРА ДИСКРИМИНАЦИОННЫХ ПЕРЕМЕННЫХ Оценка выбора дискриминационных переменных представляет собой первый этап интерпретации результатов дискриминантного анализа. Представление результатов анализа начинается с обзора действительных и пропущенных значений, который выводится на экран компьютера в виде таблицы «Анализ обработанных наблюдений» (табл. 7.1).
В нашем примере число респондентов, принявших участие в опросе (Total), составляет 6396; из этих данных только 1023 анкеты являются действительными (Valid), т.е. только эти наблюдения используются при расчетах для построения дискриминантной функции. Данные по остальным респондентам исключены из анализа (Excluded) в виду отсутствия данных по ответам на нужные вопросы. Число респондентов, не давших информации о том, посещают л и они дискотеки, составляет 4711. Как отмечалось ранее при построении дискриминантной функции, данные по этим респондентам не используются. Однако эти респонденты участвуют в классификации на основании построенной дискриминантной модели (см. далее табл. 7.12 и 7.13). Число респондентов, не давших информацию о себе хотя бы по одному из нужных социально-демографических признаков, составляет 146. Число респондентов, не давших информации о том, посещают ли они дискотеки, и одновременно не давших информацию о себе хотя бы по одному из нужных социально-демо- графических признаков, составляет 516. После обзора действительных и пропущенных значений на экран компьютера выводится таблица «Статистические показатели в группах», которая содержит данные о средних значениях (Mean) дискриминационных переменных в каждой из исследуемых групп. Эти показатели дают общее представление о том, являются ли дискриминационные переменные отличительными признаками исследуемых групп (табл. 7.2). Таблица 7.2
|