Гайдамакин Н. А. 5 страница
— в оперативную память из внешней считывается страница с корневой вершиной и последовательно просматривается до первого значения, превышающего значение индексируемого поля нужной записи. При этом определяется ссылка (номер) страницы-потомка (внутренней или листовой); — в оперативную память считывается страница-потомок. Если она внутренняя, то ее обработка производится аналогично корневой. Если страница-потомок является листовой, то она последовательно просматривается до нахождения нужного значения индексируемого поля. При этом определяется номер страницы файла данных, которая содержит нужную запись; — если при просмотре листовой страницы нужное значение индексируемого поля не находится, то поиск считается отрицательным, т. е. принимается решение о том, что строки-кортежа с требуемым значением индексируемого поля в таблице-отношении (файле данных) нет. Анализ данного алгоритма показывает, что при поиске нужного значения индексируемого поля по индексу в виде Б-дерева требуется такое количество страничных обменов между внешней и внутренней памятью, которое равно уровню Б-дерева плюс единица. При достаточно большом значении n, а это, как уже отмечалось, наиболее распространенная ситуация, уровень m Б-дерева невелик (m >> 2..3), и, следовательно, количество страничных индексных обменов с памятью также невелико. При этом сбалансированность Б-дерева обусловливает одинаковые затраты по доступу к любой записи с любым значением индексируемого поля. Сбалансированность Б-деревьев обеспечивается легко алгоритмизируемым правилом их построения (роста) при включении нового значения индексируемого поля. Включение нового значения индексируемого поля осуществляется следующим образом. • Производится поиск требуемого значения в существующем Б-дереве. При его отсутствии поиск, естественно, заканчивается отрицательным результатом, но в оперативной памяти остается листовая страница, куда, следовательно, и необходимо поместить новое значение индексируемого поля. • Если листовая страница не заполнена полностью, в нее записывается новое значение индексируемого поля и указатель на страницу файла данных, содержащую соответствующую запись (строку таблицы). • Если листовая страница уже заполнена, то она делится «пополам», и тем самым порождается новая листовая страница. Среднее значение исходной листовой страницы записывается в вершину-предок на соответствующее место.* При этом после вставленного значения образуется указатель-ссылка на новую листовую страницу, образованную остатком от ополовиненной исходной листовой страницы. * Так, чтобы в странице обеспечивался последовательный порядок расположения -значений индексируемого поля по схеме, приведенной на рис. 2.17.
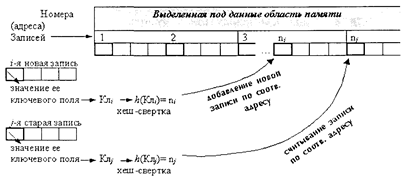
• Если при занесении среднего значения переполненной листовой страницы в страницу-предок происходит переполнение самой страницы-предка, то она аналогично делится пополам, «посылая» свое среднее значение своему предку. Если при этом происходит переполнение корневой страницы, то она также делится на две новые внутренние страницы, а ее среднее значение образует новую корневую страницу, повышая уровень дерева на единицу и т. д. (говорят, что Б-дерево «растет» вверх). Удаление определенного значения индексируемого поля производится следующим образом: • Производится поиск требуемого значения индексируемого поля и в результате в оперативную память считывается нужная листовая страница. • Из нее удаляется соответствующее значение индексируемого поля и указатель-адрес соответствующей