Лінійна множинна регресія. Процедури регресійного аналізу об’єднано в модулі «Multiple Regression – Множинна регресія»
Процедури регресійного аналізу об’єднано в модулі «Multiple Regression – Множинна регресія». Як приклад, розглянемо модель залежності обсягу виконаних наукових та науково-технічних робіт у фактичних цінах млн грн (Y) від кількості організації, які виконують наукові дослідження й розробки (Х1), чисельності докторів наук в економіці України (Х2) та чисельності науковців (Х3). Вихідні дані для аналізу наведені в табл. 5. Запустимо програму Statistica і сформуємо файл даних. На панелі інструментів (або в меню Statistics) вибираємо модуль Multiple Regression. У стартовому вікні модуля, натиснувши кнопку Variables, вибираємо залежну (Dependent var.) і незалежну (Independent var.) змінні. На закладці Advanced можна задати додаткові параметри побудови регресійної моделі. За командою виконання програми з'явиться вікно результатів аналізу (рис. 7).
Таблиця 5 Вихідні дані для аналізу [16]
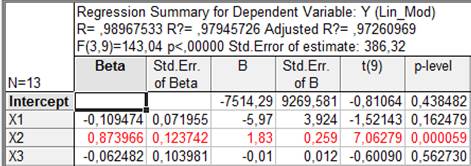
В інформаційній частині вікна міститься така інформація: назва залежної змінної та обсяг сукупності; наводяться значення коефіцієнтів щільності зв’язку (множинної кореляції, множинної детермінації та скоректований коефіцієнт множинної детермінації); значення F-критерію, стандартної похибки оцінювання (Standard error o f estimate), вільного члена рівняння регресії b0 (Intercept) та його похибки (Std. Error), значення критерію Стьюдента, значення bі-коефіцієнтів. У функціональній частині вікна містяться кнопки та опції, що дозволяють усебічно розглянути результати регресійного аналізу. Так, на закладці Quik є кнопка Summary: Regression Results – Результати регресії, яка виводить таблицю результатів побудови регресії (рис. 8). У цій таблиці наведені такі результати побудови регресії: bі-коефіцієнти (Beta) і коефіцієнти регресії bi зі стандартними похибками, значення t-критерію та фактичні рівні істотності p-level. Зверніть увагу на те, що деякі рядки виділені червоним кольором. Це своєрідна підказка щодо значущості відповідних параметрів побудованої моделі. Значущість параметрів оцінюється за t-критерієм, значення якого наведені в цій же таблиці.
Рис. 7. Вікно Результатів множинної регресії
Рис. 8. Результати регресії
Наступним кроком є аналіз адекватності побудованої моделі. Про адекватність моделі можна судити за значеннями коефіцієнтів множинної кореляції та детермінації, за значеннями критеріїв Стьюдента та Фішера. Окрім того, слід провести аналіз залишків моделі. Для цього призначена кнопка Perform residual analysis, яка знаходиться на закладці Residuals/assumptions/prediction у вікні Результатів множинної регресії. Натиснувши цю кнопку, переходимо у вікно Аналіз залишків (рис. 9).
Рис. 9. Вікно аналізу залишків
У цьому вікні поданий великий набір аналітичних та графічних інструментів, призначених для аналізу залишків моделі. Наглядними і найважливішими є гістограма розподілу залишків (закладка Residuals, кнопка Histogram of residuals) і графік залишків на нормальному ймовірнісному папері (закладка Probability plots, кнопка Normal plot of residuals). Відповідні графіки наведено на рис. 10, 11.
Рис. 10. Гістограма розподілу залишків
Рис. 11. Графік залишків на нормальному ймовірнісному папері Якщо залишки розподілені за нормальним законом розподілу (гістограма залишків) і добре лягають на пряму (графік залишків на нормальному ймовірнісному папері), то це свідчить про адекватність побудованої моделі. Інакше потрібно визначити іншу функціональну залежність. У модулі «Множинна регресія» можна знайти прогнозне значення залежної змінної. Для цього у вікні результатів необхідно перейти на закладку Residuals/assumptions/prediction і натиснути кнопку Predict dependent variable – Прогнозне значення залежної змінної. У вікні, що з’явилося, потрібно задати значення незалежних змінних, при яких слід знайти прогнозне значення залежної змінної. Наприклад, задамо такі значення (рис. 12).
Рис. 12. Значення незалежних змінних для обчислення прогнозного значення залежної змінної Після виконання команди отримаємо наступну таблицю результатів (рис. 13).
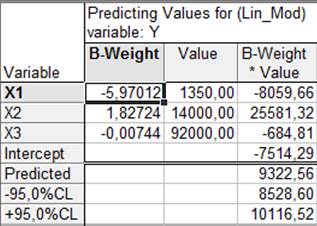
Рис. 13. Результати прогнозування
У цій таблиці в стовпці B-Weight указані коефіцієнти регресії при залежних змінних, у стовпці Value – значення незалежних змінних, які щойно були задані. У рядку Intercept вказане значення вільного члена регресії, у рядку Predicted – прогнозне значення залежної змінної. Нижче вказані нижня та верхня межі довірчого інтервалу. Отже, якщо кількість організації, які виконують наукові дослідження й розробки дорівнює 1 350, чисельність докторів наук в економіці України — 14 000 осіб, а чисельність науковців — 92 000 осіб, то обсяг виконаних наукових та науково-технічних робіт становитиме 9 322,56 млн грн США. Завдання. Самостійно ознайомтеся з іншими аналітичними та графічними можливостями модуля «Множинна регресія». Побудуйте регресію, використовуючи інші методи (метод підключень та метод виключень). Порівняйте та проаналізуйте результати, отримані різними методами.
|