Гайдамакин Н. А. 9 страница
Запросы на выборку классифицируются по двум критериям — по формированию условий выборки и по схеме отбора данных. По формированию условий выборки запросы можно подразделить на три группы: • запросы со статическими (неизменяемыми) условиями отбора; • запросы с параметрами; • запросы с подчиненными запросами. В запросах первого вида условия выборки данных определяются при формировании самого запроса и являются неизменными при всех последующих выполнениях запроса. В запросы с параметрами вставляются специальные средства для диалогового задания пользователем конкретных параметров в условиях отбора в момент исполнения запроса. Таким образом, при запуске на исполнение запроса с параметрами пользователь может варьировать и уточнять условия выборки данных. В запросах третьей группы условия отбора данных определяются по результатам исполнения вставленной в тело внешнего запроса внутренней инструкции SELECT. По схеме отбора данных запросы на выборку подразделяются также на три группы: • запросы на выборку данных из одной таблицы; • запросы на выборку данных в один набор из нескольких таблиц; • запросы на объединение данных. 4.3.2.1.1. Запросы на выборку данных из одной таблицы Запросы на выборку данных из одной таблицы по смыслу и назначению сходны с фильтрацией данных в открытой таблице. Различие заключается лишь в форме представления результата (в частности, запросом на выборку можно отображать не просто подмножество записей исходной таблицы, но и подмножество полей исходной таблицы) и в технологии последующей работы с результатом (над набором данных, как уже отмечалось, можно исполнить другой запрос). Различают запросы на выборку всех записей с произвольным набором полей и запросы на выборку подмножества записей. На рис. 4.9 приведен пример запроса, формирующего полный список сотрудников организации из таблицы «Сотрудники», но с сокращенным набором полей («Таб. №», «Фамилия», «Имя», «Отчество»), а также представлен вариант SQL-инструкции, реализующий данный запрос.
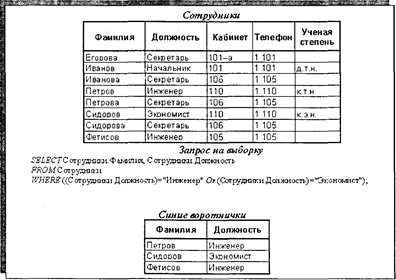
Рис 4.9. Пример запроса на выборку всех записей по группе полей В запросах на отбор подмножества записей в SQL-инструкции SELECT через предложение WHERE помещается выражение, определяющее условие отбора данных. На рис. 4.10 приведен пример реализации запроса на отбор подмножества записей из таблицы «Сотрудники» для сформирования списка работников инженерно-технического и экономического профиля.
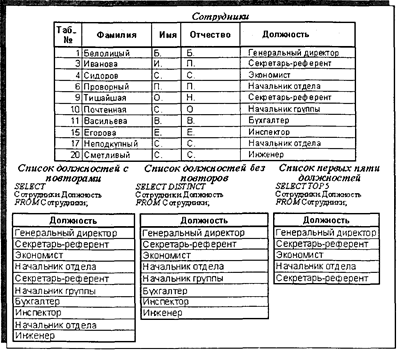
Рис. 4.10. Пример запроса на выборку подмножества записей В запросах на выборку данных широко применяются предикаты отбора ALL, DISTINCT, DISTINCTROW и TOPn. Предикат ALL используется по умолчанию и устанавливает вывод в наборе данных всех записей, формируемых по условию отбора, задаваемого предложением WHERE, и в большинстве случаев в инструкции SELECT опускается. Предикат DISTINCT используется для исключения в наборе отбираемых данных тех записей, значения которых по определенному полю повторяются, т. е. уже раз вошли в набор. На рис. 4.11 приведен пример запроса, отбирающего из таблицы «Сотрудники» данные по полю «Должность» без предиката отбора (т.е. с предикатом ALL) и с предикатом DISTINCT. В данном случае использование предиката DISTINCT позволяет сформировать простой список должностей без повторов.