страницы файла данных. • Если после удаления размер занятого пространства памяти текущей листовой страницы в сумме с размером занятого пространства левого (правого) брата больше, чем размер памяти одной страницы, то процесс заканчивается. • В противном случае текущая листовая страница объединяется с левым (правым) братом. Тем самым одна из листовых страниц (левая или правая) опустошается и уничтожается. В вершине-предке удаляется значение индексируемого поля, указатель перед которым или после которого ссылался на опустошенную листовую страницу. При этом может, в свою очередь, возникнуть необходимость слияния и опустошения уже внутренних страниц, которое осуществляется аналогичным образом. Описанный алгоритм удаления значений индексируемого поля соответствует одной из наиболее широко применяемых разновидностей Б-деревьев— Б*-деревьев, которые позволяют использовать в среднем до 2/3 пространства всех страниц (вершин) дерева. Структура Б-деревьев является эффективным способом индексации больших массивов данных и широко применяется в современных СУБД. 2.3.3. Расстановка (хеширование) записей В некотором смысле альтернативным подходом к организации физических структур данных является расстановка записей. Как и при использовании линейных и нелинейных структур, основной задачей расстановки записей является минимизация расходов на доступ и изменения данных во внутренней и внешней памяти. Идея расстановки, известной в англоязычной литературе также под термином хеширование,* заключается в том, чтобы при выделении под размещение данных определенного участка памяти так организовать порядок расположения записей в нем, чтобы место для новых записей и поиск старых записей можно было осуществлять на основе некоторого преобразования их ключевых полей.** При образовании (добавлении) новой записи к значению ее ключевого поля применяется специальная хеш-функция (или иначе хеш-свертка), которая ставит в соответствие значению ключевого поля, и, следовательно, всей записи, некоторое числовое значение, обычно являющееся номером (адресом) местоположения, куда в итоге и помещается соответствующая запись (см. рис. 2.20). * От англ. to hash – нарезать, крошить, делить месиво, т.е. равномерно перемалывать ключи нолей в адреса (номера) записей. ** Отсюда еще одно название данного подхода—«преобразование ключей», впервые введенное в русской литературе еще в 1956 г. будущим академиком А. П. Ершовым.
Рис. 2.20. Принцип расстановки записей по значению ключей При доступе (поиске) нужной записи над значением ее ключевого поля также осуществляется хеш-свертка, что сразу же даст возможность определить местоположение искомой записи и получить к ней доступ. Таким образом, в идеале хеширование обеспечивает доступ к нужным записям за одно (!!!) обращение к области размещения данных. Функция преобразования h (Кл j) выбирается на основе двух требований: 1) ее результат для возможного диапазона значений ключевого поля должен находиться в пределах диапазона адресов (номеров) области памяти, выделяемой подданные, и 2) значения функции в пределах выделенного диапазона адресов должны быть равномерными. На практике наиболее широкое распространение нашли хеш-функции, основанные на операциях деления по модулю: h (Кл j)=(Кл j mod М) + 1, где (Кл j mod М) означает операцию деления по модулю М,* а число М выбирается исходя из необходимости попадания значений хеш-функции в требуемый диапазон. * Значением операции деления по модулю М является остаток от обычного деления числа на М, например результат деления 213 по модулю 20 равен 13.
