Преобразованная структура исходного массива данных для проведения кластерного анализа
В табл. 6.2 вносятся оценки туристами степени, в какой они руководствуются теми или иными интересами при проведении времени на отдыхе. Данные оценки являются средними по каждой возрастной ipynne. Разделение возрастных групп на категории (например, от 25 до 29 лет) было произведено в целях сокращения числа объектов исследования. В проведении исследований участвовали туристы в возрасте от 17 до 70 лет. Если бы в качестве объектов исследования были взяты возрастные группы, объединяющие только туристов определенного возраста (например, 17 лет, 18 лет... 44 года и т.д.), то число объектов исследования составило бы 63 (70 - 17). Лкое большое число объектов исследования существенно затрудняет интерпретацию результатов кластерного анализа. Разделение возрастных групп на категории привело к сокращению числа объектов исследования (возрастных групп туристов) с 63 до 11. Иллюстрация постановки цели кластерного анализа в нашем примере представлена на рис. 6.1. Для проведения кластерного анализа в SPSS создается новый файл данных (рис. 6.2 и 6.3).
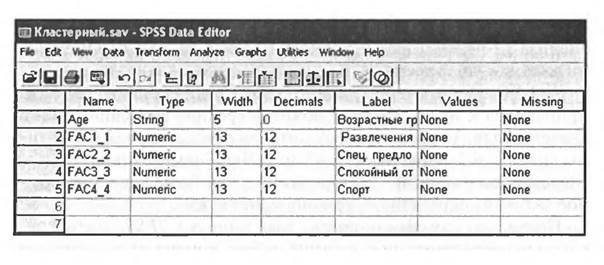
На рис. 6.2 представлен фрагмент исходного файла данных, состоящего из 5 переменных. Первая переменная с именем «Age» и меткой «Возрастные группы» является текстовой переменной, об этом есть соответствующая запись (String) в столбце «Туре». Со значениями этой переменной нельзя будет производить никаких арифметических операций.
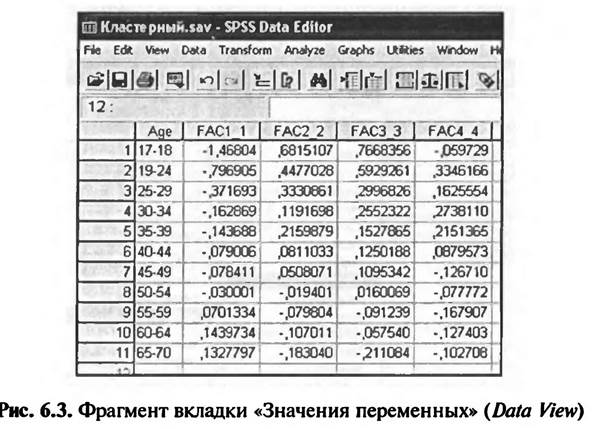
Четыре переменные с именами «FAC1_1», «FAC2_1», «FAC3 J» и «FAC4_1» являются компонентами факторной модели, построенной в результате проведения факторного анализа (см. предыдущий раздел). Значения этих переменных представляют собой усредненные балльные оценки важности для турисюв каждой возрастной группы следующих интересов: «Развлечения», «Специальные предложения Восточной Баварии», «Спокойный отдых» и «Спорт» (рис. 6,3).
Как было описано в предыдущем подразделе, при проведении опроса респондентам предла1алось оценить 12 мотивов проведения времени на отдыхе по 5-балльной шкале («1» — «очень важно» и «5» — «совсем не важно»). В результате проведения факторного анализа 12 переменных исходного массива данных были сгруппированы в 4 переменные, в ходе проведения анализа произошла трансформация значений переменных. Средняя оценка (3) была приравнена к нулю. Именно поэтому средние значения оценки значения для туристов четырех мотивов поведения, представленные на рис. 6.3, варьируют от -2 до 2. Чем больше отрицательное значение переменной, тем она важнее; чем больше положительное значение переменной, тем она менее важна. После того как сформирована база данных в SPSS, следует перейти непосредственно к заданию набора команд на выполнение кластерного анализа. 6.2. КОМАНДЫ SPSS НА ВЫПОЛНЕНИЕ ИЕРАРХИЧЕСКОГО КЛАСТЕРНОГО АНАЛИЗА Кластерный анализ является одним из видов классификационного анализа. Для задания команд на выполнение кластерного анализа в SPSS в меню различных видов анализа (Analyze) следует выбрать «Классификационный аиапиз» (Class fy) (рис. 6.4).