Рис. 4.11. Пример запросов с предикатами ALL, DISTINCT и TOPn. Предикат DISTINCTROW имеет аналогичное предикату DISTINCT назначение для исключения из набора тех записей, значения которых повторяются по всем полям, включенным в набор данных. Предикат TOP n обеспечивает включение в набор данных первых п записей, сформированных по условию отбора. Пример запроса с предикатом ТОРп также приведен на рис. 4.11. В запросах на выборку помимо предложений FROM и WHERE используются предложения GROUP ВY, НАVING и ORDER ВY для дополнительной обработки отбираемых записей. Предложение GROUP ВY объединяет (группирует) записи с одинаковыми значениями определенных полей в одну запись. Предложение НАVING выполняет функцию предложения WHERE, позволяя задавать дополнительные условия для отбора сгруппированных предложением GRОUP BY записей. Предложение ORDER BY обеспечивает сортировку отобранных записей в зависимости от способа ASC (по возрастанию) или DESC (по убыванию). На рис. 4.12 приведен пример запроса, формирующего в порядке убывания список сгруппированных по полям «Категория» и «Профиль» записей из таблицы «Подразделения» при условии отбора подразделений с категорий выше третьей и отбора сгруппированных записей при условии основного профиля подразделений.
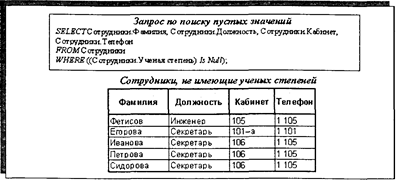
Рис. 4.12. Пример запроса на выборку данных с предложениями GROUP BY, HAVING и ORDER BY Определенную специфику имеет отбор записей с «пустыми» значениями определенных полей. В трактовке реляционных СУБД и языка SQL «пустых», т.е. неопределенных, значений полей не бывает. Иначе говоря, значением числового поля может быть число, равное «0», а значением других типов полей (текстовые, дата) может быть нулевое значение— «Null». Отбор записей с пустыми значениями может применяться для решения некоторых тематических и технологических задач, когда нужно отдельно сформировать и проанализировать набор данных с записями, содержащими нулевые для числовых полей, или не имеющие в силу каких-либо причин определенного значения, для других типов полей. На рис. 4.13 представлен пример запроса, отбирающего данные из таблицы «Сотрудники», приведенной на рис. 4.10, с «пустыми» значениями по полю «Ученая степень», иначе говоря, формирующий список сотрудников, не имеющих ученых степеней.
Рис. 4.13. Пример запроса по поиску данных с пустыми значениями определенного поля 4.3.2.1.2. Запросы на выборку данных из нескольких таблиц Запросы на выборку данных из нескольких таблиц, как правило, предназначены для решения логических информационных задач и, в свою очередь, подразделяются на три группы: • запросы на сочетание данных; • запросы на соединение данных; • запросы на объединение данных. Запросы на сочетание строятся на основе операции скалярного произведения реляционных таблиц и по смыслу направлены на формирование полного набора сочетании строк-записей, представленных в исходных таблицах. Запросы на сочетание строятся на основе SQL-инструкции SELECT и предложения FROM c пpoстым перечислением отбираемых полей и их таблиц. Для примера на рис. 4.14 приведен запрос на выборку сочетания данных из таблицы «Подразделения» и таблицы «Мероприятия». Формирование и исполнение такого запроса может быть обусловлено потребностями автоматического формирования новой таблицы для составления определенных планов или графиков, где нужно предусмотреть в исходном виде полный набор сочетаний данных по подразделениям и по мероприятиям.
Рис. 4.14. Пример реализации запроса на сочетание дачных из двух таблиц Запросы на соединение,* в свою очередь, подразделяются на запросы на основе внутреннего соединения(INNER JOIN) и запросы на основе правого или левого внешнего соединения (RIGHT JOINиLEFT JOIN). * В некоторых источниках данный тип запросов называют запросами на объединение (JOIN). Англ. термин JOIN переводится в глагольном виде как «объединяться», «соединяться», что и обусловливает неодинаковое его использование в русском переводе в разных источниках. В данном контексте более правильным является его перевод как «соединение», так как в реляционной модели данных операции «объединения» и «соединения» различны.