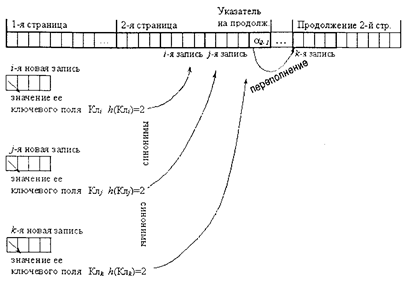
Если в качестве М выбрать число, являющееся степенью двух, то подобная хеш-функция эффективно вычисляется процедурами выделения нескольких двоичных цифр. Для текстовых ключевых полей обычно применяют подобные подходы, основанные на использовании операции сложения по модулю значений кодов первых нескольких символов ключа. Основной проблемой хеширования с прямой адресацией записей является возможность появления одинаковых значений хеш-сверток при разных значениях полей (так называемые синонимы). Такие ситуации называются коллизиями, так как требуют определенного порядка, правила их разрешения. Применяются два подхода к разрешению коллизий. Первый подход основывается на использовании технологии цепных списков и заключается в присоединении к записям, по которым возникают коллизии, специальных дополнительных указателей, по которым размещаются новые записи, конфликтующие по месту расположения с ранее введенными. Как правило, для таких записей отводится специально выделенный участок памяти, называемый областью переполнения. В алгоритм доступа добавляются операции перехода по цепному списку для нахождения искомой записи. Вместе с тем при большом количестве переполнении теряется главное достоинство хеширования — доступ к записи за одно обращение к памяти. Второй подход к разрешению коллизий основывается на использовании дополнительного преобразования ключей по схеме:
где n При этом могут встречаться ситуации, когда и такое дополнительное преобразование приводит к коллизии, т.е. новое значение n
где f(k) – некоторая функция над номером итерации (пробы). В зависимости от вида функции f(k) такие подходы называют линейными или квадратичными пробами. Основным недостатком второго подхода к разрешению коллизий является во многих случаях существенно больший объем вычислений, а также появление для линейных проб эффектов группирования номеров (адресов) текстовых ключевых полей, т. е. неравномерность номеров, если значения ключей отличаются друг от друга всего несколькими символами. Вместе с тем коллизии (одинаковые значения хеш-сверток ключей) при использовании страничной организации структуры файлов баз данных во внешней памяти получили свое положительное и логичное разрешение и применение. Значением хеш-свертки ключа в этом случае является номер страницы, куда помещается или где находится соответствующая запись (см. рис. 2.21).
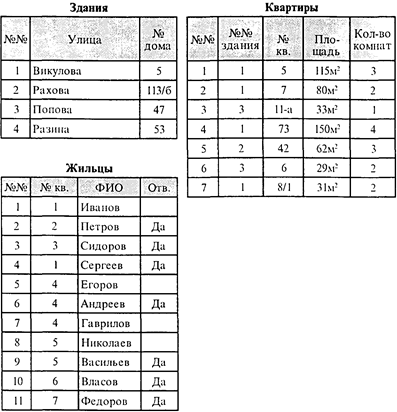
Рис. 2.21. Принцип хеширования записей но страницам файла данных Для доступа к нужной записи сначала производится хэш-свертка значения его ключевого поля и тем самым определяется номер страницы файла базы данных, содержащей нужную запись. Страница файла данных из дисковой пересылается в оперативную память, где путем последовательного перебора отыскивается требуемая запись. Таким образом, при отсутствии переполнении доступ к записям осуществляется за одно страничное считывание данных из внешней памяти. С учетом того что количество записей, помещающихся в одной странице файла данных, в большинстве случаев достаточно велико, случаи переполнений на практике не так часты. Вместе с тем, при большом количестве записей в таблицах файла данных, количество переполнении может существенно возрасти и так же, как и в классическом подходе, теряется главное достоинство хэширования — доступ к записям за одну пересылку страницы в оперативную память. Для смягчения подобных ситуаций могут применяться комбинации хэширования и структуры Б-деревьев для размещения записей по страницам в случаях переполнения. Внутренняя схема базы данных обычно скрыта от пользователей информационной системы, за исключением возможности установления и использования индексации полей. Вместе с тем, особенности физической структуры файлов данных и индексных массивов, принципы организации и использования дискового пространства и внутренней памяти, реализуемые конкретной СУБД, должны учитываться проектировщиками банков данных, так как эти «прозрачные» для пользователей-абонентов особенности СУБД критично влияют на эффективность обработки данных в информационной системе. Вопросы и упражнения 1. Перечислите основные функции, реализуемые СУБД, и охарактеризуйте их с точки зрения системного или прикладного характера решаемых задач. 