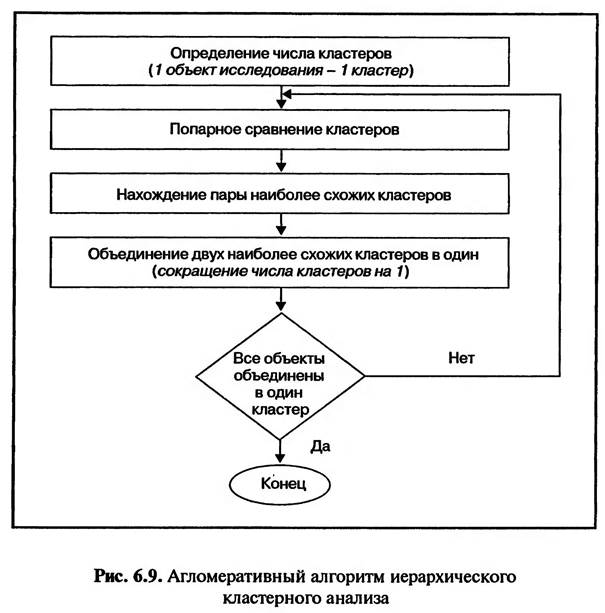
«Классификационный анализ», в свою очередь, имеет собственное меню, содержащее различные виды классификационного анализа, в том числе три вида кластерного анализа. В рассматриваемом примере применяется иерархический кластерный анализ, наиболее часто применяемый на практике. Иерархический кластерный анализ отличается от других видов кластерного анализа тем, что алгоритм его проведения является многоступенчатым. Алгоритм иерархического кластерного анализа может быть дивизионным или агломеративным. Дивизионный алгоритм проведения иерархического кластерного анализа предполагает, что все объекты исследования в начале объединены в один кластер, который поэтапно делится на более мелкие кластеры. Агломеративный алгоритм, напротив, предполагает, что все объекты исследования вначале рассматриваются как мелкие кластеры, которые затем объединяются в более крупные. На практике чаще всего используются агломеративные методы формирования кластеров. В результате выбора меню «Analyze> Classify> Hierarchical Cluster» на экране появится диалоговое окно «Иерархический кластерный анализ» (Нierarchical Cluster Analyze) (рис. 6.5).
В левом поле открывшегося диалогового окна «Иерархический кластерный анализ» представлен список пяти переменных исходного массива данных. Из них следует выбрать переменные, по которым будет производиться формирование кластеров, и перенести их в правое поле «Variable(s)». В рассматриваемом примере — это переменные, характеризующие интересы (мотивы поведения) туристов: «Развлечения», «Специальные предложения Восточной Баварии», «Спокойный отдых» и «Спорт». Также из списка всех переменных исходной базы данных следует выбрать переменную, значения которой являются объектами исследования, и перенести ее в правое поле «Label Cases by». В рассматриваемом примере это переменная «возрастные группы». В поле «Cluster» следует выбрать один из двух предлагаемых вариантов: «Cases» или «Variables» (см. рис. 6.5). В нашем примере выбран вариант «Cases». Это означает, что в ходе кластерного анализа будут классифицироваться (собираться в кластеры) возрастные группы туристов, а не их интересы (мотивы поведения). В диалоговом окне «Иерархический кластерный анализ» также есть четыре кнопки, нажав которые открываются вспомогательные диалоговые окна:«Statistics», «Plots», «Method» и «Save». При нажатии кнопки «Statistics» на экране появляется одноименное диалоговое окно «Статистические показатели» (рис. 6.6).
Во вспомогательном диалоговом окне «Статистические показатели» отмечены команды «Agglomeration schedule» и «Proximity matrix» (см. рис. 6.6). После запуска процедуры выполнения кластерного анализа данные команды позволяют вывести на экран в качестве результатов анализа таблицу, содержащую результаты сравнения объектов исследования (Proximity matrix), и таблицу, отображающую алгоритм формирования кластеров (Agglomeration schedule). Путем нажатия кнопки «Сопи те» осуществляется возврат в главное диалоговое окно «Иерархический кластерный анализ». После нажатия кнопки «Plots» в главном диалоговом окне «Иерархический кластерный анализ» на экране появляется одноименное вспомогательное диалоговое окно «Диаграммы» (рис. 6.7).