Запросы на выборку, строящиеся на основе внутреннего соединения, реализуют рассматриваемую по реляционной модели данных операцию соединения реляционных таблиц. Данная операция является одной из наиболее характерных и частых при решении логических информационных задач, когда нужно получить и просмотреть данные из разных таблиц, связанных определенной логикой или предварительно установленными в схеме базы данных связями. Напомним, что при реализации операции соединения двух таблиц выделяется поле соединения, которое должно быть одинакового типа в соединяемых таблицах. Результатом соединения таблиц является новая таблица, содержащая все поля, или часть полей первой таблицы и все или часть полей второй таблицы. Строки итоговой таблицы при внутреннем соединении образуются из сцепления строк первой и второй таблиц, когда их значения по соединяемому полю совпадают. Запросы на внешнее соединение строятся на основе модификации операции соединения. При левом внешнем соединении (LEFT JOIN) строки итоговой таблицы образуются из всех строк первой (левой) таблицы с «прицеплением» строк второй таблицы, если значения поля соединения совпадают. Если среди строк второй (правой) таблицы нет строк с соответствующим значением поля соединения, то в итоговой таблице присоединяемые поля заполняются пустыми значениями. При правом внешнем соединении (RIGHT JOIN) строки итоговой таблицы строятся по противоположному правилу. В большинстве случаев запросы на основе внутреннего соединения, по сути, являются процессом денормализации связанных таблиц, на которые база данных разделяется при проектировании, исходя из требований рационализации размещения данных. Запросы на соединение реализуются на основе включения в предложение FROM в качестве источника данных конструкции вида «имя_1-й_таблицы INNER (LEFT/RIGHT) JOIN имя_2-й_таблицы ON имя__поля_соединения_1-й_таблицы=имя_поля_соединения_2-й_таблицы». На рис. 4.15 приведен пример реализации операций внутреннего, а также левого и правого внешних соединений таблиц «Сотрудники» и «Исполнение» (документов) по полю «Фамилия». На рис. 4.15 приведены также варианты построения SQL-инструкций, для реализации соответствующих запросов. Как видно из рисунка, выбор типа соединения определяется целями дальнейшего использования результатов запроса.
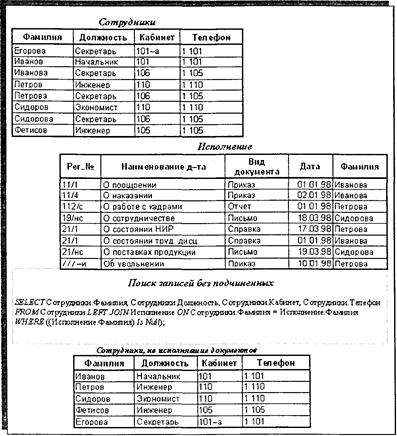
Рис. 4.15, а. Левое внешнее соединение При внутреннем соединении целью является получение новой таблицы с итоговыми данными по уже состоявшимся связям.
Рис. 4.15, в. Правое внешнее соединение Внешнее соединение по смыслу направлено на создание итоговой таблицы для просмотра и анализа состоявшихся и еще несостоявшихся связей. При этом для левого внешнего объединения упор делается на анализ связей от первой таблицы (в нашем случае от сотрудников, чтобы просмотреть и проанализировать, кто и какие документы исполнил, а кто вообще не исполнил ни одного документа). Иначе говоря, информация по связям служит в качестве дополнительного аспекта, дополнительной характеристики для записей левой таблицы. Для правого внешнего объединения упор делается на анализ связей от второй таблицы (в нашем случае от «Исполнения», чтобы просмотреть и проанализировать, какие документы исполнены и какими сотрудниками, записи о которых находятся в таблице «Сотрудники»). В некотором смысле антиподом запросов на соединение является специальный вид запросов на выборку, называемый запросом на поиск записей без подчиненных. Поиск записей без подчиненных применяется для анализа данных в связанных таблицах, когда связи в силу каких-либо причин не состоялись. Реализуется данный вид запроса на основе запроса на левое (правое) внешнее соединение с дополнительным условием отбора записей с пустыми значениями по полю соединения в правой (левой) таблице. По сути, запрос на поиск записей без подчиненных противоположен запросу на внутреннее соединение. Примером запроса по поиску записей без подчиненных, представленным на рис. 4.16, является запрос, строящий набор записей по таблице «Сотрудники», которые не исполнили ни одного документа, т. е. не имеют подчиненных записей в таблице «Исполнение». Запросы на соединение могут решать и более сложные логические информационные задачи по анализу связанных данных в цепочках из нескольких таблиц. В качестве примера такого рода запросов* можно привести следующий запрос по формированию набора записей сотрудников, командированных в январе 1998 г. в организации г. Саратова со служебным заданием «Сопровождение поставок», данные из которого выбираются из последовательно связанных отношением «Один-ко-многим» 4-х таблиц — «Сотрудники», «Командировки», «Пункт командирования», «Задания»: * В данном случае далеко не самого сложного.
