Концепция ТСР/IP.
Очень показательная картинка. Красным цветом на ней показаны должники, а черным - кредиторы. Помните из книжек истории как происходило в средние века? Бароны (или даже целые государства) набирали огромное количество денег в долг, а когда подбиралось время расчетов, шли войной на кредитора. Концепция ТСР/IP. TCP/IP – набор средств низкого уровня, которые обеспечивают передачу данных между компьютерами через Интернет. Сервисы Интернет и прикладные программы, которые изучаются в настоящем курсе, пользуются TCP/IP для взаимодействия между собой - аналогично как люди пользуются телефонной сетью. TCP/IP устроен в виде многоуровневой системы, где каждый уровень выполняет свою функцию по обеспечению передачи данных между компьютерами. Детали работы каждого уровня скрыты от других уровней; каждый уровень взаимодействует только со своими соседними уровнями сверху и снизу. TCP/IP - собирательное название для набора (стека) сетевых протоколов разных уровней, используемых в Интернет. Сетевые протоколы реализованы в виде программ (программных модулей), вызываемых в определенной последовательности (т.е. каждый протокол занимает определенный уровень по отношению к другим протоколам). Каждый протокол выполняет свою часть работы по передачи данных через сеть (например, обеспечивает проверку ошибок и подтверждение приема данных). Взаимоотношения между программами-протоколами соседних уровней осуществляются через стандартизованные программные интерфейсы. Для того, чтобы передать данные на другой компьютер, прикладной процесс (например, веб-браузер) передает эти данные протоколу верхнего уровня, который добавляет к ним свои служебные заголовки и вызывает протокол следующего уровня, далее процесс повторяется, пока не будет достигнут самый низший уровень. Протокол низшего уровня отвечает непосредственно за передачу данных в физической среде между соседними узлами маршрута. При получении данные проходят путь через стек TCP/IP в обратном порядке, пока не достигнут прикладного процесса-получателя. Особенности TCP/IP: · открытые стандарты протоколов, разрабатываемые независимо от программного и аппаратного обеспечения; · независимость от физической среды передачи; · система адресации, позволяющая уникально идентифицировать каждый компьютер в Интернет; · стандартизованные протоколы прикладного уровня, реализующие сервисы Интернет.
Рис. 1.1. Стек протоколов TCP/IP. Стек протоколов TCP/IP делится на 4 уровня: прикладной (application), транспортный (transport), межсетевой (internet) и уровень доступа к среде передачи (network access). Термины, используемые для обозначения блока передаваемых данных, различны при использовании разных протоколов транспортного уровня: TCP и UDP, поэтому на рисунке изображено два стека. При отправлении данные обрабатываются уровнями в последовательности сверху вниз (см. рис. 1.1) - от прикладного процесса к физической среде передачи данных; при получении - в обратном порядке: снизу вверх. Ниже рассматриваются функции каждого уровня и примеры протоколов. Network Access Layer (Уровень доступа к среде передачи) Функции: · отображение IP-адресов в физические адреса сети (MAC-адреса); · инкапсуляция IP-дейтаграмм (datagrams) в кадры (frames) для передачи по физическому каналу и передача кадров; На этом уровне работает протокол ARP, осуществляющий отображение адресов IP->MAC. Протокол поддерживает в оперативной памяти динамическую arp-таблицу в целях кэширования полученной информации. Порядок функционирования протокола следующий. С межсетевого уровня поступает IP-дейтаграмма для передачи в физический канал (например, Ethernet), вместе с дейтаграммой передается, среди прочих параметров, IP-адрес хоста назначения. Если в arp-таблице не содержится записи об Ethernet-адресе, соответствующем нужному IP-адресу, модуль arp ставит дейтаграмму в очередь и формирует запрос. Запрос (arp-request) представляет из себя Ethernet-кадр с широковещательным адресом, содержащий метку о том, что это arp-запрос, IP-адрес, подлежащий преобразованию, и пустое поле для искомого Ethernet-адреса. Запрос получают все хосты, подключенные к данной сети; хост, опознавший свой IP-адрес, заполняет пустующее поле значением своего Ethernet-адреса и отправляет arp-ответ (arp-response). Полученные данные заносятся в таблицу, ждущая дейтаграмма извлекается из очереди и передается на инкапсуляцию в кадр Ethernet для последующей отправки по физическому каналу. Internet Layer (Межсетевой уровень) и протокол IP Основным протоколом этого уровня является протокол IP (Internet Protocol). Функции IP: · определение дейтаграммы - основного блока передачи данных в Интернет; · определение