2. Объясните соотношение понятии «операции», «транзакции» и «работа (действия) пользователя» в базе данных. 3. Перечислите (функциональные компоненты СУБД и охарактеризуйте системный или прикладной характер решаемых ими задач. 4. Дайте определение «модели организации данных» и перечислите ее составляющие. Охарактеризуйте особенности сетевой модели данных по отношению к иерархической модели. 5. Перечислите основные понятия структурной составляющей реляционной модели данных. Каким образом строятся связи между таблицами-отношениями, какие типы связей и почему обеспечиваются при этом? 6. В чем заключается н каким образом обеспечивается целостность в реляционной модели данных? 7. Какое основное различие между операциями обновления данных и операциями обработки таблиц-отношений в реляционной модели? 8. Дайте определение операции ОБЪЕДИНЕНИЯ таблиц-отношений. Каково наименьшее и наибольшее количество строк может быть в результате объединения таблиц? 9. Дайте определение операции ПЕРЕСЕЧЕНИЯ таблиц-отношений. Каково наименьшее и наибольшее количество строк может быть в результате пересечения таблиц? 10. Дайте определение операции ВЫЧИТАНИЯ таблиц-отношений. Каково наименьшее н наибольшее количество строк может быть в результате вычитания таблиц? 11. Какие нарушения целостности данных могут происходить в результате операции ПРОЕКЦИЯ (ВЕРТИКАЛЬНОЕ ПОДМНОЖЕСТВО)? 12. Дайте определениe операции СОЕДИНЕНИЯ таблиц-отношений. Каково наименьшее n наибольшее количество строк может быть в результате соединения таблиц? 13. Что является единичным элементом в физической структуре данных? В какие структуры более высокого порядка объединяются единичные элементы данных? 14. Дайте сравнительную характеристику преимуществ и недостатков разновидностей линейных структур физической организации данных. 15. Охарактеризуйте общий принцип нелинейных структур физической организации данных и перечислите их основные разновидности. 16. Выделите и поясните главную идею использования древовидных иерархических структур физической организации данных. В терминологии теории графов дайте определения основных понятий «деревьев». 17. Постройте средствами теории графов структуру физической организации данных, которая могла бы соответствовать на логическом уровне следующим трем таблицам:
Определите тип и параметры построенной структуры физической организации данных. Укажите, сколько страниц файла базы данных понадобится для данной структуры. 18. Обоснуйте выбор типа индексов для полей таблицы «Расписание занятий» со следующей схемой: №№, Дата, Время (1-я пара, 2-я пара, 3-пара, 4-я пара), Аудитория (30 аудиторий), Вид (Лекция, Семинар, Пр. занятие. Лабораторная работа. Зачет, Экзамен), Дисциплина (100 уч. дисциплин). Преподаватель (80 преподавателей), Учебная группа (15 уч.групп). 19. Произведите преобразование индекса в виде Б-дерева, представленного на рис. 2.18,при: а) добавлении 13-й записи «Данилов, 1976г. р.»; б) добавлении 14-й записи «Никаноров, 1967 г. р.»; в) удалении 9-й записи «Матвеев, 1979 г. р.». 20. Проиллюстрируйте (по шагам добавления записей) процесс построения индекса в виде Б-дерева 3-го порядка по полю «Таб_№» таблицы:
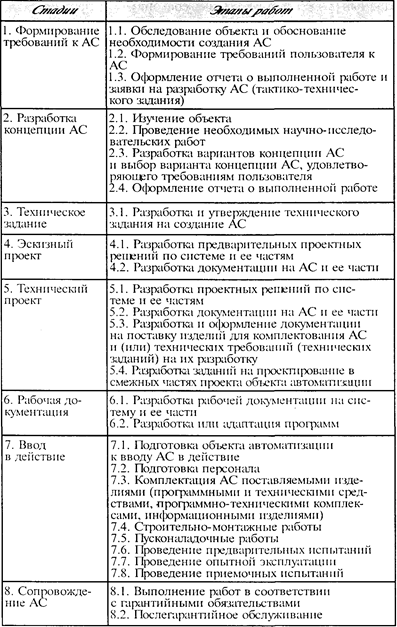
21. В чем преимущества и недостатки с точки зрения эффективности операций доступа к данным и преобразования данных между индексированием и хешированием?3. Основы создания автоматизированных информационных систем 3. Основы создания автоматизированных информационных систем 3.1. Общие положения по созданию автоматизированных систем Создание автоматизированных информационных систем в нашей стране регламентируется «Комплексом стандартов и руководящих документов на автоматизированные системы» (ГОСТ 34.201-89, ГОСТ 34.602-89, РД 50-682, РД 50-680-88, ГОСТ 34.601-90, ГОСТ 34.401-90, РД 50-34.698-90, ГОСТ 34.003-90, Р 50-34.119-90). В частности, ГОСТ 34.601-90 определяет следующие стадии и этапы создания АС (см. табл. 3.1). Таблица 3.1