SELECTCoтрудники* FRОМ ((Сотрудники INNER JOIN Командировки ON Сотрудники.ФИО = Командировки.ФИО) INNER JOIN Задания ON Командировки.Служебное задание = Задания.Наименование) INNER JOIN Пункт командирования ON Командировки. Пункт командирования = Пункт командирования. Наименование
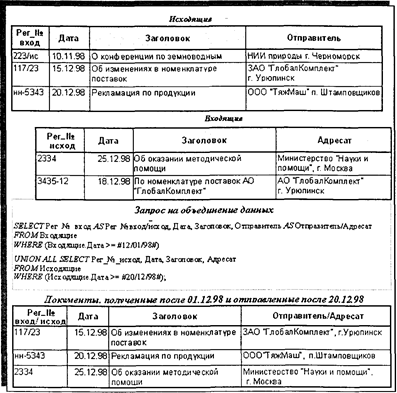
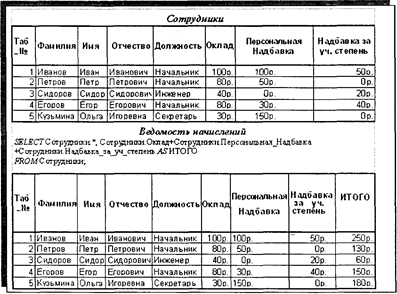
Рис. 4.16. Пример запроса по поиску записей без подчиненных WHERE ((Пункт командирования.Город) = «Саратов») AND ((Задания.Наименование) = «Сопровождение поставок») AND ((Командировки. Дата убытия) Between #1/1/98#Апd#1/31/98#); Запросы на объединение данных реализуют операцию объединения реляционных таблиц и решают задачи создания наборов данных, объединяющих однотипные по смыслу записи (по группам однотипных полей) из нескольких таблиц. Строятся запросы на объединение через SQL-инструкцию SELECT—UNION SELECT. При этом запрос состоит из первой инструкции SELECT, в которой перечисляются отбираемые поля и условия отбора записей из первой таблицы, и последующих инструкций UNION SELECT, в которых указываются отбираемые поля и условия отбора записей из других таблиц. Обязательным условием является одинаковое количество отбираемых полей в первой инструкции SELECT и последующих инструкциях UNION SELECT. При этом типы и длина полей в первой инструкции и последующих инструкциях могут не совпадать. При необходимости в итоговом наборе данных наименования отбираемых полей можно изменить через ключевое слово AS после соответствующего поля в первой инструкции SELECT. По умолчанию повторяющиеся записи не возвращаются, но через использование предиката ALL после ключевого слова UNION можно обеспечить режим отбора всех, в том числе и повторяющихся записей. На рис. 4.17 приведен пример отбора и объединения данных из таблиц «Исходящие» и «Входящие» базы «Документооборот» с целью формирования общего списка документов, поступивших после 1 декабря 1998 г., и документов, отправленных после 20 декабря 1998 г. В запросе первые и последние поля переименованы, чтобы объединить смысл этих полей в исходных таблицах. 4.3.2.1.3. Вычисления и групповые операции в запросах Во многих случаях при формировании набора данных по запросам на выборку требуется производить определенные вычисления или определенные операции по непосредственной обработке отбираемых данных. В реляционных СУБД такие возможности предоставляются через вычисляемые поля и групповые операции в запросах над отбираемыми данными. Вычисляемые поля. В инструкции SELECT в списке отбираемых полей добавляется выражение, по которому вычисляется новое поле, и посредством ключевого слова AS определяется его имя в формируемом наборе данных. На рис. 4.18 приведен запрос, формирующий ведомость начислений сотрудникам с вычисляемым полем «ИТОГО».