схемы адресации в Интернет (рассматривается в следующем параграфе); · передвижение данных между транспортным уровнем и уровнем доступа к среде передачи; · маршрутизация дейтаграмм (обсуждается в параграфе 3); · фрагментация дейтаграмм на границе сред с различными размерами блока передаваемых данных и сборка фрагментированных дейтаграмм в месте назначения. Протокол IP доставляет данные от одного IP-адреса к другому. Заголовок дейтаграммы содержит IP-адреса отправителя и получателя и другую служебную информацию. Протокол IP является ненадежным протоколом без установки соединения. Это означает, что протокол IP не подтверждает доставку данных, не контролирует целостность полученных данных и не производит операцию квитирования (handshaking) - обмена служебными сообщениями, подтверждающими установку соединения с хостом назначения. IP-дейтаграмма запускается в сеть и ее дальнейшая судьба никак не контролируется узлом отправления (на уровне протокола IP). Если дейтаграмма не может быть доставлена, она уничтожается. Узел, уничтоживший дейтаграмму, отправляет по обратному адресу ICMP-сообщение о причине сбоя. Узлом в Интернет называется любой компьютер, имеющий IP-соединение с сетью. IP-адрес уникально идентифицирует в Интернет IP-интерфейс узла. Это значит, что узел, имеющий несколько IP-интерфейсов (например, маршрутизатор, подсоединенный сразу к нескольким сетям; или сервер, имеющий несколько сетевых карточек) имеет несколько IP-адресов. Часто узлы называются хостами. Формально, хостом называется узел, не являющийся маршрутизатором. Transport Layer (Транспортный уровень) Протоколы транспортного уровня обеспечивают прозрачную доставку данных (end-to-end delivery service) между двумя процессами. Процесс внутри хоста идентифицируется номером, который называется номером порта. Таким образом, роль адреса на транспортном уровне выполняет номер порта (или, проще, - порт). Совокупность IP-адреса и номера порта называется сокетом (socket). Как IP адрес уникально определяет в Интернет IP-интерфейс (хост), сокет уникально идентифицирует в Сети конкретный процесс. Например, сокет 194.84.124.4.25 состоит из IP-адреса хоста 194.84.124.4 и номера порта 25 и идентифицирует запущенный на хосте 194.84.124.4 демон электронной почты, который всегда использует порт 25. Этот и некоторые другие порты относятся к так называемым "широко известным сервисам", т.е. их номера закреплены за процессами, выполняющими определенные стандартные функции. Например, при обращении на порт номер 80 всегда устанавливается связь с сервером WWW (если таковой вообще запущен на вызываемом хосте). Список портов хорошо известных сервисов в паре с названием обслуживающего каждый сервис транспортного протокола находится в файле /etc/services. На транспортном уровне работают два основных протокола: UDP и TCP.
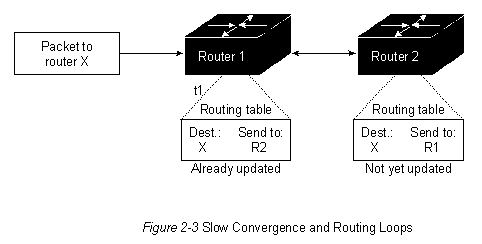
2. Цели разработки алгоритмов маршрутизации. Алгоритмы маршрутизации можно дифференцировать, основываясь на нескольких ключевых характеристиках. Во-первых, на работу результирующего протокола маршрутизации влияют конкретные задачи, которые решает разработчик алгоритма. Во-вторых, существуют различные типы алгоритмов маршрутизации, и каждый из них по-разному влияет на сеть и ресурсы маршрутизации. И наконец, алгоритмы маршрутизации используют разнообразные показатели, которые влияют на расчет оптимальных маршрутов. В следующих разделах анализируются эти атрибуты алгоритмов маршрутизации. Цели разработки алгоритмов маршрутизации При разработке алгоритмов маршрутизации часто преследуют одну или несколько из перечисленных ниже целей: 1. Оптимальность 2. Простота и низкие непроизводительные затраты 3. Живучесть и стабильность 4. Быстрая сходимость 5. Гибкость Оптимальность Оптимальность, вероятно, является самой общей целью разработки. Она характеризует способность алгоритма маршрутизации выбирать "наилучший" маршрут. Наилучший маршрут зависит от показателей и от "веса" этих показателей, используемых при проведении расчета. Например, алгоритм маршрутизации мог бы использовать несколько пересылок с определенной задержкой, но при расчете "вес" задержки может быть им оценен как очень значительный. Естественно, что протоколы маршрутизации должны строго определять свои алгоритмы расчета показателей. Простота и низкие непроизводительные затраты Алгоритмы маршрутизации разрабатываются как можно более простыми. Другими словами, алгоритм маршрутизации должен эффективно обеспечивать свои функциональные возможности, с мимимальными затратами программного обеспечения и коэффициентом использования. Особенно важна эффективность в том случае, когда программа, реализующая алгоритм маршрутизации, должна работать в компьютере с ограниченными физическими ресурсами. Живучесть и стабильность Алгоритмы маршрутизации должны обладать живучестью. Другими словми, они должны четко функционировать в случае неординарных или непредвиденных обстоятельств, таких как отказы аппаратуры, условия высокой нагрузки и некорректные реализации. Т.