Одним из центральных элементов всего процесса создания АС является разработка технического задания, структура которого согласно ГОСТ 34.602-89 содержит следующие разделы: 1) общие сведения; 2) назначение и цели создания (развития) системы; 3) характеристика объектов автоматизации; 4) требования к системе; 5) состав и содержание работ по созданию системы; 6) порядок контроля и приемки системы; 7) требования к составу и содержанию работ по подготовке объекта автоматизации к вводу системы в действие; 8) требования к документированию; 9) источники разработки. Суть технического задания как основного документа в процессе создания АС заключается в проработке, выборе и утверждении основных технических, организационных, программных, информационно-логических и лингвистических решений, которые устанавливаются в разделе «Требования к системе». Данный раздел, в свою очередь, состоит из трех подразделов: 1) требования к системе в целом; 2) требования к функциям (задачам), выполняемым системой; 3) требования к видам обеспечения. Требования к системе в целом отражают концептуальные параметры и характеристики создаваемой системы, среди которых указываются требования к структуре и функционированию системы, к надежности и безопасности, к численности и квалификации персонала и т. д. Требования к функциям (задачам) содержат перечень функций, задач или их комплексов; временной регламент каждой функции, задачи или комплекса задач; требования к качеству реализации каждой функции; к форме представления выходной информации; характеристики необходимой точности и времени выполнения, требования одновременности выполнения группы функций; достоверности выдачи результатов. Требования по видам обеспечения в зависимости от вида системы содержат требования по математическому, информационному, лингвистическому, программному, техническому, метрологическому, организационному, методическому и другим видам обеспечения системы. Для большинства разновидностей АС, в частности для всевозможных видов АИС, особое значение имеют решения и требования по информационному обеспечению. В данном подразделе, в частности, определяются требования: • к составу, структуре и способам организации данных в системе (информационно-логическая схема)', • к информационному обмену между компонентами системы; • к информационной совместимости со смежными системами; • по использованию общероссийских и других классификаторов, унифицированных документов; • по применению систем управления базами данных; • к структуре процесса сбора, обработки, передачи данных в системе и представлению данных; • к защите данных от разрушений при авариях и сбоях в электропитании системы; • к контролю, хранению, обновлению и восстановлению данных; • к процедуре придания юридической силы документам, продуцируемым техническими средствами АС. На основе установленных в техническом задании основных требований и технических решений на последующих этапах конкретизируются и непосредственно разрабатываются компоненты и элементы системы. В частности, на этапе 4.1 «Разработки предварительных проектных решений по системе и ее частям» определяются: • функции АС; • функции подсистем; • концепция информационной базы и ее укрупненная структура; • функции системы управления базой данных; • состав вычислительной системы; • функции и параметры основных программных средств. На этапе 5.1 «Разработка проектных решений но системе и ее частям» осуществляется разработка общих решений по системе и ее частям: • по функционально-алгоритмической структуре системы; • по функциям персонала и организационной структуре; • по структуре технических средств; • по алгоритмам решения задач и применяемым языкам; • по организации и ведению информационной базы (структура базы данных); • по системе классификации и кодирования информации (словарно-классификационная база); • по программному обеспечению. Разработка и документация программного обеспечения в процессе создания или комплектования автоматизированных систем (п. 6.2) регламентируются комплексом стандартов, объединенных в группу «Единая система программной документации (ЕСПД)». Таким образом, создание автоматизированных информационных систем представляет собой сложный многоэтапный процесс, требующий привлечения различных категорий специалистов — программистов, инженеров, управленческих и других работников. 