Рис. 4.17. Пример запроса на объединение Групповые операции. В процессе отбора и обработки данных важное значение имеют группирование данных по значениям какого-либо поля и осуществление тех или иных операций над сгруппированными записями. Групповые операции осуществляются на основе SQL-предложения GROUP BY в сочетании со статистическими функциями SQL. В большинстве диалектов языка SQL в состав инструкции SELECT допускается включение статистических функций SQL, которые осуществляют те или иные групповые вычислительные операции над отбираемыми записями. К числу статистических функций SQL относятся: SUM (выражение) — вычисляет сумму набора значений;
Рис. 4.18. Пример запроса на выборку с вычисляемым полем AVG (выражение) — вычисляет среднее арифметическое набора чисел; Min (выражение) — вычисляет минимальное значение из набора значений; Мах(выражение) — вычисляет максимальное значение из набора значений; StDev (выражение) — вычисляет среднеквадратичное отклонение набора значений; Count (выражение) — вычисляет количество записей, содержащихся в наборе; Var (выражение) — вычисляет дисперсию по набору значений. К числу функций, используемых в групповых операциях, относятся также функции First(выражение) и Last(выpaжeниe), вычисляющие (возвращающие), соответственно, первое и последнее значения поля в наборе данных. В выражениях в качестве аргумента допускается использование имен полей таблиц. Собственно сами групповые вычисления задаются посредством включения в SQL-инструкцию SELECT вычисляемого поля на основе выражения со статистическими функциями, выполняемыми над наборами данных, формируемыми предложением GROUP BY. Для примера на рис. 4.19 приведен запрос, формирующий итоговые данные по общей сумме премиальных каждого из премированных сотрудников. Группирование данных производится по полю «ФИО», т. е. все записи с одинаковыми значениями поля «ФИО», объединяются в одну и дополнительно формируется вычисляемое поле «ИТОГО», рассчитываемое как сумма сгруппированных в одну записей по произведению полей «Оклад» и «Премия».
Рис. 4.19. Пример запроса с групповой функцией Sum В некоторых СУБД в отдельный вид выделяются запросы по поиску повторов, а также вводится специальная разновидность запросов на выборку в виде так называемых перекрестных запросов. Запросы по поиску повторов применяются для анализа наличия повторяющихся групп значений по определенному полю и их количественных (статистических) данных. В качестве примера на рис. 4.20 приведен запрос по поиску повторов в таблице сотрудники по полю «Должность», формирующий в итоге штатную расстановку по заполненным должностям.
Рис. 4.20. Пример запроса по поиску повторяющихся значений Более сложные статистические задачи решают перекрестные запросы. Название «перекрестный» отражает принцип формирования и представления результатов таких запросов. На рис. 4.21 иллюстрируется принцип построения итоговой (сводной) таблицы перекрестного запроса. В исходной (базовой) таблице для перекрестного запроса выбираются два поля. По повторяющимся значениям одного поля формируются названия заголовков строк итоговой (сводной) таблицы — «боковик» сводной таблицы. По повторяющимся значениям другого поля образуются названия столбцов итоговой таблицы — «шапка» сводной таблицы. В ячейках сводной таблицы отражаются результаты статистических функций по группам данных в каких-либо полях исходной таблицы.