к. роутеры расположены в узловых точках сети, их отказ может вызвать значительные проблемы. Быстрая сходимость Алгоритмы маршрутизации должны быстро сходиться. Сходимость - это процесс соглашения между всеми роутерами по оптимальным маршрутам. Когда какое-нибудь событие в сети приводит к тому, что маршруты или отвергаются, или ставновятся доступными, роутеры рассылают сообщения об обновлении маршрутизации. Сообщения об обновлении маршрутизации пронизывают сети, стимулируя пересчет оптимальных маршрутов и, в конечном итоге, вынуждая все роутеры придти к соглашению по этим маршрутам. Алгоритмы мааршрутизации, которые сходятся медленно, могут привести к образованию петель маршрутизации или выходам из строя сети. На Рис. 2-3 изображена петля маршрутизации. В данном случае, в момент времени t1 к роутеру 1 прибывает пакет. Роутер 1 уже был обновлен и поэтому он знает, что оптимальный маршрут к пункту назначения требует, чтобы следующей остановкой был роутер 2. Поэтому роутер 1 пересылает пакет в роутер 2. Роутер 2 еще не был обновлен, поэтому он полагает, что следующей оптимальной пересылкой должен быть роутер 1.
Гибкость Алгоритмы маршрутизации должны быть также гибкими. Другими словами, алгоритмы маршрутизации должны быстро и точно адаптироваться к разнообразным обстоятельствам в сети. Например, предположим, что сегмент сети отвергнут. Многие алгоритмы маршрутизации, после того как они узнают об этой проблеме, быстро выбирают следующий наилучший путь для всех маршрутов, которые обычно используют этот сегмент. Алгоритмы маршрутизации могут быть запрограммированы таким образом, чтобы они могли адаптироваться к изменениям полосы пропускания сети, размеров очереди к роутеру, величины задержки сети и других переменных. Алгоритмы маршрутизации могут быть классифицированы по типам. Например, алгоритмы могут быть: 1. Статическими или динамическими 2. Одномаршрутными или многомаршрутными 3. Одноуровневыми или иерархическими 4. С интеллектом в главной вычислительной машине или в роутере 5. Внутридоменными и междоменными 6. Алгоритмами состояния канала или вектора расстояний Статические или динамические алгоритмы Статические алгоритмы маршрутизации вообще вряд ли являются алгоритмами. Распределение статических таблиц маршрутизации устанавливется администратором сети до начала маршрутизации. Оно не меняется, если только администратор сети не изменит его. Алгоритмы, использующие статические маршруты, просты для разработки и хорошо работают в окружениях, где трафик сети относительно предсказуем, а схема сети относительно проста. Т.к. статические системы маршрутизации не могут реагировать на изменения в сети, они, как правило, считаются непригодными для современных крупных, постоянно изменяющихся сетей. Большинство доминирующих алгоритмов маршрутизации 1990гг. - динамические. Динамические алгоритмы маршрутизации подстраиваются к изменяющимся обстоятельствам сети в масштабе реального времени. Они выполняют это путем анализа поступающих сообщений об обновлении маршрутизации. Если в сообщении указывается, что имело место изменение сети, программы маршрутизации пересчитывают маршруты и рассылают новые сообщения о корректировке маршрутизации. Такие сообщения пронизывают сеть, стимулируя роутеры заново прогонять свои алгоритмы и соответствующим образом изменять таблицы маршрутизации. Динамические алгоритмы маршрутизации могут дополнять статические маршруты там, где это уместно. Например, можно разработать "роутер последнего обращения" (т.е. роутер, в который отсылаются все неотправленные по определенному маршруту пакеты). Такой роутер выполняет роль хранилища неотправленных пакетов, гарантируя, что все сообщения будут хотя бы определенным образом обработаны. Одномаршрутные или многомаршрутные алгоритмы Некоторые сложные протоколы маршрутизации обеспечивают множество маршрутов к одному и тому же пункту назначения. Такие многомаршрутные алгоритмы делают возможной мультиплексную передачу трафика по многочисленным линиям; одномаршрутные алгоритмы не могут делать этого. Преимущества многомаршрутных алгоритмов очевидны - они могут обеспечить заначительно большую пропускную способность и надежность. Одноуровневые или иерархические алгоритмы Некоторые алгоритмы маршрутизации оперируют в плоском пространстве, в то время как другие используют иерархиии