3.2. Проектирование банков данных фактографических АИС Одной из наиболее трудоемких и сложных задач при создании АИС является проектирование банка данных как основы подсистемы представления и обработки информации. Логическая и физическая структуры банка данных отражают представление разработчиками и пользователями информационной системы той предметной области, сведения о которой предполагается отражать и использовать в АИС. Проектирование банков данных фактографических информационных систем осуществляется на основе формализации структуры и процессов предметной области АИС, и, в соответствии с уровнями представления информации в АИС (см. рис. 1.3), включает концептуальное (пп. 3.1 и 4.1) и схемно - структурное проектирование (п. 5.1). В организационном плане в группе разработчиков банка данных выделяют специалистов по формализации предметной области, специалистов по программному обеспечению СУБД, а также технических дизайнеров и специалистов по эргономике. Специалисты no формализации предметной области (их еще называют формализаторами или постановщиками задач), как правило, возглавляют весь проект создания АИС и обеспечивают (функции взaимодейcтвия с заказчиком. К данной категории специалистов предъявляются наиболее сложные профессиональные требования. С одной стороны, такие работники должны быть специалистами в севере программного обеспечения АИС (операционные системы, СУБД и т. д.), а с другой стороны, они должны хорошо представлять (или освоить) конкретную предметную область АИС, т. е. быть (временно стать) бухгалтерами, экономистами, делопроизводителями и т.п. Специалисты по программному обеспечению СУБД относятся к категории профессиональных программистов, определяют выбор СУБД и обеспечивают построение ее средствами автоматизированного банка данных по разработанной постановщиком задачи (формализатором) концептуальной схеме. Технические дизайнеры и cneциaлисты по эргономике обеспечивают эстетичную и эргономичную сторону интерфейса с пользователем в АИС при вводе, обработке и поиске данных. 3.2.1. Концептуальное проектирование Концептуальное проектирование банков данных АИС является в значительной степени эвристическим процессом, и адекватность построенной в его рамках инфологической схемы предметной области проверяется в большинстве случаев эмпирически по анализу и проверке удовлетворения информационных потребностей пользователей для решения задач АИС. В процедуре концептуального проектирования можно выделить следующие этапы: • обзор и изучение области использования АИС для формирования общего представления о предметной области; • формирование и анализ круга функций и задач АИС; • определение основных объектов-сущностей предметной области и отношений между ними; • формализованное описание предметной области. Обзор и изучение области использования АИС для формирования общего представления о предметной области осуществляется разработчиком в непосредственном взаимодействии с заказчиком. Разработчиком при этом изучается также и необходимая организационно-распорядительная документация — положения, уставы, инструкции, функциональные обязанности и т.п. На этой основе определяются основные процессы, участники и информационные потоки в предметной области АИС. Принципиальным моментом для фактографических АИС является фрагментирование предметной области, т. с. ее разделение на организационные, технологические, функциональные или иные фрагменты. При этом формализатору необходимо прояснить ряд вопросов и решить следующие задачи: • выделить перечень фрагментов (лица, принимающие решения на различных уровнях организационной иерархии, функционально-технологические структуры, подразделения и т. п.), подлежащих охвату, т. е. информационному отражению в АИС; • определить информационные потребности и информационные результаты деятельности каждого фрагмента (какая информация, в каком виде, в какие сроки и т. п.); • определить общие характеристики и содержание процессов потребления и обработки информации в каждом фрагменте (содержание информации, технология ее обработки, передачи, использования и т.