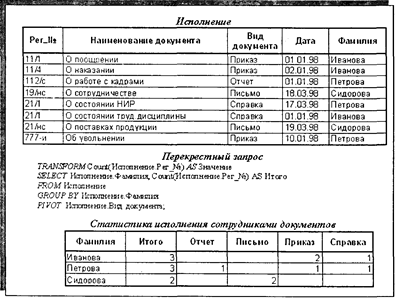
Рис. 4.21. Принцип формирования результатов перекрестного запроса Для примера на рис. 4.22 представлен запрос по формированию статистических данных о количестве исполненных различными сотрудниками документов с разнесением по видам документов. Полем для формирования боковика определено поле «Фамилия», полем для формирования шапки определено поле «Вид документа». На рисунке представлен также вариант SQL-инструкции, реализующей данный запрос.* * В диалекте SQL MS Access.
Рис. 4.22. Пример перекрестного запроса 4.3.2.2. Запросы на изменение данных Важное значение для решения различных технологических информационных задач по ведению базы данных имеют запросы на изменение данных. В отличие от непосредственного ввода данных в режимах открытой таблицы или формы они вносят изменения сразу в группу записей за одну операцию. Таким образом, результатом запросов на изменение является не набор данных, как в запросах на выборку, а изменение данных в самих таблицах. Запросы на изменение данных широко применяются для ввода данных при импорте из внешних источников, перемещения записей или их элементов из одних таблиц в другие таблицы, при массовой однотипной коррекции или чистке данных, а также для архивации и экспорта данных. Существует четыре разновидности запросов на изменение: • запросы на удаление; • запросы на обновление; • запросы на добавление; • запросы на создание таблицы. При исполнении запроса на удаление за одну операцию осуществляется удаление группы записей из одной или нескольких таблиц. Запросы на удаление реализуются SQL-инструкцией DELETE. К примеру, из таблицы «Клиенты» с помощью запроса на удаление можно за одну операцию удалить всех клиентов, проживающих в районе «Марьина Роща». SQL-инструкция такого запроса может выглядеть следующим образом: DELETE Kлиенты .*, Клиенты.Район FRОМ Клиенты WHERE ((Клиенты.Район) = «Марьина Роща»)); Удаление записей одним запросом из нескольких таблиц может осуществляться путем перечисления через запятую в соответствующей SQL-инструкции имен таблиц и имен полей, задающих условия удаления, или по связям между таблицами при установке ограничений целостности связей в режим «Каскадного удаления связанных записей». Запрос на обновление за одну операцию вносит общие изменения в группу записей одной или нескольких таблиц. Реализуются SQL-инструкцией UPDAТЕ. Запросы на обновления применяются тогда, когда необходимо осуществить глобальные однотипные изменения в каком-либо наборе данных. В качестве примера приведем ситуацию, когда в результате очередной деноминации (девальвации) всем сотрудникам необходимо в 10 раз уменьшить (увеличить) должностные оклады. Вариант SQL-инструкции, реализующей такой запрос, может выглядеть следующим образом: UPDAТЕ Сотрудники SET Сотрудники.Оклад=Оклад/10; В качестве другого примера приведем ситуацию, когда всех работников-совместителей учебного учреждения необходимо перевести в категорию почасовиков: UPDAТЕ Сотрудники SET Сотрудники.Статус=«Почасовик» WHERE ((Coтpyдники.Cтaтyc)=«Coвмecтитeль»); Обновление записей сразу в нескольких таблицах, также как и удаление, может осуществляться путем перечисления через запятую в инструкции UPDAТЕ имен таблиц, полей, их значений и соответствующих условий, а также по связям между таблицами с предварительной установкой ограничений целостности связей в режим «Каскадного обновления связанных записей». Запрос на добавление осуществляет добавление группы записей из одной или нескольких таблиц в конец другой или группы других таблиц. При этом количество и типы полей* при вставке записей должны совпадать. Запросы на добавление могут вставлять записи из текущей (открытой) базы данных в другую (внешнюю) базу данных. В этом случае запросы на добавление реализуют функции экспорта данных, решая задачи по обмену, архивации или резервированию данных. Однако чаще данные запросы применяются для добавления записей из одной таблицы базы данных в другую таблицу. * Не обязательно имена, но обязательно типы полей.