В диалоговом окне «Диаграммы» представлены команды на построение различных графиков и диаграмм, описывающих процедуру формирования кластеров. В данном диалоговом окне отмечена команда «Dendogram». После запуска процедуры выполнения кластерного анализа данная команда выводит на экран дендограмму, которая является графическим отображением выполнения алгоритма формирования кластеров. Путем нажатия кнопки «Continue» (см. рис. 6.7) осуществляется возврат в главное диалоговое окно «Иерархический кластерный анализ» (см. рис. 6.5). При нажатии кнопки «Method» в главном диалоговом окне «Иерархический кластерный анализ» (см. рис. 6.5) на экране появляется одноименное вспомогательное диалоговое окно «Методы» (рис. 6.8).
В поле «Cluster Method» вспомогательного диалогового окна «Методы» из списка, предлагаемого SPSS, следует выбрать метод формирования кластеров. В рассматриваемом примере выбран метод «Ward». В поле «Measure» из списка возможных вариантов следует выбрать показатель, который будет использоваться в целях определения степени схожести (различия) объектов исследования. Выбор этого показателя зависит от типа переменных, участвующих в кластерном анализе в качестве критериев сегментации. Данные переменные могут быть интервальными (Interval), номинальными (Counts) или дихотомическими (Binary). В рассматриваемом примере переменные, по которым совокупность объектов исследования разделяется на кластеры, являются интервальными, поскольку респонденты в ходе опроса да- оали балльные оценки значимости для них различных мотивов проведения времени на отдыхе. Поэтому в поле «Measure» диалогового окна «Method» отмечается тип переменной «Interval». В качестве показателя, характеризующего степень схожести (различия) объектов исследования, выбирается квадрат евклидова расстояния (,Squared EucL iean Distance). Путем нажатия кнопки «Continue» в диалоговом окне «Method» осуществляется возврат в главное диалоговое окно «Иерархический кластерный анализ» (см. рис. 6.5). В диалоговом окне «Иерархический кластерный анализ» имеется кнопка «Save», при нажатии которой активизируется одноименное диалоговое окне. В этом окне представлены команды, позволяющие сохранить результаты кластерного анализа как новые переменные в исходной базе данных. В результате выполнения этих команд после запуска процедуры выполнения кластерного анализа создается новая переменная, значения которой представляют собой номера кластеров, к которым относится тот или иной объект исследования. Запуск процедуры выполнения иерархического кластерного анализа осуществляется путем нажатия кнопки «ОК» в главном диалоговом окне «Иерархический кластерный анализ» (см. рис. 6.5). 6.3. СРАВНЕНИЕ ОБЪЕКТОВ ИССЛЕДОВАНИЯ Среди данных, выдаваемых SPSS в качестве результатов кластерного анализа, в первую очередь на экран выводится таблица, содержащая результаты сравнения объектов исследования. Первоочередность представления этих данных в качестве результатов обусловливается агломерат ивным алгоритмом иерархического кластерного анализа (рис. 6.9). В нашем примере в качестве показателя, характеризующего степень сходства (различия) объектов исследования, был выбран квадрат евклидова расстояния (<Squared Euclidean Distance) (см. рис. 6.8). Чем меньше этот показатель, тем больше сходство сравниваемой пары объектов исследования (табл. 6.3).
Данные табл. 6.3 показывают, в какой степени схожи (различны) между собой разные возрастные категории туристов по структуре их интересов (мотивов проведения времени на отдыхе). Наиболее схожими относительно структуры их интересов являются возрастные категории туристов «9» (55—59 лет) и «10» (60—64 года). Квадрат евклидова расстояния между этими группами составляет всего 0,009 и является минимальным из всех прочих значений этого показателя. Следовательно, данные возрастные категории туристов должны быть объединены в один кластер. Для определения очередности последующего объединения объектов исследования в кластеры необходимо заново определить квадрат евклидова расстояния между вновь созданным кластером и прочими кластерами.