маршрутизации. В одноуровневой системе маршрутизации все роутеры равны по отношению друг к другу. В иерархической системе маршрутизации некоторые роутеры формируют то, что составляет основу (backbone - базу) маршрутизации. Пакеты из небазовых роутеров перемещаются к базовыи роутерам и пропускаются через них до тех пор, пока не достигнут общей области пункта назначения. Начиная с этого момента, они перемещаются от последнего базового роутера через один или несколько небазовых роутеров до конечного пункта назначения. Системы маршрутизации часто устанавливают логические группы узлов, называемых доменами, или автономными системами (AS), или областями. В иерархических системах одни роутеры какого-либо домена могут сообщаться с роутерами других доменов, в то время как другие роутеры этого домена могут поддерживать связь с роутеры только в пределах своего домена. В очень крупных сетях могут существовать дополнительные иерархические уровни. Роутеры наивысшего иерархического уровня образуют базу маршрутизации. Основным преимуществом иерархической маршрутизации является то, что она имитирует организацию большинства компаний и следовательно, очень хорошо поддерживает их схемы трафика. Большая часть сетевой связи имеет место в пределах групп небольших компаний (доменов). Внутридоменным роутерам необходимо знать только о других роутерах в пределах своего домена, поэтому их алгоритмы маршрутизации могут быть упрощенными. Соответственно может быть уменьшен и трафик обновления маршрутизации, зависящий от используемого алгоритма маршрутизации. Алгоритмы с игнтеллектом в главной вычислительной машине или в роутере Некоторые алгоритмы маршрутизации предполагают, что конечный узел источника определяет весь маршрут. Обычно это называют маршрутизацией от источника. В системах маршрутизации от источника роутеры действуют просто как устойства хранения и пересылки пакета, без всякий раздумий отсылая его к следующей остановке. Другие алгоритмы предполагают, что главные вычислительные машины ничего не знают о маршрутах. При использовании этих алгоритмов роутеры определяют маршрут через об'единенную сеть, базируясь на своих собственных расчетах. В первой системе, рассмотренной выше, интеллект маршрутизации находится в главной вычислительной машине. В системе, рассмотренной во втором случае, интеллектом маршрутизации наделены роутеры. Компромисс между маршрутизацией с интеллектом в главной вычислительной машине и маршрутизацией с интеллектом в роутере достигается путем сопоставления оптимальности маршрута с непроизводительными затратами трафика. Системы с интеллектом в главной вычислительной машине чаще выбирают наилучшие маршруты, т.к. они, как правило, находят все возможные маршруты к пункту назначения, прежде чем пакет будет действительно отослан. Затем они выбирают наилучший мааршрут, основываясь на определении оптимальности данной конкретной системы. Однако акт определения всех маршрутов часто требует значительного трафика поиска и большого об'ема времени. Внутридоменные или междоменные алгоритмы Некоторые алгоритмы маршрутизации действуют только в пределах доменов; другие - как в пределах доменов, так и между ними. Природа этих двух типов алгоритмов различная. Поэтому понятно, что оптимальный алгоритм внутридоменной маршрутизации не обязательно будет оптимальным алгоритмом междоменной маршрутизации. Алгоритмы состояния канала или вектора расстояния Алгоритмы состояния канала (известные также как алгоритмы "первоочередности наикратчайшего маршрута") направляют потоки маршрутной информации во все узлы об'единенной сети. Однако каждый роутер посылает только ту часть маршрутной таблицы, которая описывает состояние его собственных каналов. Алгоритмы вектора расстояния (известные также как алгоритмы Бэлмана-Форда) требуют от каждогo роутера посылки всей или части своей маршрутной таблицы, но только своим соседям. Алгоритмы состояния каналов фактически направляют небольшие корректировки по всем направлениям, в то время как алгоритмы вектора расстояний отсылают более крупные корректировки только в соседние роутеры. Отличаясь более быстрой сходимостью, алгоритмы состояния каналов несколько меньше склонны к образованию петель маршрутизации, чем алгоритмы вектора расстояния. С другой стороны, алгоритмы состояния канала характеризуются более сложными расчетами в сравнении с алгоритмами вектора расстояний, требуя большей процессорной мощности и памяти, чем алгоритмы вектора расстояний. Вследствие этого, реализация и поддержка алгоритмов состояния канала может быть более дорогостоящей. Несмотря на их различия, оба типа алгоритмов хорошо функционируют при самых различных обстоятельствах.