Запросы на добавление реализуются SQL-инструкцией INSERT INTO. Предположим, в базе данных имеются две таблицы «Студенты» и «Научные работники» с однотипным набором полей. Предположим также, что 100% студентов группы И-405 приняли участие в конкурсе научных студенческих работ и опубликовали свои труды в университетском сборнике. Тем самым, будучи еще студентами, они перешли в разряд научных работников. В этом случае запросом на добавление одной операцией в таблицу «Научные работники» можно добавить группу новых записей. Вариант SQL-инструкции, реализующей такой запрос, может иметь вид: INSERТ INTO НаучныеРаботники SELECT Cтуденты. * FRОМ Студенты WHERE ((Студенты.Группа)=«И-405»); Запросы на создание таблицы за одну операцию создают новую таблицу с заполненными данными на основе всех или части данных из одной или нескольких таблиц. Так же как и запросы на добавление, эти запросы чаще всего решают задачи по реформированию (реорганизации) базы данных, архивированию или резервированию данных, а также могут применяться для создания отчетов или состояний базы данных по определенным временным промежуткам. Реализуются SQL-инструкцией SELECT...INTO. Для примера приведем задачу создания специального набора (отчета) данных за месяц, скажем за январь, из таблицы «Заказы» в виде отдельной таблицы (для отдельного хранения или обработки). Вариант соответствующей SQL-инструкции может выглядеть следующим образом: SELECT Заказы * INTO Заказы Января FROM Заказы WHERE ((Заказы.Дата)= BETWEEN #1/01/ 98#AND #1/02/98 #; 4.3.2.3. Управляющие запросы В большинстве современных СУБД проектирование и создание таблиц осуществляются через специальные диалогово-наглядные конструкторы или пошаговые мастера. Тем не менее, как уже отмечалось, в составе языка описания данных DDL имеются ряд SQL-инструкций, на основе которых строятся запросы по созданию/модификации реляционных таблиц или отдельных их элементов. Такие запросы называются управляющими. Имеется четыре вида управляющих запросов: • запросы на создание таблицы;* • запросы на добавление в существующую таблицу нового поля или индекса; • запросы на удаление таблицы или индекса определенного поля таблицы; • запросы на создание индекса для поля или группы полей таблицы. * В отличие от одноименного запроса из группы запросов на изменение данный тип запроса не использует в качестве исходных данных другие уже существующие в базе данных таблицы, т. е. создает новую пустую таблицу.
Запросы на создание таблицы реализуются SQL-инструкцией CREAТЕ TABLE с ключевыми словами, определяющими типы полей (CHARACTER, INTEGER, DATETIME и т.д.), предложением CONSTRAINT для создания ограничений на значения полей или связей между таблицами, ключевым словом UNIQUE, задающим свойство уникальности (требование на отсутствие совпадений) индекса таблицы, а также ключевого слова PRIMARYKEY, определяющего ключевое поле создаваемой таблицы. В качестве примера приведем запрос на создание таблицы «Сотрудники» с полями «Фамилия», «Имя», «ДатаРождения», уникальным составным индексом «ИндексСотрудники» для полей «Фамилия», «Имя», «ДатаРождения», с тем же набором полей для составного ключа «КлючСотрудники».* * В стандартах SQL и в большинстве диалектов SQL символы кириллицы в названиях полей не допускаются.
CREAТЕ TABLE Cотрудники (Фамилия TEXT, Имя TEXT, ДатаРождения DA TETIME, CONSTRAINT ИндексCотрудники UNIQUE (Имя,Фамилия, ДатаРождения) КлючСотрудники PRIMARY KEY); Запросы на добавление полей или индексов реализуются SQL-инструкцией ALTER TABLE с использованием зарезервированных слов ADD COLUMN (добавить поле) и ADD CONSTRAINT (добавить индекс). Этим же запросом с помощью зарезервированного слова DROP COLUMN можно удалить поле из существующей таблицы. Как правило, запросы на добавление полей также используются для создания внешних ключей, задающих связи-отношения между таблицами. С этой целью используются зарезервированные слова FOREIGN KEY и REFERENCES.
|