д.). Ответы на эти вопросы помогут сформировать представление о существующей («как есть») технологии формирования, накопления, обработки и использования информации в рамках предметной области АИС и проанализировать совместно с заказчиком «узкие места» и недостатки в существующей технологии. Проиллюстрируем данный этап проектирования на примере создания банка данных фактографической АИС по учету, контролю, исполнению и прохождению организационно-распорядительных и информационно-справочных документов. Общее знакомство с предметной областью можно получить в беседе с руководителем и работниками службы документационного обеспечения управления (СлДОУ — секретариат, делопроизводство, канцелярия и т. п.) о системе и порядке документооборота в организации. Дополнительно целесообразно также ознакомиться с регламентирующими данный участок работы нормативными документами.* * В данном случае: Типовая инструкция по делопроизводству в министерствах и ведомствах Российской Федерации. — М.: Изд-е Комитета по делам архивов при Правительстве Российской Федерации, 1992; Примерное положение о службе документационного обеспечения управления» (приложение к «Типовой инструкции по делопроизводству...»). — М.: Изд-е Комитета по делам архивов при Правительстве Российской Федерации, 1992; ГОСТ Р 6.30-97 «Унифицированная Система Организационно-Распорядительной Документации. Требования к оформлению документов».
В результате такого знакомства можно выделить следующие фрагменты предметной области: • руководители организации; подразделения организации; их руководители; сотрудники, исполняющие документы; мероприятия; документы, обработка которых или подготовка которых реализует управленческие решения и мероприятия; • служба документационного обеспечения управления; его руководители и работники, ведущие регистрацию, учет, обработку и хранение документов. Информационные потребности первого фрагмента сводятся к своевременному получению и рассмотрению входящих документов, своевременному получению проектов готовящихся документов для согласования и визирования или принятых внутренних документов для исполнения или использования при организации и проведении различных мероприятий. Кроме того, для первого фрагмента важным является также и получение справочной информации по каким-либо конкретным документам, хранящимся в СлДОУ, поиск нужных документов по реквизитам, тематике, содержанию и т. п. Информационные потребности второго фрагмента в целом можно охарактеризовать необходимостью организации и контроля всех этапов документооборота в организации (где в данный момент находится конкретный документ, кем завизирован, подписан, утвержден, зарегистрирован, поставлен ли на контроль, исполнен ли, в какое дело приобщен и т. д.). Характеристики и процессы по документообороту кратко можно выразить следующим образом. Инициирование, подготовка и реализация большинства управленческих решений на различных уровнях организационной иерархии осуществляются на основе использования (руководства), подготовки, принятия и исполнения организационно-распорядительных и информационно-справочных документов. Входящие документы докладываются на решение руководителям организации, которые через резолюции на документах организуют принятие и исполнение необходимых мероприятий. Резолюции на документах доводятся СлДОУ до исполнителей (руководителей) подразделений. Исполнение мероприятия по документу ставится СлДОУ на контроль. Документ после исполнения по решению руководителя может быть уничтожен или приобщен к определенному номенклатурному делу. Внутренние организационно-распорядительные документы (приказы, решения, планы, графики) готовятся в плановом или в инициативном порядке исполнителями из соответствующих подразделений. При этом документ проходит стадию проекта, согласования, утверждения, доведения до исполнителей и исполнения. Для подготовки, принятия и исполнения организационно-распорядительных документов и при проведении различных мероприятий может потребоваться подготовка необходимых информационно-справочных документов (справок, протоколов, отчетов, писем, запросов и т. п.), стадии которых в общем плане могут исключать некоторые стадии организационно-распорядительных документов.
|

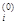 – исходное конфликтующее значение адреса записи; g(Кл i) – дополнительное преобразование ключа; n
– исходное конфликтующее значение адреса записи; g(Кл i) – дополнительное преобразование ключа; n 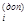 – дополнительное значение адреса.
– дополнительное значение адреса.