3. Компоненты маршрутизации. Маршрутизация включает в себя два основных компонента: определение оптимальных трактов маршрутизации и транспортировка информационых групп (обычно называемых пакетами) через об'единенную сеть. В настоящей работе последний из этих двух компонентов называется коммутацией. Коммутация относительно проста. С другой стороны, определение маршрута может быть очень сложным процессом. Определение маршрута Определение маршрута может базироваться на различных показателях (величинах, результирующих из алгоритмических вычислений по отдельной переменной - например, длина маршрута) или комбинациях показателей. Программные реализации алгоритмов маршрутизации высчитывают показатели маршрута для определения оптимальных маршрутов к пункту назначения. Для облегчения процесса определения маршрута, алгоритмы маршрутизации инициализируют и поддерживают таблицы маршрутизации, в которых содержится маршрутная информация. Маршрутная информация изменяется в зависимости от используемого алгоритма маршрутизации. Алгоритмы маршрутизации заполняют маршрутные таблицы неким множеством информации. Ассоциации "Пункт назначения/следующая пересылка" сообщают роутеру, что определенный пункт назначения может быть оптимально достигнут путем отправки пакета в определенный роутер, представляющий "следующую пересылку" на пути к конечному пункту назначения. При приеме поступающего пакета роутер проверяет адрес пункта назначения и пытается ассоциировать этот адрес со следующей пересылкой. На рис. 2-1 приведен пример маршрутной таблицы "место назначения/следующая пересылка".
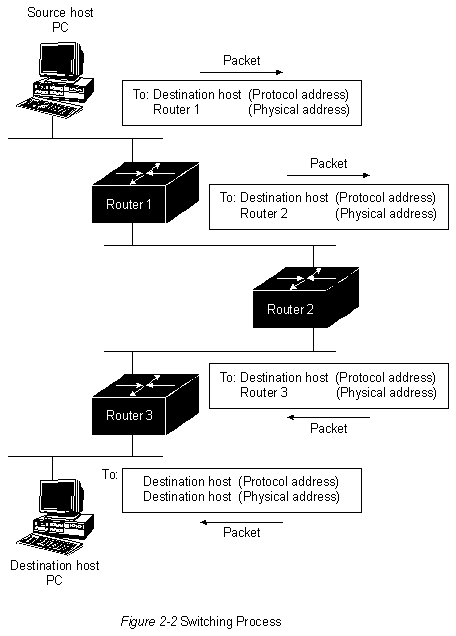
В маршрутных таблицах может содержаться также и другая информация. "Показатели" обеспечивают информацию о желательности какого-либо канала или тракта. Роутеры сравнивают показатели, чтобы определить оптамальные маршруты. Показатели отличаются друг oт друга в зависимости от использованной схемы алгоритма маршрутизации. Далее в этой главе будет представлен и описан ряд общих показателей. Роутеры сообщаются друг с другом (и поддерживают свои маршрутные таблицы) путем передачи различных сообщений. Одним из видов таких сообщений является сообщение об "обновлении маршрутизации". Обновления маршрутизации обычно включают всю маршрутную таблицу или ее часть. Анализируя информацию об обновлении маршрутизации, поступающую ото всех роутеров, любой из них может построить детальную картину топологии сети. Другим примером сообщений, которыми обмениваются роутеры, является "об'явление о состоянии канала". Об'явление о состоянии канала информирует другие роутеры о состоянии кааналов отправителя. Канальная информация также может быть использована для построения полной картины топологии сети. После того, как топология сети становится понятной, роутеры могут определить оптимальные маршруты к пунктам назначения. Коммутация Алгоритмы коммутации сравнительно просты и в основном одинаковы для большинства протоколов маршрутизации. В большинстве случаев главная вычислительная машина определяет необходимость отправки пакета в другую главную вычислительную машину. Получив определенным способом адрес роутера, главная вычислительная машина-источник отправляет пакет, адресованный специально в физический адрес роутера (уровень МАС), однако с адресом протокола (сетевой уровень) главной вычислительной машины пункта назначения. После проверки адреса протокола пункта назначения пакета роутер определяет, знает он или нет, как передать этот пакет к следующему роутеру. Во втором случае (когда роутер не знает, как переслать пакет) пакет, как правило, игнорируется. В первом случае роутер отсылает пакет к следующей роутеру путем замены физического адреса пункта назначения на физический адрес следующего роутера и последующей передачи пакета. Следующая пересылка может быть или не быть главной вычислительной машиной окончательного пункта назначения. Если нет,то следующей пересылкой, как правило, является другой роутер, который выполняет такой же процесс принятия решения о коммутации. По мере того, как пакет продвигается через об'единенную сеть, его физический адрес меняется, однако адрес протокола остается неизменным. Этот процесс иллюстрируется на Рис. 2-2.