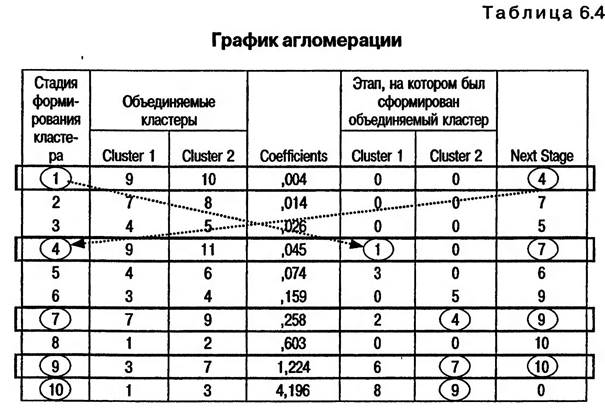
Результаты расчета квадратов евклидова расстояния для каждого этапа формирования кластеров не выводятся на экран компьютера. Среди данных, выводимых на экран в качестве результатов кластерного анализа, предоставляются лишь результаты сравнения кластеров на этапе, когда каждый объект исследования рассматривается как кластер. Данные табл. 6.3 не предоставляют сведений об очередности формирования кластеров. Она дает лишь общее представление о сходстве (различии) объектов исследования. По данным этой таблицы можно сделать лишь приблизительные выводы о том, какие из объектов исследования окажутся объединенными в один кластер. 6.4. ПОРЯДОК ФОРМИРОВАНИЯ КЛАСТЕРОВ В качестве результатов проведения кластерного анализа в SPSS после таблицы с результатами сравнения объектов исследования на экран выводится таблица «График агломерации» (Agglomerati ж Schedule) (табл. 6.4).
аблнца 6.4 «График агломерации» описывает порядок построения кластеров. В столбце «Stage» указываются номера строк. Каждая строка представляет собой этап (шаг) процесса формирования кластеров. Последняя строка таблицы «График агломерации» описывает последний этап этого процесса, когда все объекты исследования объединяются в один кластер. Число строк в таблице «График агломерации» всегда на единицу меньше числа объектов исследования. В рассматриваемом примере объектами исследования являются 11 возрастных категорий туристов, и число шагов их поэтапного объединения в один кластер составляет 10. В столбце «Cluster Combined» указывается, какие именно кластеры объединяются в один на очередном этапе формирования кластеров. В столбце «Coefficients» указываются значения того показателя, на основании которого устанавливается очередность поэтапного объединения объектов исследования в один кластер. То, какой именно показатель используется для этих целей, зависит от выбранного метода формирования кластеров. В нашем примере был выбран метод «Ward». Основной принцип метода «Ward» заключается в том, что в первую очередь должны объединяться те кластеры, объединение которых в наименьшей степени способствует увеличению гетерогенности (разнородности) внутри формируемых кластеров. В столбце «Coefficients» указываются значения коэффициента, характеризующего степень гетерогенности (разнородности) формируемых кластеров. На начальном (нулевом) этапе формирования кластеров, когда каждый объект исследования рассматривается как кластер, все кластеры являются абсолютно гомогенными (однородными). Коэффициент, характеризующий степень их гетерогенности, равен нулю. Гетерогенность кластеров повышается по мере их объединения в более крупные. На первом этапе при объединении кластеров «9» и «10» гетерогенность вновь созданного кластера характеризуется значением коэффициента 0,004 (см. рис. 6.10). На последнем (десятом) этапе при объединении всех объектов исследования в один кластер гетерогенность созданного кластера характеризуется значением коэффициента 4,196. Применение метода «Ward» обеспечивает минимально возможное увеличение степени гетерогенности формируемых кластеров в процессе объединения мелких кластеров в более крупные. В столбце «Next Stage» указывается номер этапа формирования кластеров, когда ноьый кластер будет объединяться с другими. Например, на первом этапе при объединении кластеров «9» и «10» создается новый кластер, ему присваивается номер «9». Созданный кластер «9» будет объединяться с кластером «11» на четвертом этапе формирования кластеров, о чем есть соответствующая отметка в столбце «Next Stage» (см. табл. 6.4). В столбце «Stage Cluster First Appears» указываются этапы (строки), на которых были сформированы объединяемые кластеры. Например, при объединении кластеров «9» и «11» указывается, что кластер «9» был сформирован на первом, а кластер «11» — на нулевом этапе формирования кластеров. Таким образом, таблица «График агломерации» достаточно подробно описывает очередность формирования кластеров, начиная с нулевой стадии, когда каждый объект исследования рассматривается как кластер, и заканчивая созданием кластера, объединяющего все объекты исследования. 6.5. ОПРЕДЕЛЕНИЕ ОПТИМАЛЬНОГО КОЛИЧЕСТВА ФОРМИРУЕМЫХ КЛАСТЕРОВ Компьютерная программа SPSS не дает ответа на вопрос, какое число формируемых кластеров является оптимальным. Это должны решать специалисты, проводящие исследование. При решении этой задачи необходимо учитывать два аспекта: 1. В процессе формирования кластеров их число становится все меньше, а количество объектов исследования, входящих в один кластер, — все больше. 2. С увеличением числа объектов, объединяемых в один кластер, растет гетерогенносгь формируемого кластера. Оптимальным является такое число кластеров, при котором сформированные кластеры: • с одной стороны, объединяют в себе как можно больше объектов исследования; • с другой стороны, являются возможно менее гетерогенными внутри. Решение относительно оптимального числа формируемых кластеров принимается на основании данных таблицы «График агломерации». Для определения оптимального числа формируемых кластеров используется критерий «Ellbow»: строится график зависимости числа формируемых кластеров и значений коэффициента, характеризующего степень их гетерогенности (рис. 6.10).