В изложенном выше описании рассмотрена коммутация между источником и системой конечного пункта назначения. Международная Организация по Стандартизации (ISO) разработала иерархическую терминологию, которая может быть полезной при описании этого процесса. Если пользоваться этой терминологией, то устройства сети, не обладающие способностью пересылать пакеты между подсетями, называются конечными системами (ЕS), в то время как устройства сети, имеющие такую способность, называются промежуточными системами (IS). Промежуточные системы далее подразделяются на системы, которые могут сообщаться в пределах "доменов мааршрутизации" ("внутридоменные" IS), и системы, которые могут сообщаться как в пределах домена маршрутизации, так и с другими доменами маршрутизации ("междоменные IS"). Обычно считается, что "домен маршрутизации" - это часть об'единенной сети, находящейся под общим административным управлением и регулируемой пределенным набором административных руководящих принципов. Домены маршрутизации называются также "автономными системами" (AS). Для опрелеленных протоколов домены маршрутизации могут быть дополнительно подразделены на "участки маршрутизации", однако для коммутации как внутри участков, так и между ними также используются внутридоменные протоколы маршрутизации. Метрики алгоритмов маршрутизации: 1. Длина маршрута 2. Надежность 3. Задержка 4. Ширина полосы пропускания 5. Нагрузка 6. Стоимость связи
4. Формат заголовка IP. Стандартный размер IP-заголовка (при отсутствии опций) — 20 байтов. Здесь и в дальнейшем мы изображаем заголовки рассматриваемых протоколов TCP/IP в единообразных обозначениях. Старший разряд всегда располагается слева в позиции 0. Соответственно, младший разряд слова — крайний справа в позиции с номером 31. Четыре байта 32-разрядного слова передаются в такой последовательности: первыми — позиции с 0 по 7, далее 8-15, затем 16-23 и наконец 24-31. Применительно к компьютерам это называют порядком с наибольшим номером в конце (big endian). Только такой порядок разрешен при передаче полей любых заголовков TCP/IP, поэтому его иногда называют сетевым порядком байтов (network byte order). На машинах, где двоичные целые имеют другой формат, например порядок с наименьшим номером в конце (little endian), возникает необходимость трансформировать все заголовки отсылаемого пакета согласно сетевому порядку байтов. В поле версия (version) для современного варианта протокола IP записывается 4. (Ныне используемый протокол IP называют IPv4.) Длина заголовка (header length) измеряется количеством 32-разрядных слов заголовка с учетом всех присутствующих в нем опций. Так как для этого параметра отведено поле 4 бита, то размер заголовка ограничен 60 байтами. В главе 8 мы увидим, что из-за этого ограничения некоторые из прежде применявшихся опций (например, опция записи маршрута RR) стали практически бесполезными. Обычное значение поля длина заголовка (при отсутствии опций) равно 5. Однобайтовое поле тип сервиса TOS (type-of-semice) подразделяется на шесть субполей. Первое трехразрядное субполе приоритет (precedence) редко применяется на практике. Последнее безымянное одноразрядное субполе всегда содержит 0. Между ними находятся четыре одноразрядных субполя, которые и называют собственно битами TOS. Каждому из четырех битовTOS сопоставлен определенный критерий доставки дейтаграмм: минимальная задержка, максимум пропускной способности, максимум надежности и минимум стоимости. Только один бит TOS может быть установлен в 1. По умолчанию все четыре бита равны 0, что означает отсутствие особых требований, то есть обычный сервис. В RFC 1340 [Reynolds andPostel, 1992] определено, каким образом значения TOS должны устанавливаться всеми стандартными приложениями. Некоторые уточнения, а также более подробное описание TOS опубликованы в RFC 1349 [Almquist, 1992]. Рекомендуемые значения TOS для различных приложений. В последней колонке приводятся шестнадцатеричные значения в том формате, в каком мы будем видеть это поле в распечатках программы tcpdump, часто используемой в последующих примерах. Для интерактивных приложений Telnet и Rlogin желательна минимальная задержка с учетом человеческого фактора и малых объемов передаваемых данных. Передача файлов с помощьюFTP, напротив, требует обеспечения максимальной пропускной способности. Для протоколов управления сетью (SNMP) и протоколов маршрутизации необходима максимальная надежность. Служба новостей Usenet (NNTP) -единственное из приведенных в таблице приложений, которое запрашивает минимальную стоимость. Возможность задания TOS внедряется медленно — она не поддерживалась в большинстве прежних реализаций TCP/IP. Более поздние системы (начиная с Unix версии 4.3BSD Reno) уже обеспечивают TOS. Более того, современные протоколы типа OSPF и IS-IS могут принимать решения о маршрутизации с учетом критериев TOS. Драйверы SLIP обычно организуют очередь в зависимости от типа сервиса, обеспечивая преимущественную обработку диалогового трафика перед массивными данными. Так как большинство приложений все еще не используют ноле TOS, организацией очереди вынужден заниматься сам SLIP. Драйвер SLIP но значению поля протокол определяет, содержит ли дейтаграмма сегмент TCP, а затем проверяет номера TCP-портов источника и назначения, чтобы узнать, соответствует ли помер порта диалоговому сервису. В комментариях к одному из подобных драйверов указано, что ему приходится совершать эти "незаконные действия" вследствие того, что большинство реализаций до сих пор не позволяют приложениям устанавливать значение ноля TOS. Общая длина (total length) IP-дейтаграммы измеряется в байтах. По значениям полей общая длина и длина заголовка можно определить смещение и размер области данных в IP-дейтаграмме. Общая длина задается 16-разрядным числом, следовательно, максимальный размерIP-дейтаграммы — 65 535 байтов. (что MTU для гиперканала равен 65 535: мы видим, что в действительности гиперканал не ставит ограничений — там указан предельный размер IP-дейтаграммы.) При фрагментации дейтаграммы содержимое поля общей длины изменяется соответственно размеру фрагмента. Существует гипотетическая возможность формировать IP-дейтаграммы предельного размера 65 535 байтов. Однако на канальном уровне такие дейтаграммы неизбежно подвергнутся фрагментации. Кроме того, надо учитывать, что хост может оказаться не способным принимать дейтаграммы размера, превышающего 576 байтов. Последнее ограничение обычно не отражается на работе приложений над TCP, так как TCP-модуль сам разбивает данные пользователя на части. Многие приложения, работающие над UDP (RIP, TFTP, BOOTP, DNS иSNMP), формируют блоки данных пользователя размером до 512 байтов, чтобы соблюсти 576-байтовый предел. На практике большинство современных реализаций TCP/IP, особенно поддерживающие сетевую файловую систему NFS (Network File System), ограничивают размерIP-дейтаграмм 8192 байтами. Общая длина обязательно должна указываться в IP-заголовке хотя бы потому, что в некоторых канальных протоколах (например, в Ethernet) слишком короткие кадры дополняются до минимально допустимого размера. Несмотря на то что минимальный размер кадра Ethernet — 46 байтов, IP-дейтаграмма может быть еще короче. Не располагая значением поля общей длины,IP-модуль не смог бы выяснить, какая часть 46-байтового кадра Ethernet составляет исходную IP-дейтаграмму. Поле идентификатор (identification) однозначно определяет каждую посланную хостом дейтаграмму. Обычно его значение увеличивается на единицу с посылкой каждой дейтаграммы. Там же мы рассмотрим поля флаги (flags) и смещение фрагмента (fragment offset). В RFC 791 (Postel, 1981a| указывается, что идентификатор должен быть задай на том верхнем уровне, который обращается к IP для отправки дейтаграммы. Это