Из данных на графике, представленном на рис. 6.10, видно, что при сокращении числа кластеров с 3 до 2 происходит резкое увеличение гетерогенности кластеров (с 0,603 до 1.224). Из этого следует, что 3 является оптимальным числом кластеров, т.е. в результате проведения кластерного анализа объекты исследования должны быть объединены в три кластера. Именно такое решение обеспечит создание сравнительно однородных кластеров, объединяющих достаточно большое число объектов исследования. 6.6. ИНТЕРПРЕТАЦИЯ РЕЗУЛЬТАТОВ КЛАСТЕРНОГО АНАЛИЗА Результаты кластерного анализа нагляднее всего представляются в виде дендограммы (рис. 6.11).
Дендограмма является графическим изображением таблицы «График агломерации» (см. табл. 6.4). При построении дендограммы SPSS нормирует значения коэффициента, характеризующего степень гетерогенности формируемых кластеров, по шкале от нуля до 25. В рассматриваемом примере значению шкалы дендограммы 25 (см. рис. 6.11) соответствует значение коэффициента 4,196 в последней строке таблицы «График агломерации» (см. табл. 6.4). Дендограмма иллюстрирует увеличение разнородности кластеров по мере их укрупнения. Максимальное значение шкалы дендограммы 25 характеризует максимааьно возможную степень гетерогенности кластеров, когда все объекты исследования объеди-, нены в один кластер. Если объекты исследования разделить на два кластера: «17— 24 года» и «25—70 лет», то данные кластеры будут значительно более разнородны. Степень их разнородности по шкале дендограммы понизится примерно до 7. В качестве оптимального числа формируемых кластеров в рассматриваемом примере было определено число 3 (см. предыдущий раздел). Окончательным результатом кластерного анализа является разделение 11 возрастных групп туристов на три кластера: · кластер 1: туристы 17—24 лет; · кластер 2: туристы 25—44 лет; · кластер 3: туристы 45—70 лет. Как видно из дендограммы, кластеры «2» и «3», т.е. возрастные группы туристов «25—44 года» и «45—70 лег», являются более однородными по структуре интересов (мотивов проведения времени на отдыхе) по сравнению с возрастной группой «17—24 года» (см. рис. 6.11). После кластерного анализа можно проводить дополнительные исследования, в ходе которых оцениваются особенности выделенных кластеров. В нашем примере можно выяснить, какие именно интересы туристов (мотивы проведения времени на отдыхе) являются наиболее важными для каждого сформированного кластера. Также для выявления отличительных особенностей сформированных кластеров можно провести впоследствии дискриминант- ный анализ. С помощью дискриминантного анализа, например, можно выяснить, отличаются ли друг от друга туристы, оказавшиеся в разных кластерах, по каким-либо социально-демографическим признакам (кроме возраста, поскольку эта переменная лежит в основе формирования кластеров). КОНТРОЛЬНЫЕ ВОПРОСЫ 1. Какова цель проведения и возможности использования результатов кластерного анализа? 2. Какие требования предъявляются к переменным, участвующим в проведении кластерного анализа, относительно типов шкал измерения переменных? 3. Почему и в каких случаях при проведении кластерного анализа необходимо преобразование структуры исходного массива данных? 4. Чем отличается иерархический кластерный анализ от других видов кластерного анализа? 5. В чем состоит отличие между дивизионным и агломеративным алгоритмом иерархического кластерного анализа? 6. Для чего при использовании метода формирования кластеров «Ward» служит показатель «Квадрат евклидова расстояния» и как следует интерпретировать его значения? 7. Что представляет собой таблица «График агломерации», выводимая в SPSS результатов иерархического кластерного анализа?
8. Какие данные содержатся в столбцах «Stage», «Cluster Combined», «Coefficients» и «Мех/ Stage» этой таблицы? 9. Какие ориентиры существуют для определения оптимального количества формируемых кластеров, что представляет собой критерий «EHbow»? 10. Что представляет собой дендо1рамма, выводимая в SPSS на экран компьютера среди результатов кластерного анализа?
|