означает, что у двух последовательных IP-дейтаграмм, порожденных соответственно TCP и UDP, значение идентификатора случайным образом может совпадать. Несмотря на то что это не опасно (алгоритм сборки обрабатывает такие случаи), большинство реализаций, производных от BSD, заставляют уровень IP дополнительно увеличивать специальную переменную ядра на 1 при отправке каждой IP-дейтаграммы вне зависимости от того, какой протокол обратился к IP для передачи своих данных. ' Эта переменная инициализируется случайным значением, зависящим от текущего времени при начальной загрузке системы. Поле срок жизни, или TTL (time-to-live), устанавливает максимальное число промежуточных пунктов на трассе продвижения дейтаграммы, чем ограничивается срок ее существования. Начальное значение в этом поле (обычно 32 или 64) задает отправитель, а каждый обрабатывающий дейтаграмму маршрутизатор уменьшает текущее значение на единицу.' При достижении 0 дейтаграмма уничтожается, и ее источник уведомляется об этом соответствующимICMP-сообщением. Так предотвращается бесконечная циркуляция пакетов, попавших в порочный замкнутый маршрут. Мы вернемся к обсуждению поля TTL в главе 8 при изучении поведения программы "raceroute. Поле протокол (protocol) уже рассматривалось в главе 1, где на рис. 1.8 было показано, каким образом оно используется IP-модулем для демультиплексирования приходящих дейтаграмм. Это поле идентифицирует тот протокол, чьи данные содержатся в принятой IP-дейтаграмме. Контрольная сумма заголовка (header checksum) рассчитывается только по байтам IP-заголовка. Она не включает в себя данные, расположенные вслед за ним. (Наоборот, заголовки ICMP, IGMP,UDP и TCP оснащены контрольной суммой, охватывающей как сам заголовок, так и их собственные данные.) Для вычисления контрольной суммы IP-заголовка в исходящей дейтаграмме значение этого поля сначала устанавливается в 0. Затем выполняется сложение "по модулю один"всех 16-разрядных слов заголовка, и инвертированное значение результата записывается в поле контрольной суммы. При получении IP-дейтаграммы вновь вычисляется сумма 16-разрядных слов заголовка по модулю один. Так как в заголовке принятой дейтаграммы уже содержится сосчитанная (и инвертированная) отправителем контрольная сумма, в результате должно получиться слово, состоящее только из единиц (если в заголовке ничего не изменилось). Если же получилась другая комбинация (ошибка контрольной суммы), IP-модуль уничтожает дейтаграмму. Никакого сообщения об ошибке не порождается. Обнаружение потери дейтаграммы и повторная передача считаются проблемой, решаемой на вышестоящих уровнях иерархии протоколов. ICMP, IGMP, UDP и TCP применяют такой же алгоритм вычисления контрольных сумм, однако TCPи UDP включают в подсчет некоторые поля заголовка IP в дополнение к собственному заголовку и данным. Реализационным аспектам алгоритмов подсчета контрольных сумм в протоколахInternet посвящен RFC 1071 [Braden, Borman and Partridge, 1988]. Поскольку маршрутизатор обычно изменяет в заголовке только поле TTL, уменьшая его на 1, то при транзитной передаче он может просто увеличить на 1 контрольную сумму вместо вычисления ее заново по всему IP-заголовку. В RFC 1141 [Mallory and Kullberg, 1990] описан эффективный способ реализации этого алгоритма. Тем не менее в стандартных реализациях BSD Unix при транзитной передаче дейтаграммы возможность простого инкрементирования контрольной суммы заголовка не используется. Каждая IP-дейтаграмма содержит IP-адрес источника и IP-адрес назначения. Это 32-разрядные числа. В последнем, необязательном поле IP-заголовка могут передаваться в виде списков переменной длины дополнительные данные, называемые IP-опциями (IP-options). Определены следующие опции: · защита данных (для секретных приложений оборонного значения — см. дополнительно в RFC 1108 [Kent, 1991]); · запись маршрута (заставляет каждый маршрутизатор записывать свой IP-адрес —); · штемпель времени (заставляет каждый маршрутизатор записывать свой
|